

什么是OLAP,其与OLTP有什么区别?
如果展开来说,这个问题估计可以写好几篇文章,这里简单谈谈个人的理解。
OLTP是Online transaction processing的英文缩写,指在线/联机事务处理
OLAP是Online analytical processing的英文缩写,指联机分析处理
单次OLTP处理的数据量比较小,所涉及的表非常有限,一般仅一两张表。而OLAP是为了从大量的数据中找出某种规律性的东西,经常用到count()、sum()和avg()等聚合方法,用于了解现状并为将来的计划/决策提供数据支撑,所以对多张表的数据进行连接汇总非常普遍。
为了表示跟OLTP的数据库(database)在数据量和复杂度上的不同,一般称OLAP的操作对象为数据仓库(data warehouse),简称数仓
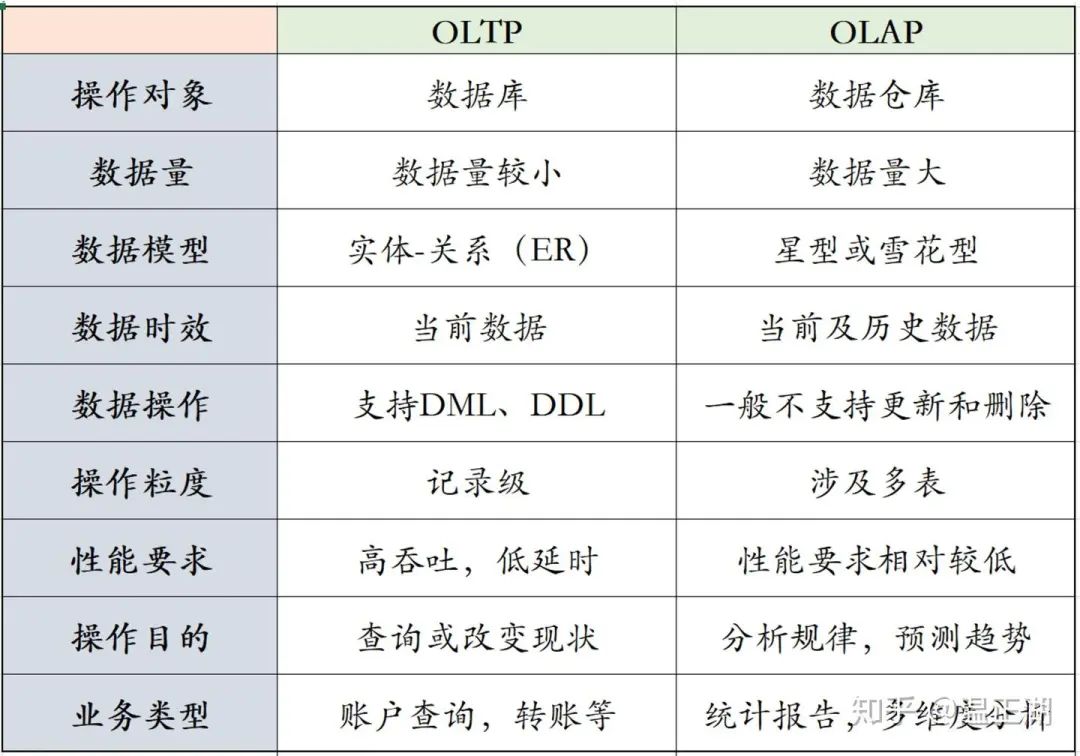
下表是对OLTP和OLAP的简单总结。
网易杭研OLTP数据库团队为业界培养了多位数据库资深专家,在线数仓团队也同样如此,在Impala、Kudu等技术上有深厚的积累,是网易猛犸、有数等网易大数据产品的核心基础设施。
MySQL等OLTP数据库能处理OLAP业务吗?
MySQL是当前最流行的开源数据库,一般作为OLTP数据库使用。在MySQL上也能执行一些OLAP操作,但这不是MySQL擅长的领域。虽然OLTP和OLAP都是通过SQL来执行,但SQL语句只是描述了我想要什么,而并没有说明应该怎么做(不考虑hint等),即确定最优的执行计划。由于OLTP操作比较简单,所涉及的表也少,因此不需要相应的数据库具有强大的执行优化能力,比如说MySQL在查询优化这块就比较弱,但这其实没有给它的大规模普及使用造成多大伤害。
当然,MySQL也在快速进步,尤其是最新的8.0版本,在查询优化模块添加了很多众望所归的功能特性,包括窗口函数,通用表达式和更强大的Join能力等。
而OLAP类操作不一样,没有强大的执行计划产生和优化能力,执行这类操作肯定不会有多高的效率,甚至会寸步难行。当然,如果总数据量较小,SQL也相对简单,那MySQL也是能够应付的。在MySQL高可用实例的从库做些报表类查询也有不少案例。
OLAP的查询跟OLTP查询具体有那些不一样?
上文简要提及,OLTP查询一般仅涉及单表,点查为主,返回的是记录本身或该记录的多个列。即使是范围查询,基本上也会通过limit来限制返回的记录数。
而OLAP则不同,表中单条记录本身并不是查询所关心的,比较典型的特点包括有聚合类算子、涉及多表Join,查询所用谓语/条件没有索引,玩玩不是返回记录。由于这些操作都非常耗计算资源,而且数据仓库相比数据库在数据量上大很多,因此,OLAP类查询经常表现为cpu-bound而不是io-bound。
对于OLTP来说,有sysbench和tpcc测试套件,对于OLAP来说,有tpch和tpcds 2种。这里分别例举sysbench oltp和tpcds的sql作为参考
sysbench oltp查询
可以从sysbench的lua脚本中获取都有哪些查询类型。如下所示:
对应到测试时,就是下面的样子。
感兴趣的同学可以查看github上sysbench代码。上述sql均位于oltp_common.lua中。
同样的,我们也可以从github上找到tpcc的查询sql。如下:
例子如下:
相对来说,tpcc的查询比oltp查询更复杂些。包含了2表join操作。
tpcds查询
下面在看看复杂的tpcds查询是怎么样的。tpcds一共99个query,下面举例。
很显然,tpcds的查询复杂度相比oltp和tpcc高非常多。
是否有可能将OLAP和OLTP统一起来?
目前有个趋势是将OLTP和OLAP相融合,在同一个系统中同时提供TP和AP 2种服务,即HTAP产品,国内的数据库创业公司PingCAP的TiDB即是其中的佼佼者。
但由于两者服务类型相差甚大,完全融合是很难的,如何解决AP业务对要求更高实时性和稳定性的TP业务带来影响,如何同时提供2种服务且2种服务与业界其他系统相比具备足够竞争力,这些都是很大的挑战。
在目前的HTAP系统中,一般通过存储层的数据多副本来进行针对AP和TP业务的不同方式的优化,使用多个副本来以行存方式更好满足TP业务,通过增加一个副本来以列存方式为AP业务提供服务。
在存储系统上,配置独立的计算/查询系统,分别满足TP和AP不同的要求。比如TP系统很重要的一个特点就是事务的ACID,而AP系统更加关心分布式并行查询能力。
TP和AP融合不是本系列文章关注焦点,因此下面我们聚焦到OLAP/数仓上来。
数仓有哪些基础知识和概念?
OLAP的查询语句比OLTP更复杂,显然是因为两则操作的数据集和目的都是不一样的。数据库模型是2维的关系-实体模型。而数仓则是多维立方体模型。相对来说,给数仓建模的难度更高。为此,有必要再介绍下输出基础知识和一些重要概念。
先来看看这张图,基于该图,介绍下数仓的数据来源,作用和存在方式。
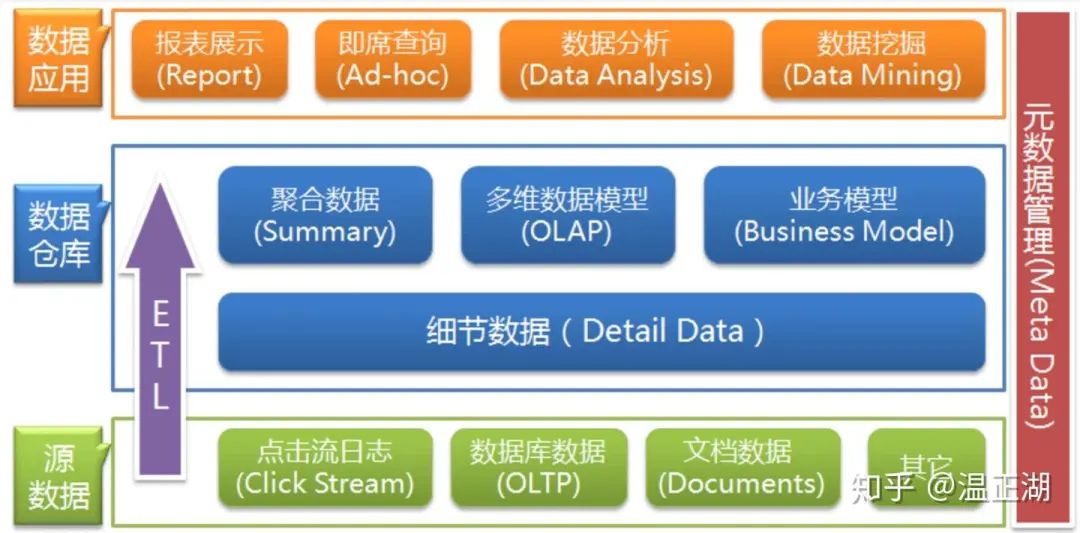
说说数仓中数据的前世今生?
数仓中的数据从何而来?
OLAP对应的数据载体叫做数据仓库,称之为仓库个人认为挺贴切的。因为它不是数据的生产者,其中的数据都是从其他地方搬运过来的,而搬运和清洗的过程就是ETL流程(Extract-Transform-Load,即数据抽取、转换和加载),在此不展开。
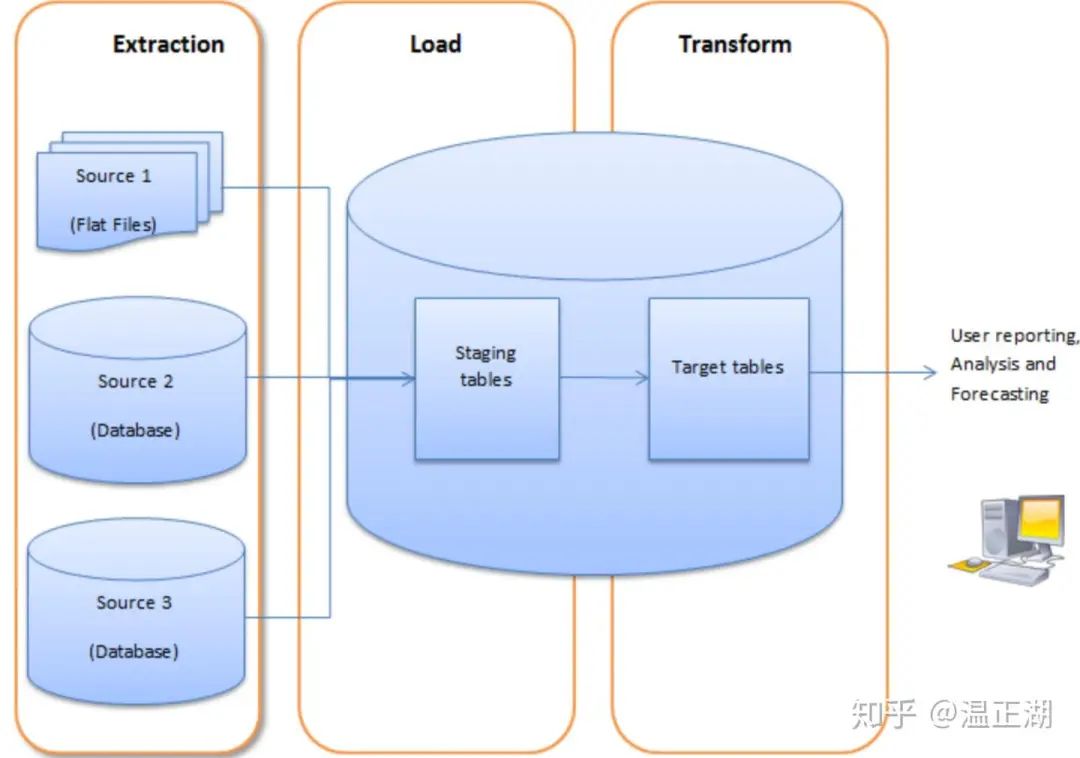
那么这些数据从何而来,表现形式如何呢? 归纳起来大体有3种:
结构化数据
半结构化数据
非结构化数据
数仓的作用有哪些?
数据仓库大致可以分为以下一些作用:
在数仓仓库之前可以部署至少如上所述4类数据应用。
数据在数仓中是如何组织的?
简单介绍了数仓的数据来源,数仓中数据所能发挥的作用后,接下来聊聊这些通过不同方式进来的数据,如何存在于数仓当中的。相应地引入多维数据模型和数据立方体(data cube)概念。数仓中数据的存在方式跟数仓索要发挥的作用息息相关,即该数仓要承载什么样的业务模型。
基于业务模型设计对应的数据仓库的数据模型,进而针对性实现不同的ETL操作将外部数据经过不同程度的过滤、聚合等处理之后引入到数仓之中。
什么是多维数据模型?
抽象的概念光通过文字描述是无法在大脑中具象化的,这是因为大自然存在的都是具体的事物,抽象的东西是竟然我们加工所得。为了更加清晰的进行说明,需要将抽象概念重新具体化。下面就通过例子来说明与数仓多维数据模型相关的概念,以便大家更好得建立初步的认识。
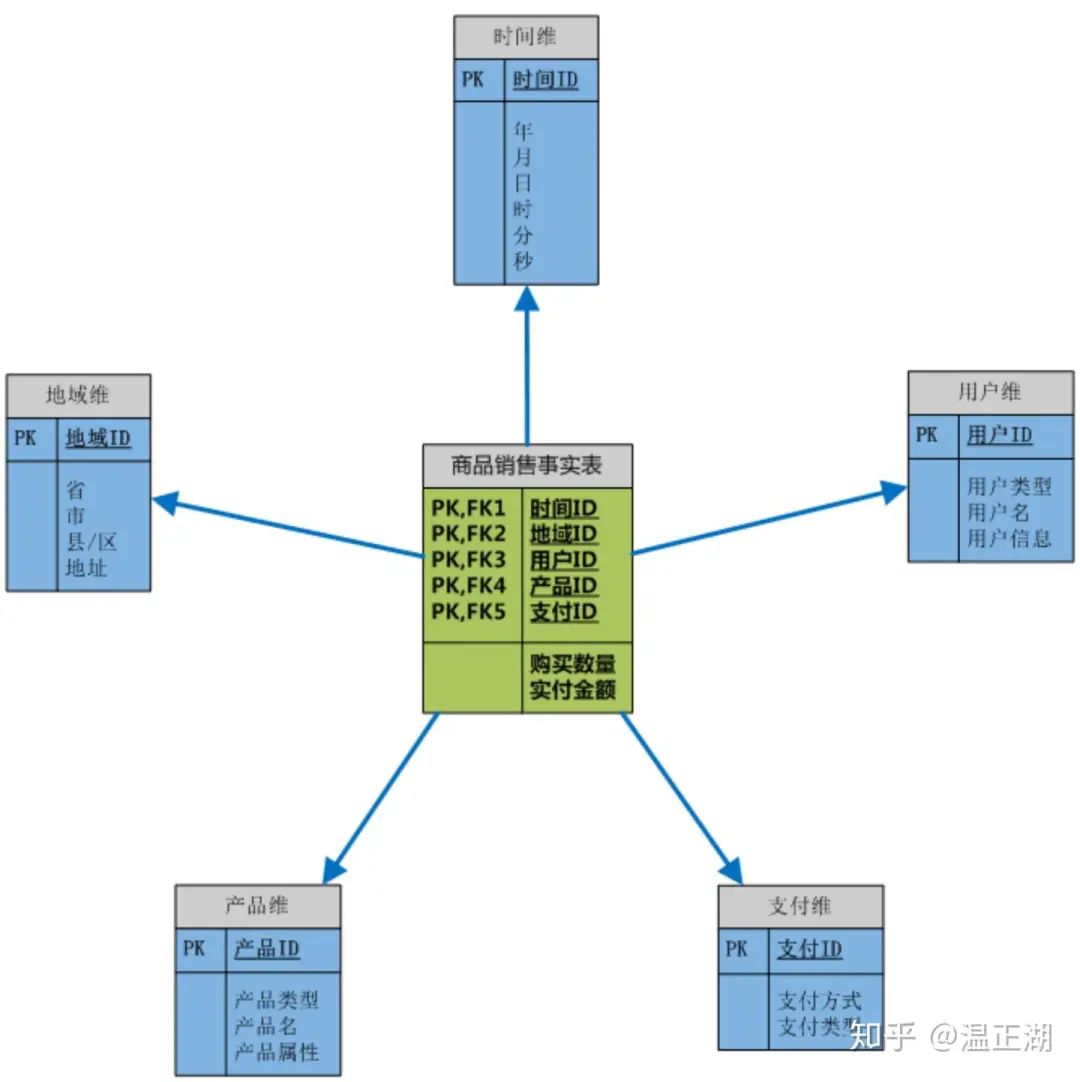
上图所示即为一个采用简单星型模型组织起来的多维数据模型,用来存储商品销售情况。在这张图中的6个表又可分为2种类型,分别是最中间的事实表,和围绕其展开的维度表。
什么是事实表?
事实表(Fact Table)用来记录具体事件,包含了每个事件的具体要素,以及具体发生的事情
什么是维度表?
维度表(Dimension Table )是依赖事实表而存在的每个维度表都是对事实表中的每个列/字段进行展开描述。
比如事实表中的用户ID,就可以进一步展开成一张维度表,记录该用户ID实体的用户名、联系信息、地址信息、年龄、性别和注册方式等等;
一般来说,对于数仓,事实表的增删改操作相比维度表更为频繁,模型建立后,维度表中的数据保持相对稳定。试想,商品销售行为是一直在发生的,而用户注册和产品更新不总是随时有的。再说到地域和支付方式,那就更少变化了。
通过事实表和维度表组织起来的数仓多维数据模型,相比原本分散在数据库等各处的数据,能够有更有目的更高效的查询效率,比如可以查询汇总地域维度中某个省的商品销售情况,也可以通过时间维度分析每个季度的某类商品销售趋势。将多个维度表跟事实表进行不同程度的连接,可以展开得到各种各样的分析结果,满足商品运营等数据使用者的不同需求。
基于数据模型及操作又可以引入数据立方体概念及对其的常见操作。
什么是数据立方体?
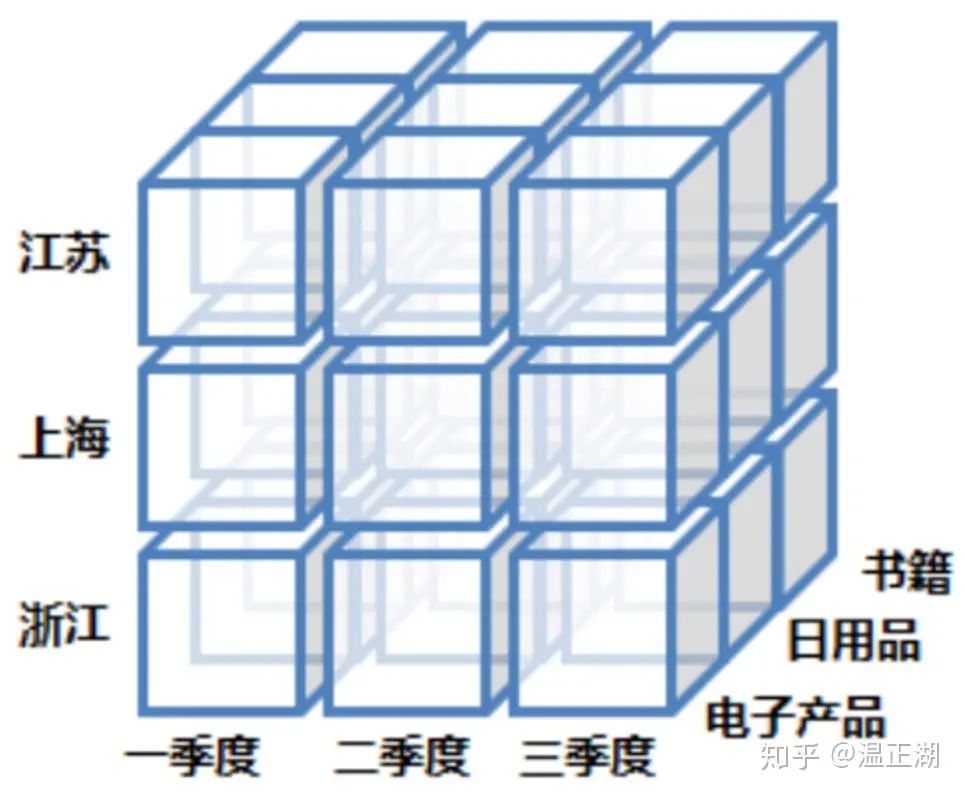
中国作为信息技术领域的后起之秀,我们现在介绍的这些概念都源于英文。数据立方体就是从英文“Data Cube”而来。下图就是一个商品销售模型的数据立方体。
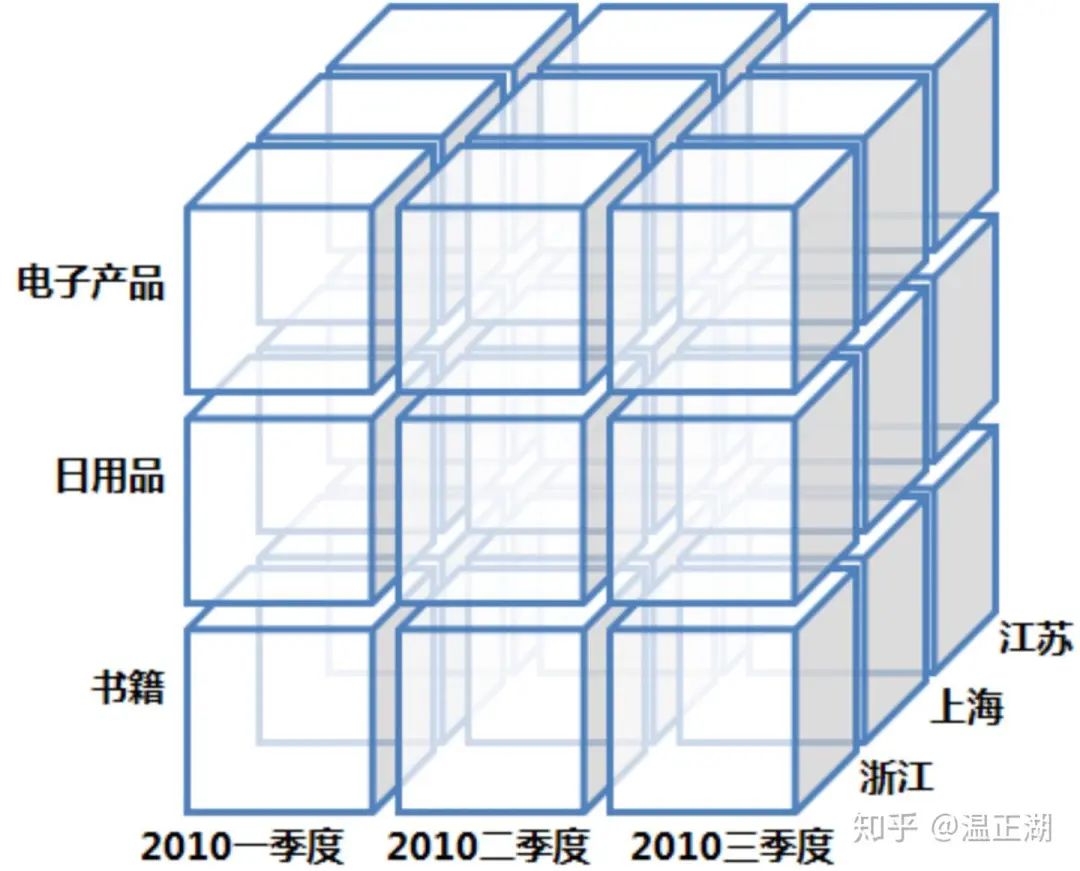
其实我们也可以叫它”数据魔方体“,因为立方体是三维的,而多维数据模型并不仅仅三维,虽然受图形化展示限制,一般仅展示其三个维度。而”魔方“一词,则凸现出了其变化性,通过对其进行不同的操作,让数据呈现出千变万化的结果。
上图来源于参考资料,比较好展示了多维模型,从大立方体上可以看到商品类型、季度和地区三个维度。但对于每个维度又是一个小立方体,比如第一季度浙江的书籍销售情况就是左下角的小立方体。在这个小立方体中,根据需要,我们还可以按照书籍类型,从季度拆分为月度,浙江拆出各地级市。
上面的拆分例子正是基于立方体的场景操作之一,下面进一步介绍。
数据立方体有哪些常见操作?
在进行OLAP查询时,基于数据立方体的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),接下来以上面的数据立方体为例来逐一解释下:
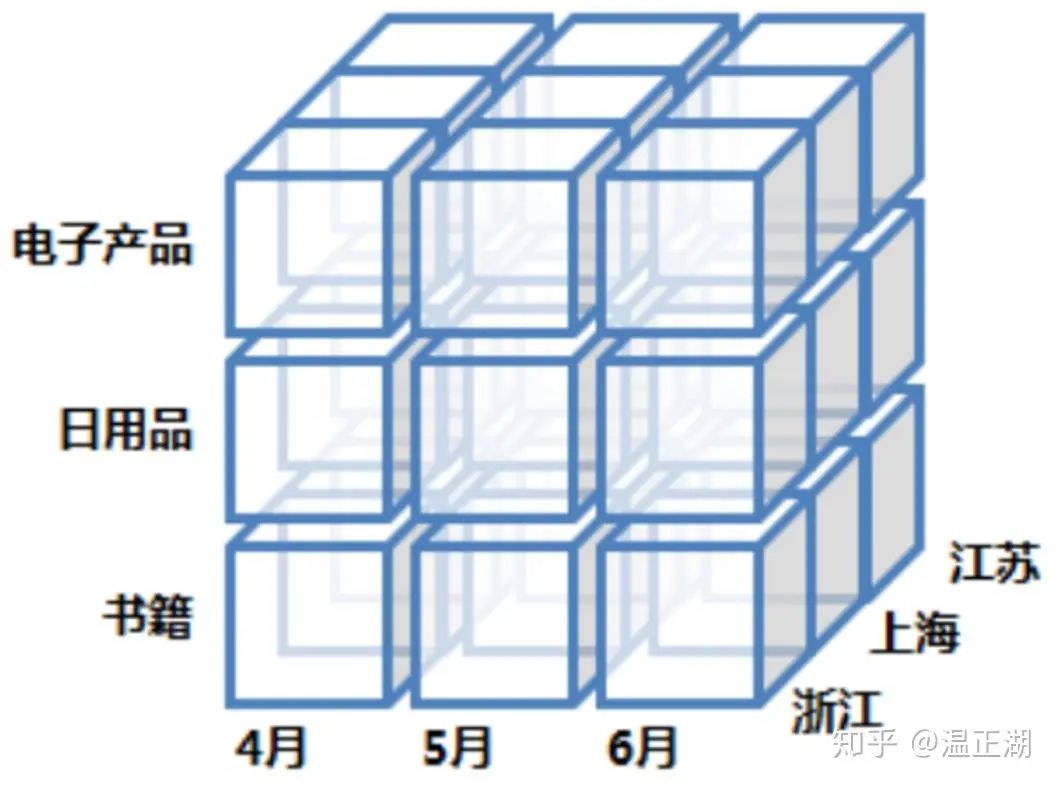
钻取(Drill-down)
该操作我们上面简单举过例子,从钻取这个名字,就可以知道,这是往更细粒度深挖。从上一个层次到下一层,即深入该层内部。比如书籍中可以分计算机、数理化、文史地等,二季度又可分为4、5、6三个月,浙江省又可以分为杭、甬、温等地级市的销售数据。
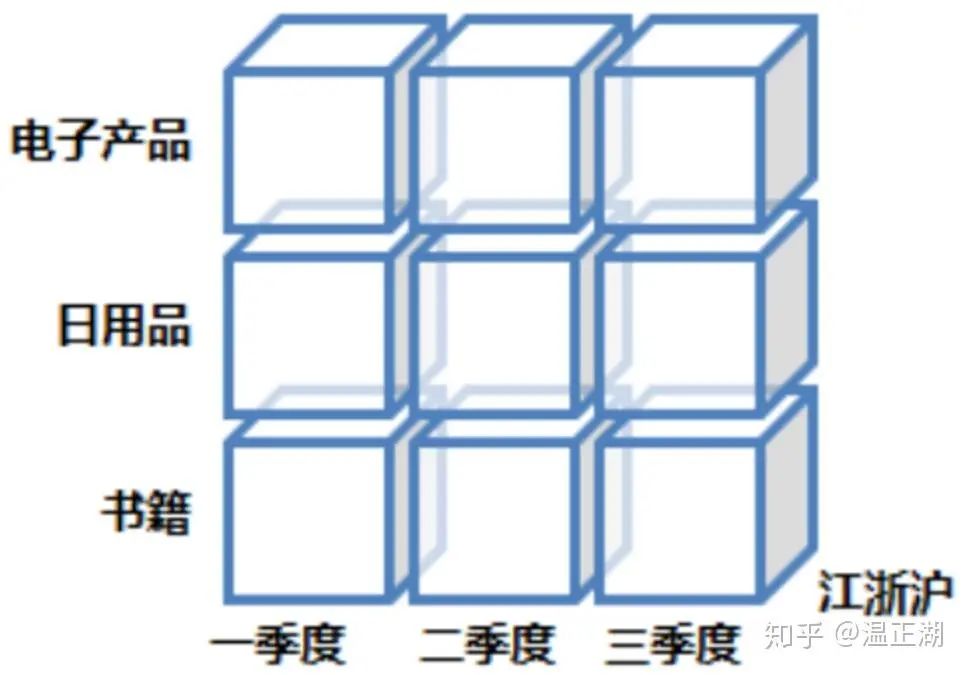
上卷(Roll-up):
与钻取往深度挖相反,上卷顾名思义,即从细粒度数据向上层聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,将2010年的四个季度汇总成2010年的总数据;将电子产品、日用品和书籍汇总成实体商品,与服务相对应。
上面的钻取和上卷通过摊薄和加厚来改变维度的粒度。接下来介绍的切片和切块相似,是对维度进行筛选,获取其中一部分相同的样本。
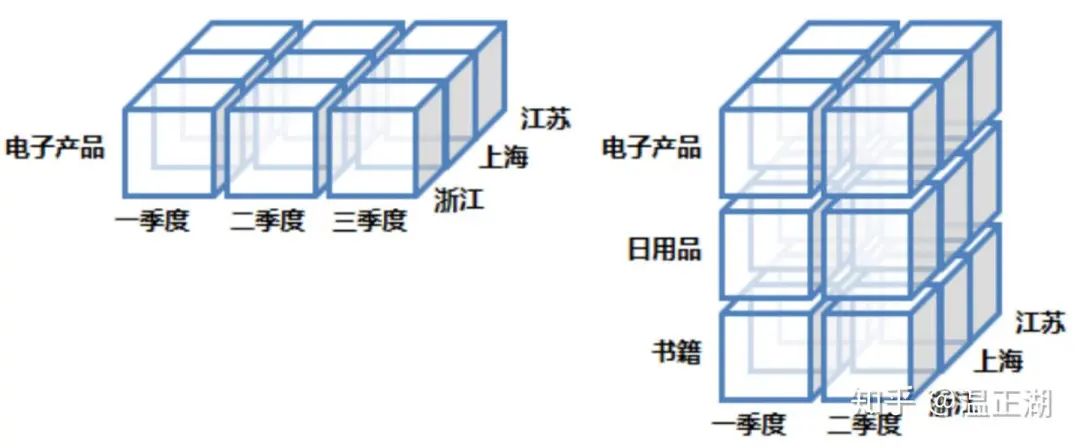
切片(Slice):
如左图所示,切片就是选择维中特定的值进行分析,比如只选择电子产品的销售数据,或2010年第二季度的数据,或浙江一个省粒度进行分析。
切块(Dice):
如右图所示,切块是选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
与切片不同的是,切块的粒度更大,会选择一个维度中某个区间或范围的值,而不仅仅是某个值。
旋转(Pivot):
即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
与上面几种操作不同,旋转并未减少或增加要分析的样本。而是根据不同的目的,改变了分析的角度,比如本来将产品作为观察角度,将地域和时间作为参照,分析不同产品在销售情况。通过旋转,转而分析江浙沪三个不同地区的产品销售情况。
以上仅简单介绍了数仓领域最最基础的知识和概念。下一篇重点分析现实中数仓的类型及其代表产品,并介绍优秀的数仓产品会用到的核心技术。
有哪些类型的OLAP数仓?
按数据量划分
对一件事物或一个东西基于不同角度,可以进行多种分类方式。对数仓产品也一样。比如我们可以基于数据量来选择不同类型的数量,如下图所示:
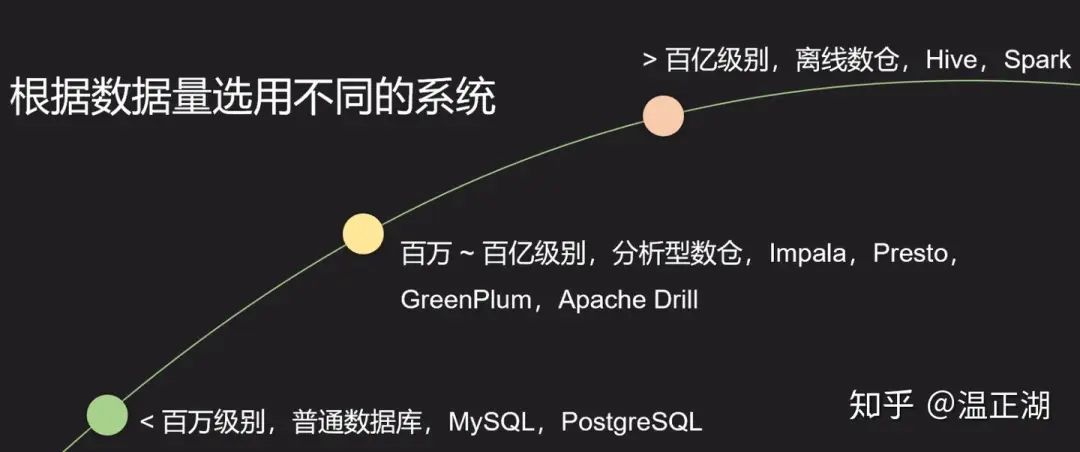
本系列文章主要关注的是数据量处于百万到百亿级别的偏实时的分析型数仓,Cloudera的Impala、Facebook的Presto和Pivotal的GreenPlum均属于这类系统;如果超过百亿级别数据量,那么一般选择离线数仓,如使用Hive或Spark等(SparkSQL3.0看起来性能提升很明显);对于数据量很小的情况,虽然是分析类应用,也可以直接选择普通的关系型数据库,比如MySQL等,“杀鸡焉用牛刀”。
这些系统均属于网易杭研大数据和数据库团队的研究范畴,对各系统均有深入研究和优化,对外提供网易猛犸、网易有数和网易云RDS等服务。
按建模类型划分
下面我们主要关注数据量中等的分析型数仓,聚焦OLAP系统。 根据维基百科对OLAP的介绍,一般来说OLAP根据建模方式可分为MOLAP、ROLAP和HOLAP 3种类型,下面分别进行介绍并分析优缺点。
MOLAP
这应该算是最传统的数仓了,1993年Edgar F. Codd提出OLAP概念时,指的就是MOLAP数仓,M即表示多维(Multidimensional)。大多数MOLAP产品均对原始数据进行预计算得到用户可能需要的所有结果,将其存储到优化过的多维数组存储中,可以认为这就是上一篇所提到的“数据立方体”。
由于所有可能结果均已计算出来并持久化存储,查询时无需进行复杂计算,且以数组形式可以进行高效的免索引数据访问,因此用户发起的查询均能够稳定地快速响应。这些结果集是高度结构化的,可以进行压缩/编码来减少存储占用空间。
但高性能并不是没有代价的。首先,MOLAP需要进行预计算,这会花去很多时间。如果每次写入增量数据后均要进行全量预计算,显然是低效率的,因此支持仅对增量数据进行迭代计算非常重要。其次,如果业务发生需求变更,需要进行预定模型之外新的查询操作,现有的MOLAP实例就无能为力了,只能重新进行建模和预计算。
MOLAP适合业务需求比较固定,数据量较大的场景

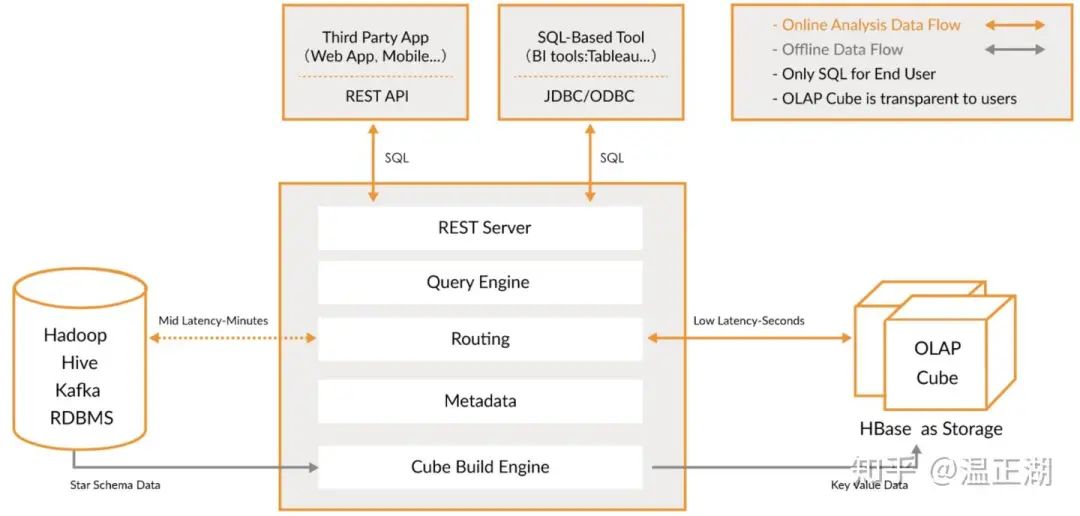
其架构图较直观得反映了基于cube的预计算模型(build),如下所示:
ROLAP
与MOLAP相反,ROLAP无需预计算,直接在构成多维数据模型的事实表和维度表上进行计算。R即表示关系型(Relational)。显然,这种方式相比MOLAP更具可扩展性,增量数据导入后,无需进行重新计算,用户有新的查询需求时只需写好正确的SQL语句既能完成获取所需的结果。
但ROLAP的不足也很明显,尤其是在数据体量巨大的场景下,用户提交SQL后,获取查询结果所需的时间无法准确预知,可能秒回,也可能需要花费数十分钟甚至数小时。本质上,ROLAP是把MOLAP预计算所需的时间分摊到了用户的每次查询上,肯定会影响用户的查询体验。
当然ROLAP的性能是否能够接受,取决于用户查询的SQL类型,数据规模以及用户对性能的预期。对于相对简单的SQL,比如TPCH中的Query响应时间较快。但如果是复杂SQL,比如TPC-DS中的数据分析和挖掘类的Query,可能需要数分钟。
相比MOLAP,ROLAP的使用门槛更低,在完成星型或雪花型模型的构建,创建对应schema的事实表和维度表并导入数据后,用户只需会写出符合需求的SQL,就可以得到想要的结果。相比创建“数据立方体”,显然更加方便。
ROLAP的性能比如MOLAP,但由于其灵活性、扩展性,ROLAP的使用者是MOLAP的数倍
The survey shows that ROLAP tools have 7 times more users than MOLAP tools within each company
HOLAP
MOLAP和ROLAP各有优缺点,而且是互斥的。如果能够将两者的优点进行互补,那么是个更好的选择。而HOLAP的出现就是这个目的,H表示混合型(Hybrid),这个想法很朴素直接。对于查询频繁而稳定但又耗时的那些SQL,通过预计算来提速;对于较快的查询、发生次数较少或新的查询需求,像ROLAP一样直接通过SQL操作事实表和维度表。
目前似乎没有开源的OLAP系统属于这个类型,一些大数据服务公司或互联网厂商,比如HULU有类似的产品。相信未来HOLAP可能会得到进一步发展,并获得更大规模的使用。
HTAP
从另一个维度看,HTAP也算是一种OLAP类型的系统,是ROLAP的一个扩展,具备了OLAP的能力。最新发展显示,有云厂商在HTAP的基础上做了某种妥协,将T(transaction)弱化为S(Serving),朝HSAP方向演进。关于HTAP/HSAP,本文不做进一步展开,可自主查询其他资料。
主流的OLAP数仓系统很多,包含上面所述的各种类型,下图是Gartner 2019 年发布的数据分析市场排名
可以发现,传统的商业厂商和闭源的云服务厂商占据了绝大部分市场。大部分系统笔者只听过而没有研究过。作为屁股在互联网公司的数据库/数据仓库开发者,本文后续主要聚焦在基于Hadoop生态发展的开源OLAP系统(SQL on Hadoop)。
有哪些常用的开源ROLAP产品?
目前生产环境使用较多的开源ROLAP主要可以分为2大类,一个是宽表模型,另一个是多表组合模型(就是前述的星型或雪花型)。
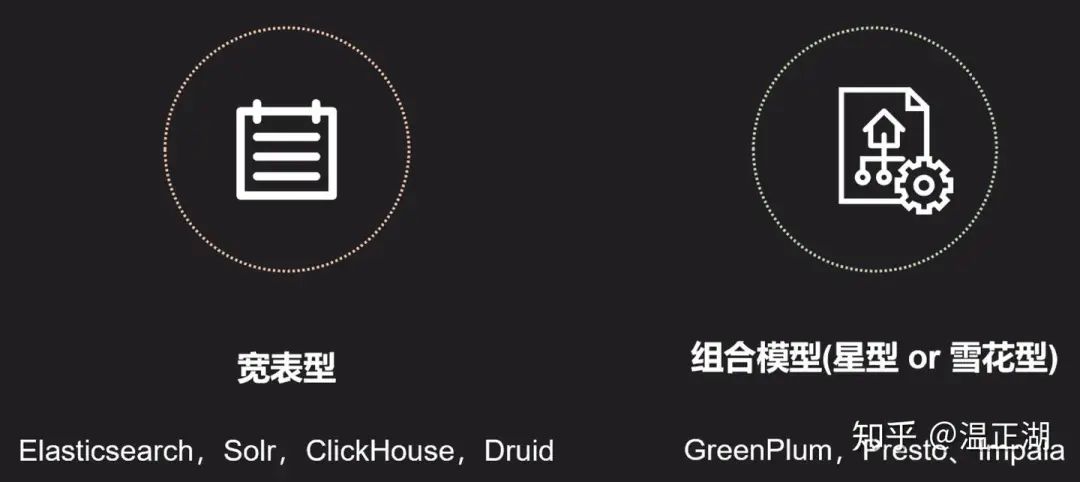
宽表模型
宽表模型能够提供比多表组合模型更好的查询性能,不足的是支持的SQL操作类型比较有限,比如对Join等复杂操作支持较弱或不支持。
Druid和ClickHouse
ElasticSearch和Solar
多表组合模型
采用星型或雪花型建模是最通用的一种ROLAP系统,常见的包括GreenPlum、Presto和Impala等,他们均基于MPP架构,采用该模型和架构的系统具有支持的数据量大、扩展性较好、灵活易用和支持的SQL类型多样等优点。
相比其他类型ROLAP和MOLAP,该类系统性能不具有优势,实时性较一般。通用系统往往比专用系统更难实现和进行优化,这是因为通用系统需要考虑的场景更多,支持的查询类型更丰富。而专用系统只需要针对所服务的某个特定场景进行优化即可,相对复杂度会有所降低。
对于ROLAP系统,尤其是星型或雪花型的系统,如果能够尽可能得缩短响应时间非常重要,这将是该系统的核心竞争力。这块内容,我们放在下一节着重进行介绍。
有哪些黑科技用于优化ROLAP系统性能?
目前生产环境使用的ROLAP系统,均实现了大部分的该领域性能优化技术,包括采用MPP架构、支持基于代价的查询优化(CBO)、向量化执行引擎、动态代码生成机制、存储空间和访问效率优化、其他cpu和内存相关的计算层优化等。下面逐一进行介绍。
什么是MPP架构?
首先来聊聊系统架构,这是设计OLAP系统的第一次分野,目前生产环境中系统采用的架构包括基于传统的MapReduce架构加上SQL层组装的系统;主流的基于MPP的系统;其他非MPP系统等。
MR架构及其局限
在Hadoop生态下,最早在Hive上提供了基于MapReduce框架的SQL查询服务。
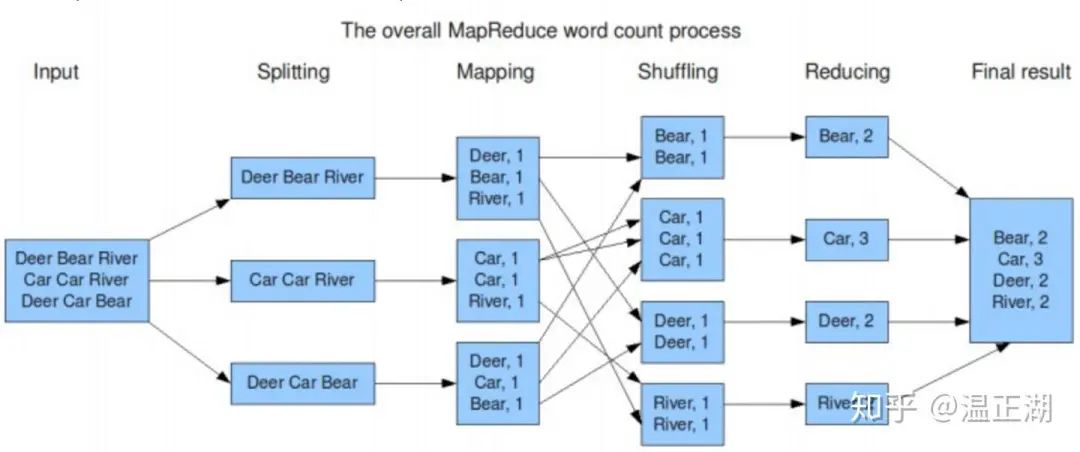
但基于MR框架局限性明显,比如:
每个MapReduce 操作都是相互独立的,Hadoop不知道接下来会有哪些MapReduce。
每一步的输出结果,都会持久化到硬盘或者HDFS 上。
第一个问题导致无法进行跨MR操作间的优化,第二个问题导致MR间数据交互需要大量的IO操作。两个问题均对执行效率产生很大影响,性能较差。
MPP优缺点分析
MPP是massively parallel processing的简称,即大规模并行计算框架。相比MR等架构,MPP查询速度快,通常在秒计甚至毫秒级以内就可以返回查询结果,这也是为何很多强调低延迟的系统,比如OLAP系统大多采用MPP架构的原因。
下面以Impala为例,简单介绍下MPP系统架构。
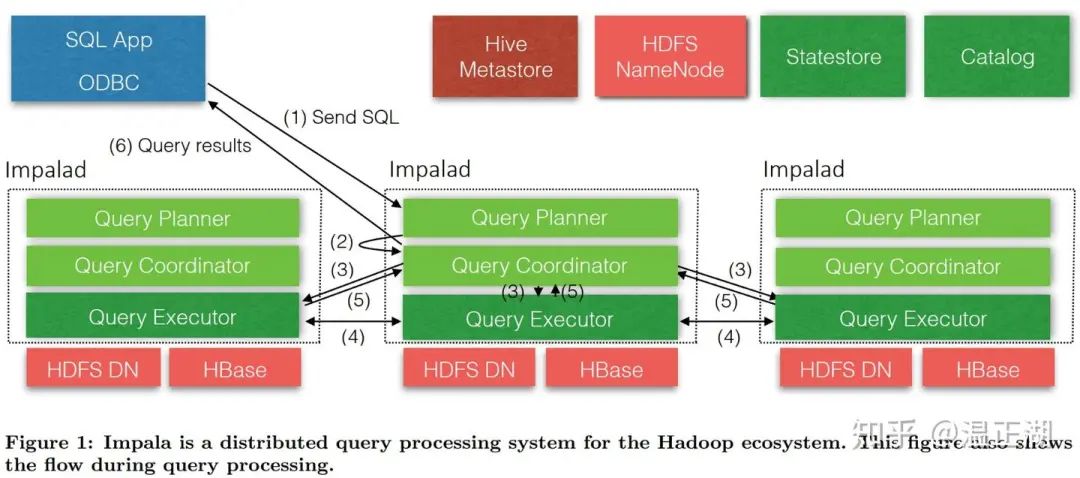
上图即为Impala架构图,展示了Impala各个组件及一个查询的执行流程。
MPP架构之所以性能比MR好,原因包括:
PF之间的数据交互(即中间处理结果)驻留在内存Buffer中不落盘(假设内存够大);
Operator和PF间基于流水线处理,不需要等上一个Operator/PF都完成后才进行下一个处理。上下游之间的关系和数据交互式预先明确的。
这样可以充分利用CPU资源,减少IO资源消耗。但事情往往是两面的,MPP并不完美,主要问题包括:
中间结果不落盘,在正常情况下是利好,但在异常情况下就是利空,这意味着出现节点宕机等场景下,需要重新计算产生中间结果,拖慢任务完成时间;
扩展性没有MR等架构好,或者说随着MPP系统节点增多到一定规模,性能无法线性提升。有个原因是“木桶效应”,系统性能瓶颈取决于性能最差的那个节点。另一个原因是规模越大,出现节点宕机、坏盘等异常情况就会越频繁,故障率提高会导致SQL重试概率提升;
基于上述分析,MPP比较适合执行时间不会太久的业务场景,比如数小时。因为时间越久,故障概率越大。
其他非MPP架构
基于MR系统局限性考虑,除了采用MPP架构外,Hive和Spark均使用不同方式进行了优化,包括Hive的Tez,SparkSQL基于DAG(Directed Acyclic Graph)等。
不同架构有不同优缺点,重要的是找到其适用的场景,并进行靠谱地优化,充分发挥其优势。
什么是基于代价的查询优化?
有了适合的系统架构并不一定能够带来正向收益,“好马配好鞍”,执行计划的好坏对最终系统的性能也有着决定性作用。执行计划及其优化,就笔者的理解来说,其来源于关系型数据库领域。这又是一门大学问,这里仅简单介绍。
分布式架构使得执行计划能够进行跨节点的并行优化,通过任务粒度拆分、串行变并行等方式大大缩短执行时间。除此之外,还有2个更重要的优化方式,就是传统的基于规则优化以及更高级的基于代价优化。
基于规则优化
通俗来说,基于规则的优化(rule based optimization,RBO)指的是不需要额外的信息,通过用户下发的SQL语句进行的优化,主要通过改下SQL,比如SQL子句的前后执行顺序等。比较常见的优化包括谓语下推、字段过滤下推、常量折叠、索引选择、Join优化等等。
谓语下推,即PredicatePushDown
字段过滤下推,即ProjectionPushDown
常量或函数折叠
Join优化
基于代价优化
基于规则的优化器简单,易于实现,通过内置的一组规则来决定如何执行查询计划。与之相对的是基于代价优化(cost based optimization,CBO)。
CBO的实现依赖于详细可靠的统计信息,比如每个列的最大值、最小值、平均值、区分度、记录数、列总和,表大小分区信息,以及列的直方图等元数据信息。
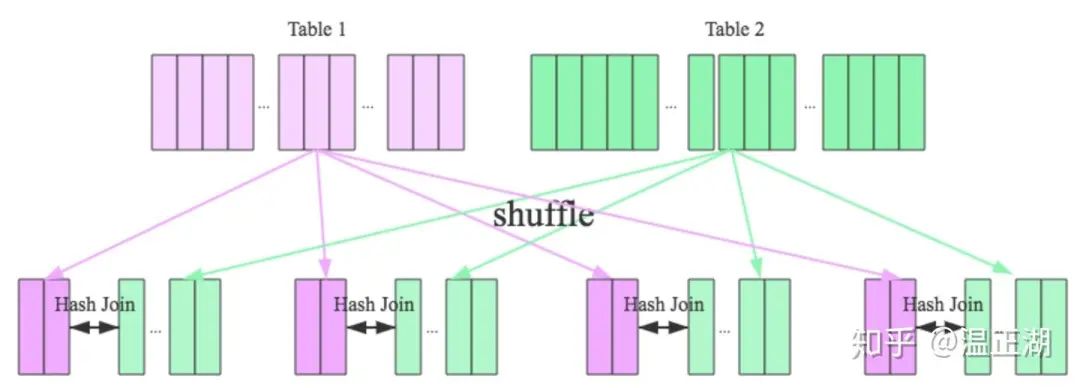
CBO的一大用途是在Join场景,决定Join的执行方式和Join的顺序。这里所说的Join我们主要是讨论Hash Join。
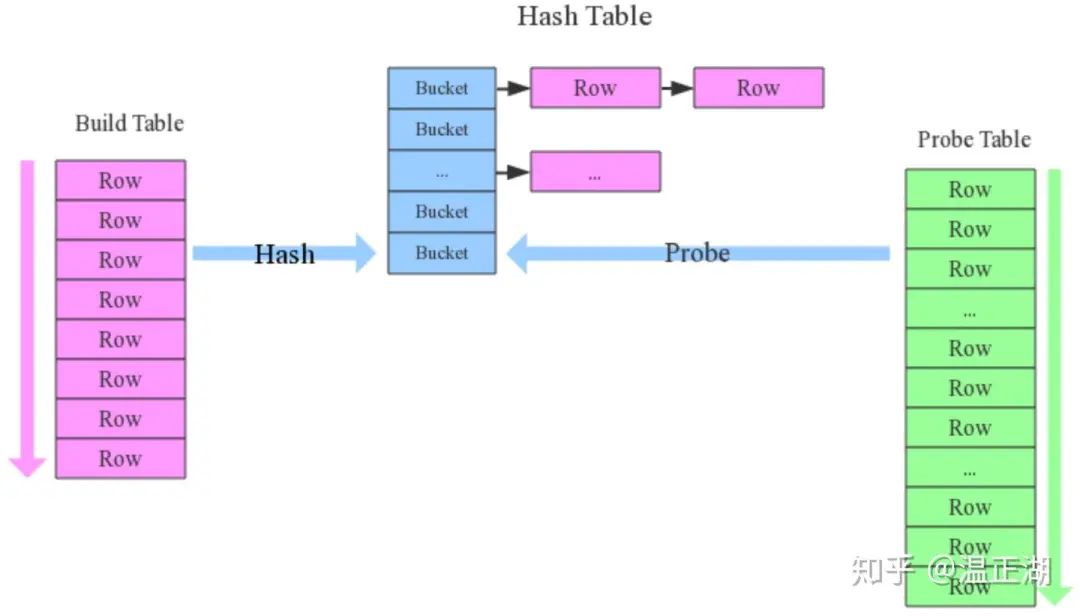
Join执行方式
驱动表(Build Table)和被驱动表(Probe Table)
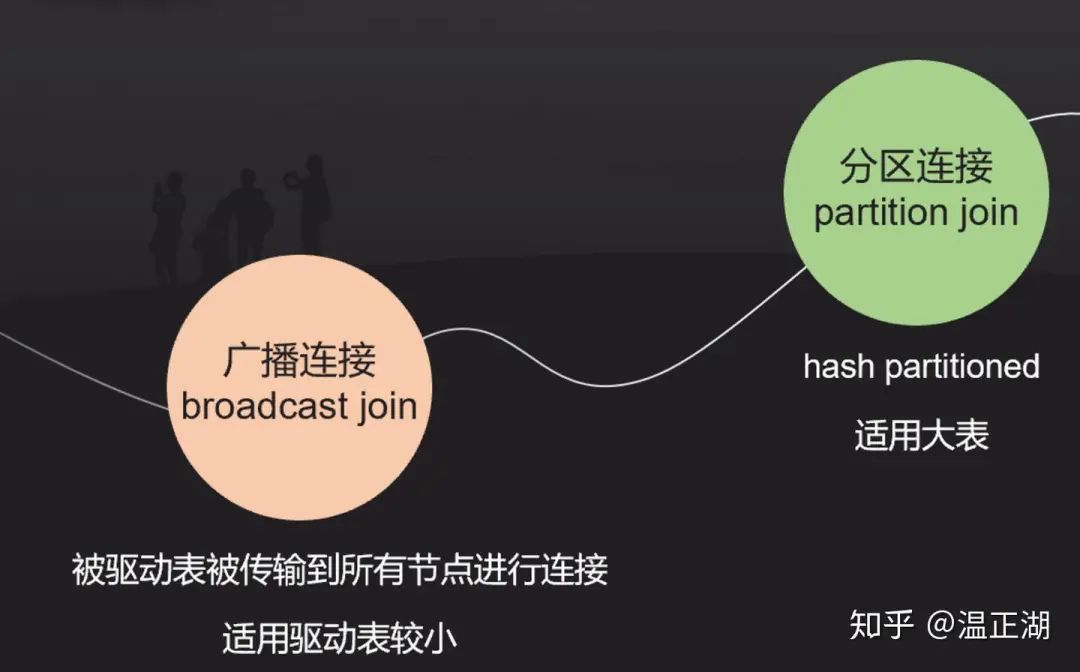
广播方式
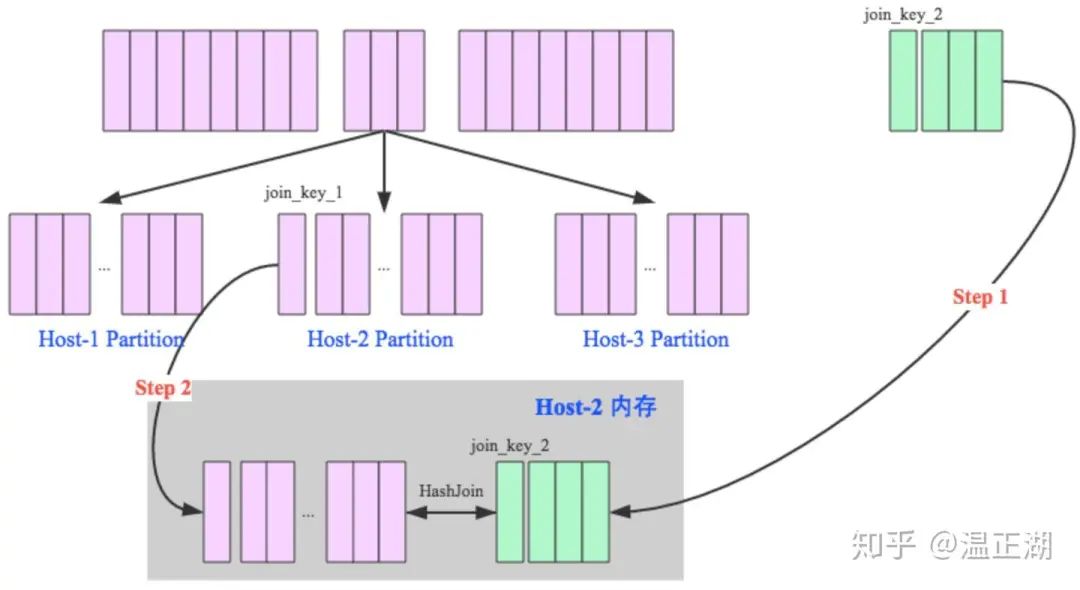
分区方式
显然,判断大小表的关键就看是否能够通过某种方式获取表的记录数,如果存储层保存了记录数,那么可从元数据中直接获取。
如果Join的两表都是大表,但至少有个表是带Where过滤条件的,那么在决定走分区方式前还可进一步看满足条件的记录数,这时候,物理上进行分区的表存储方式可发挥作用,可以看每个分区的最大值和最小值及其记录数来估算过滤后的总记录数。当然,还有种更精确的方式是列直方图,能够直接而直观得获取总记录数。
如果上述的统计信息都没有,要使用CBO还有另一种方式就是进行记录的动态采样来决定走那种Join方式。
Join顺序
如果一个查询的SQL中存在多层Join操作,如何决定Join的顺序对性能有很大影响。这块也已是被数据库大佬们充分研究过的技术。
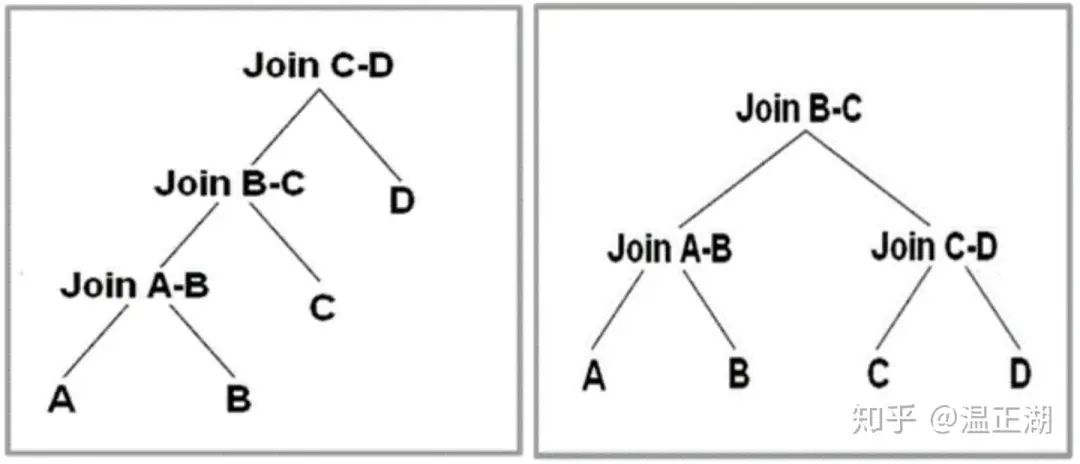
Left-deep treebushy tree
两种Join顺序没有好坏之分,关键看进行Join的表数据即Join的字段特点。
对于LDT,如果每次Join均能够过滤掉大量数据,那么从资源消耗来看,显然是更优的。对于给每个列都构建了索引的某些系统,使用LDT相比BYT更好。
一般来说,选择BYT是效率更高的模式,通过串行多层Join改为并行的更少层次Join,可以发挥MPP架构的优势,尽快得到结果,在多表模式ROLAP场景常采用。
为什么需要向量化执行引擎?其与动态代码生成有何关系?
查询执行引擎 (query execution engine)
什么原因导致这么大的差别呢?首先得简单说下火山模型的执行引擎。
火山模型及其缺点
火山模型(Volcano-style execution)是最早的查询执行引擎
下图描述了“select sum(C1) from T1 where C2 > 15”的查询计划,该查询计划包含Project,HashAgg,Scan等operator,每个 operator的next方法递归调用子节点的 next,一直递归调用到叶子节点Scan operator,Scan operator的next 从文件中返回一个元组。
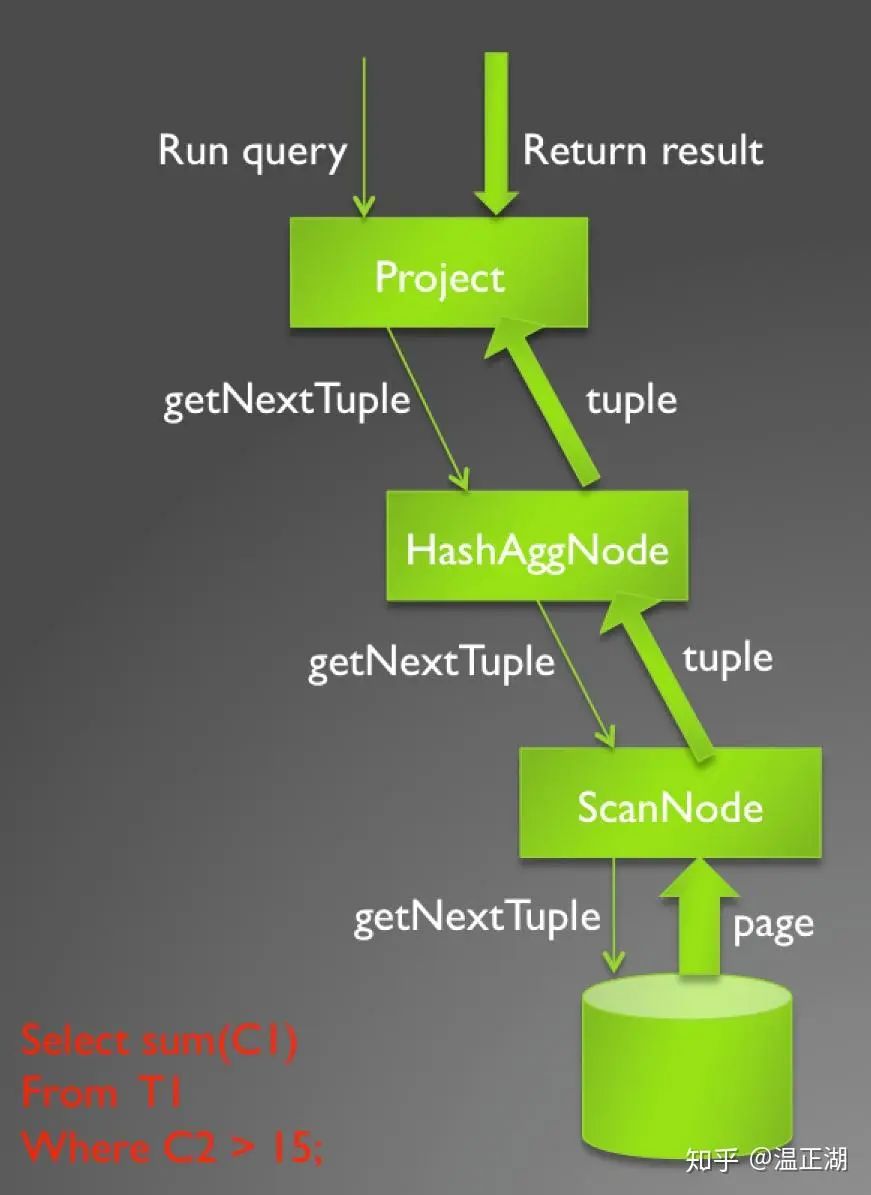
其缺点主要在于:
大量虚函数调用
类型装箱
CPU Cache利用效率低
条件分支预测失败
CPU与IO性能不匹配
通过上述描述,可以得出解决问题的基本方法。可以将问题分为2大类,分别用下述的向量化引擎和动态代码生成技术来解决。
向量化执行引擎
向量化执行以列存为前提,主要思想是每次从磁盘上读取一批列,这些列以数组形式组织。每次next都通过for循环处理列数组。这么做可以大幅减少next的调用次数。相应的CPU的利用率得到了提高,另外数据被组织在一起。可以进一步利用CPU硬件的特性,如SIMD,将所有数据加载到CPU的缓存当中去,提高缓存命中率,提升效率。在列存储与向量化执行引擎的双重优化下,查询执行的速度会有一个非常巨大的飞跃。
动态代码生成
向量化执行减少CPU等待时间,提高CPU Cache命中率,通过减少next调用次数来缓解虚函数调用效率问题。而动态代码生成,则是进一步解决了虚函数调用问题。
动态代码生成技术不使用解释性的统一代码,而是直接生成对应的执行语言的代码并直接用primitive type。对于判断数据类型造成的分支判断,动态代码的效果可以消除这些类型判断,使用硬件指令来进一步提高循环处理效率。
具体实现来说,JVM系如Spark SQL,Presto可以用反射,C++系的Impala则使用了llvm生成中间码。相对来说,C++的效率更高。
向量化和动态代码生成技术往往是一起工作达到更好的效果。
都有哪些存储空间和访问效率优化方法?
存储和IO模块的优化方法很多,这里我们还是在Hadoop生态下来考虑,当然,很多优化方法不是Hadoop特有的,而是通用的。OLAP场景下,数据存储最基础而有效的优化是该行存储为列存储,下面讨论的优化措施均基于列存。
数据压缩和编码
数据压缩是存储领域常用的优化手段,以可控的CPU开销来大幅缩小数据在磁盘上的存储空间,一来可以节省成本,二来可以减小IO和数据在内存中跨线程和跨节点网络传输的开销。目前在用的主流压缩算法包括zlib、snappy和lz4等。压缩算法并不是压缩比越高越好,压缩率越高的算法压缩和解压缩速度往往就越慢,需要根据硬件配置和使用场景在cpu 和io之间进行权衡。
RLE和数据字典编码
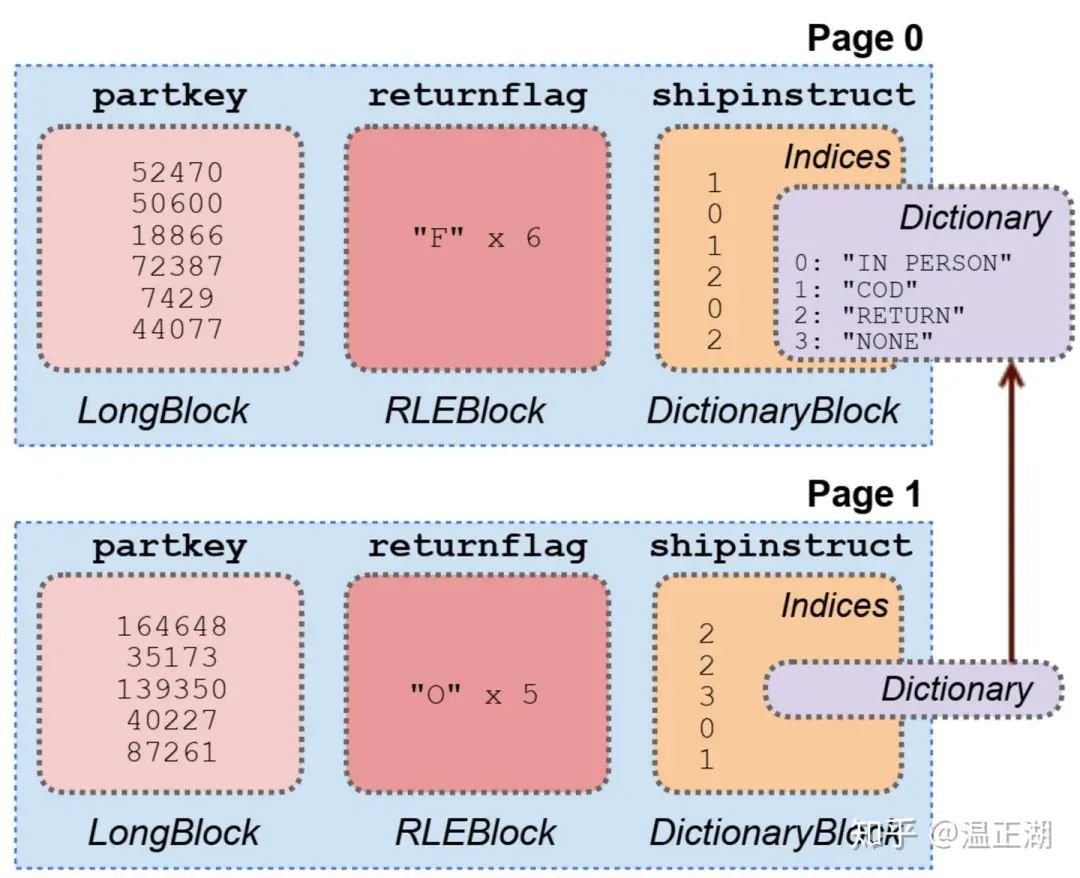
上图截至Presto论文,展示了RLE编码和数据字典编码的使用方式。RLE用在各列都是重复字符的情况,比如page0中6行记录的returnflag都是”F”。数据字典可高效使用在区分度较低的列上,比如列中只有几种字符串的场景。考虑到同个表的列的值相关性,数据字典可以跨page使用。
与数据压缩相比,数据编码方式在某些聚合类查询场景下,无需对数据进行解码,直接返回所需结果。比如假设T1表的C1列为某个字符,RLE算法将16个C1列的值“aaaaaabbccccaaaa”编码为6a2b4c4a,其中6a表示有连续6个字符a。当执行 select count(*) from T1 where C1=’a’时,不需要解压6a2b4c4a,就能够知道这16行记录对应列值为a有10行。
在列存模式下,数据压缩和编码的效率均远高于行存。
数据精细化存储
所谓数据精细化存储,是通过尽可能多得提供元数据信息来减少不必要的数据扫描和计算,常用的方法包括但不限于如下几种:
数据分区
行组
局部索引
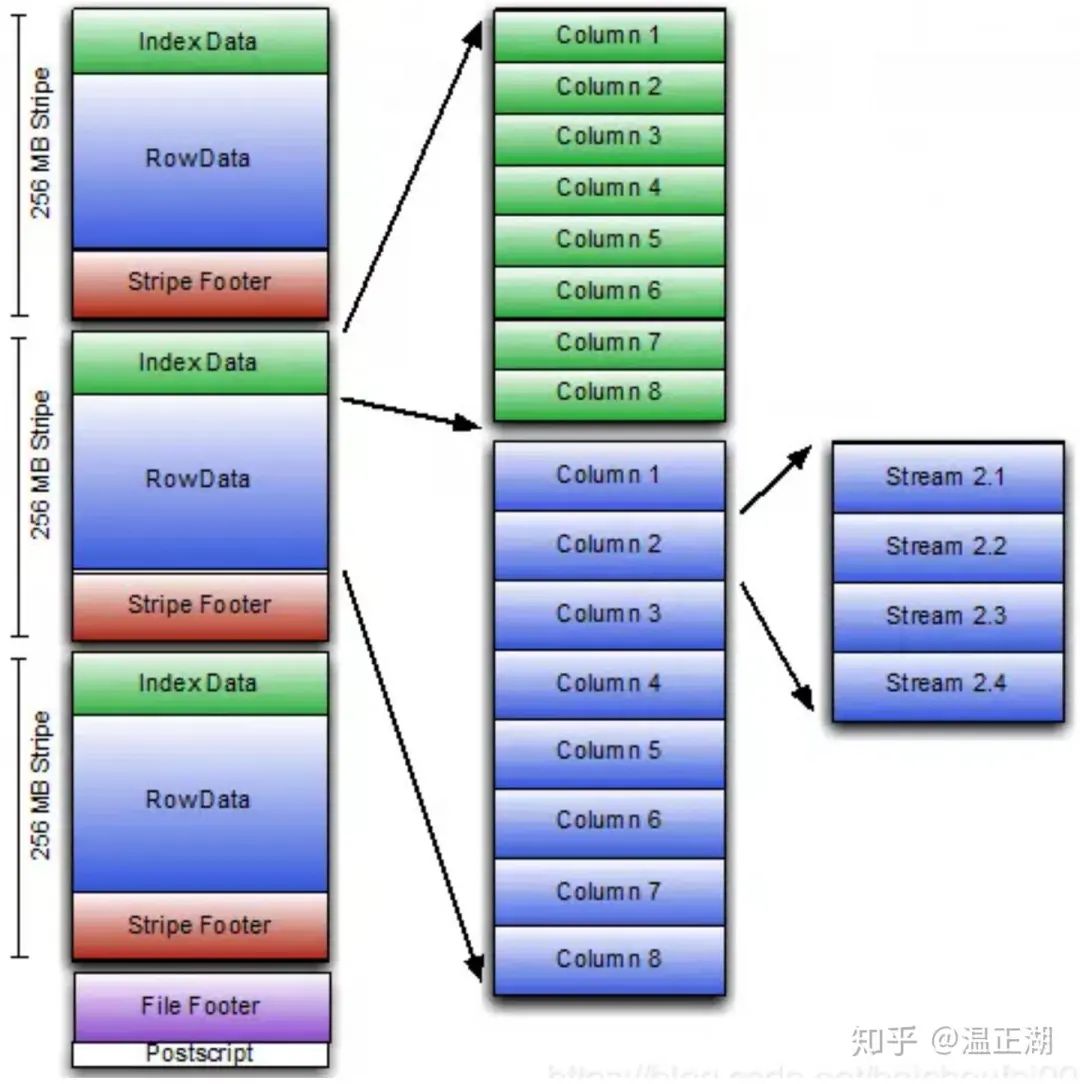
数据本地化访问
数据本地化读写是常见的优化方法,在Hadoop下也提供了相应的方式。
一般来说,读HDFS上的数据首先需要经过NameNode获取数据存放的DataNode信息,在去DataNode节点读取所需数据。
对于Impala等OLAP系统,可以通过HDFS本地访问模式进行优化,直接读取磁盘上的HDFS文件数据。HDFS这个特性称为”Short Circuit Local Reads”,其相关的配置项(在hdfs-site.xml中)如下:
其中:dfs.client.read.shortcircuit是打开这个功能的开关,dfs.domain.socket.path是Datanode和DFSClient之间沟通的Socket的本地路径。
运行时数据过滤
Impala的RunTime Filter(RF)运行时过滤SparkSQL 3.0的 Dynamic Partition Pruning动态分区裁剪
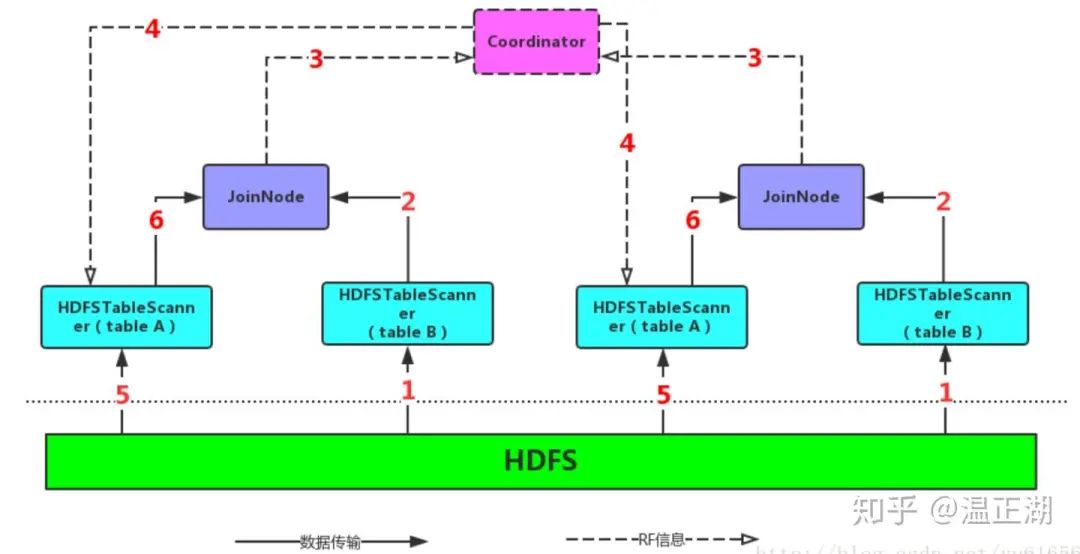
上图直观得展示了Impala runtime filter的实现。流程如下:
同时下发两个表的SCAN操作。左边是大表,右边是小表(相对而言,也有可能是同等级别的),但是左表会等待一段时间(默认是1s),因此右表的SCAN会先执行;
右表的扫描的结果根据join键哈希传递扫不同的Join节点,由Join节点执行哈希表的构建和RF的构建;
Join节点读取完全部的右表输入之后也完成了RF的构建,它会将RF交给Coordinator节点(如果是Broadcast Join则会直接交给左表的Scan节点);
Coordinator节点将不同的RF进行merge,也就是把Bloom Filter进行merge,merge之后的Bloom Filter就是一个GLOBAL RF,它将这个RF分发给每一个左表Scan;
左表会等待一段时间(默认1s)再开启数据扫描,为了是尽可能的等待RF的到达,但是无论RF什么时候到达,RF都会在到达那一刻之后被应用;
左表使用RF完成扫描之后同样以Hash方式交给Join节点,由Join节点进行apply操作,以完成整个Join过程。
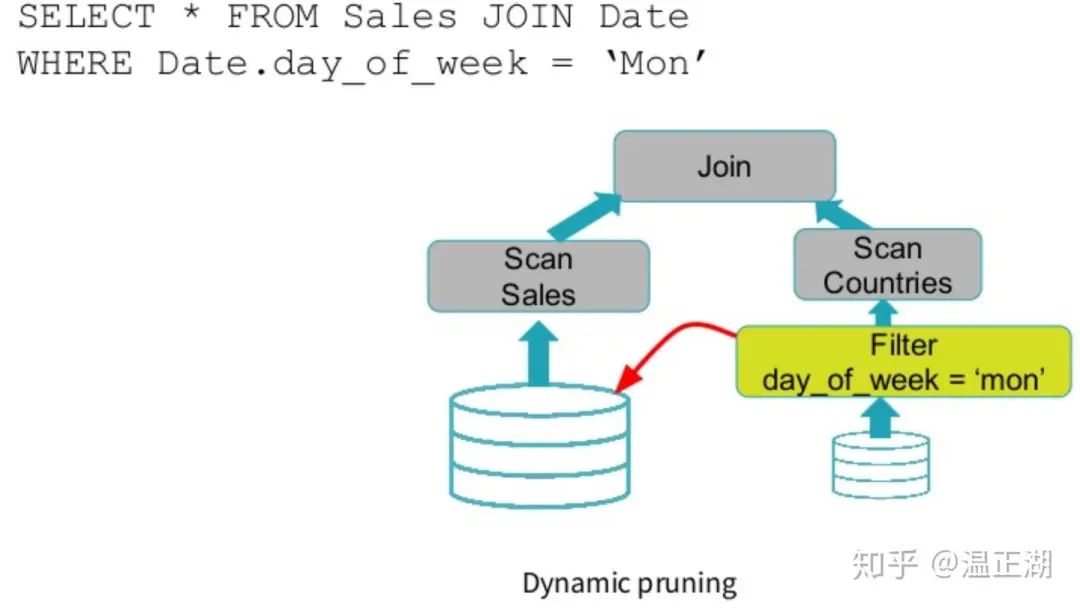
sparksql图1(官方这个图有误,右边应该是Scan Date)
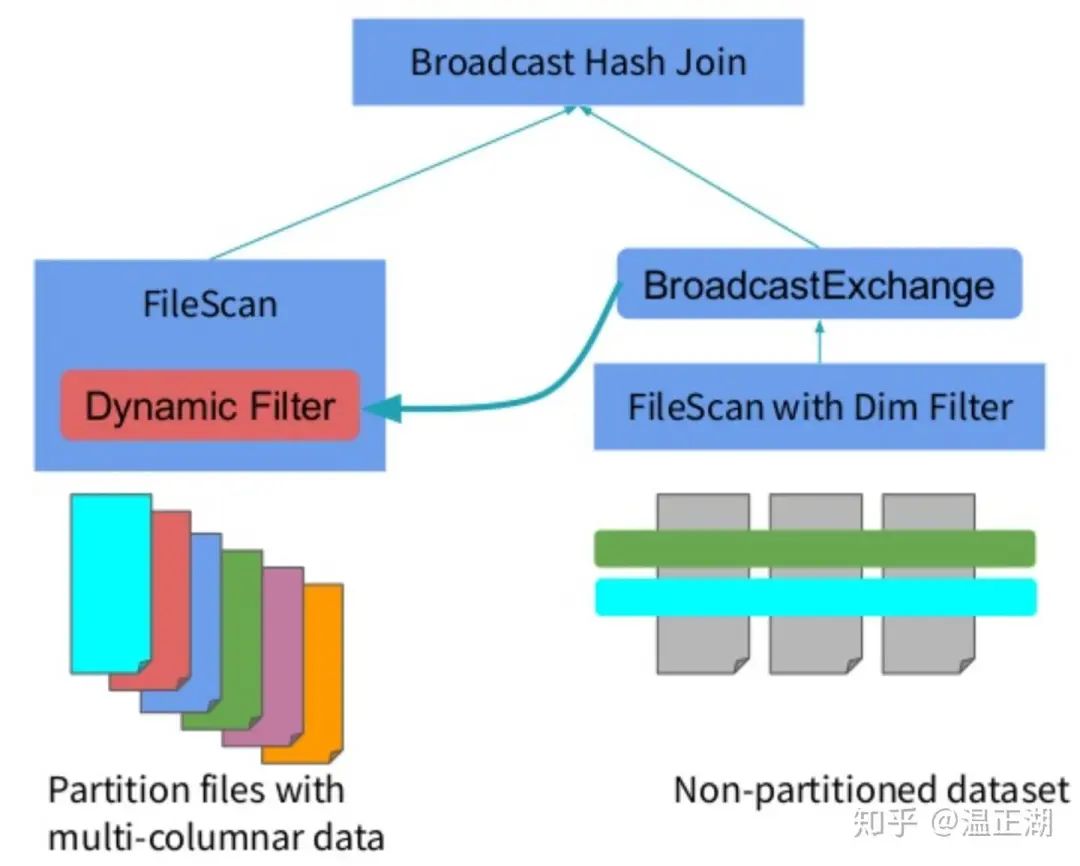
sparksql图2
上面2幅图是SparkSQL 3.0的动态分区裁剪示意图。将右表的扫描结果(hashtable of table Date after filter)广播给左表的Join节点,在进行左表扫描时即使用右表的hashtable进行条件数据过滤。
除了上面这些,还有其他优化方法吗?
还有个极为重要的技术是集群资源管理和调度。Hadoop使用YARN进行资源调度,虽然带来了很大遍历,但对性能要求较高的OLAP系统却有些不适合。
如启动AppMaster和申请container会占用不少时间,尤其是前者,而且container的供应如果时断时续,会极大的影响时效性。
目前的优化方法主要包括让AppMaster启动后长期驻守,container复用等方式。让资源在需要用时已经就位,查询无需等待即可马上开始。
–END–








暂无评论内容