

大家好,今天分享的文章是Doris在各大公司生产实践的一些总结。
Doris经过多年的持续深耕,从最初的单纯的OLAP能力上逐步取代上一代的查询引擎,并且在跟ES、ClickHouse等同一生态位的竞品竞争中也表现出色。
今天的文章我们站在一个用户的角度,总结Doris社区在过去上半年各大公司的分享,总这些分享中汲取有用的经验。
落地场景总结
在笔者查阅的数十篇各大公司的分享中,2025年上半整个行业内各家公司对于Doris的使用也从最初的单纯OLAP,持续向准实时调度、湖仓一体等场景深入。
湖仓一体方案
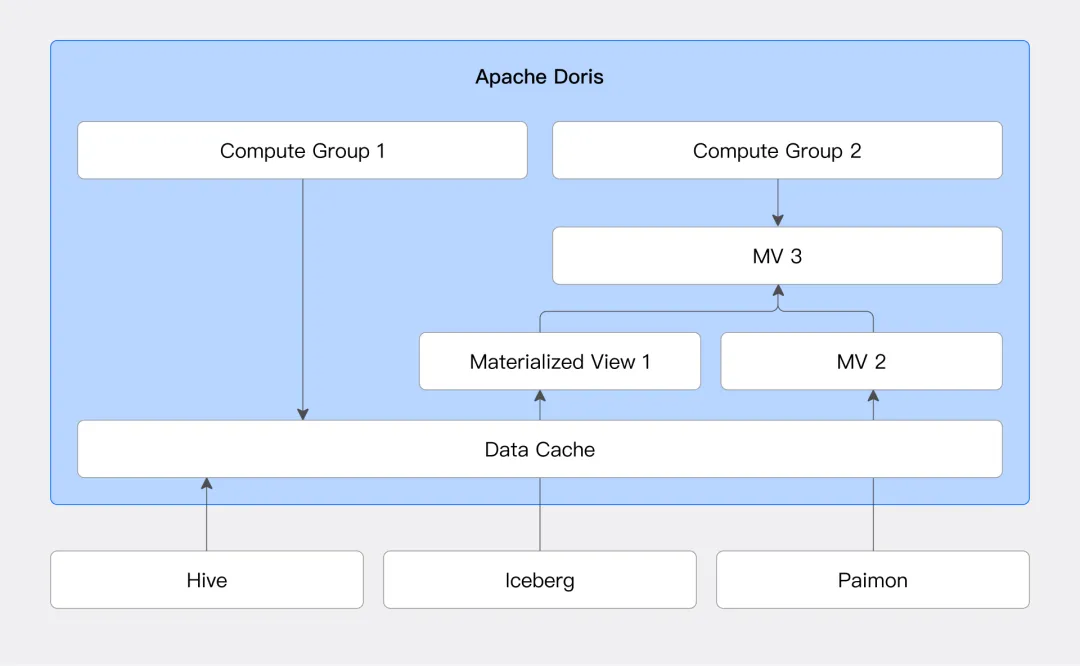
自2.1版本以来,Apache Doris在湖仓一体场景的能力得到了显著提升与完善。很多公司在湖仓一体场景进行了落地尝试。
数据通过Kafka进行采集,并使用Flink和Spark实现数据加工处理,依据数据时效性的需求,数据被接入数据湖表或Doris表中。
Doris本身支持非常多的连接器,包括Hive、Iceberg、Hudi、Paimon,以及JDBC协议的数据库系统。
此外Doris支持可扩展的连接器框架,Doris 定义了标准的数据目录(Catalog)、数据库(Database)、数据表(Table)三个层级,开发人员可以方便的映射到所需对接的数据源层级。Doris 同时提供标准的元数据服务和数据读取服务的接口,开发人员只需按照接口定义实现对应的访问逻辑,即可完成数据源的对接。
Doris与Paimon、IceBerg等数据湖框架深度融合,能够直接访问湖表中数据,可以实现湖中数据的加速查询。分析结果不仅可以展示给应用层,Doris同时提供了湖表回写的能力,结果可以通过Doris写回到Iceberg中进行存储。
这个我们不赘述了。在下文的优化环节会提到。
Doris可以作为统一SQL查询引擎,连接不同数据源进行联邦分析。
Doris可以通过创建多个Catalog连接不同的数据源,并且在SQL中可以通过catalog.db.table的方式对不同数据源中的数据进行任意关联查询。
最后我们贴几张截图,大家可以参考各大公司湖仓架构中Doris所处的位置和作用。
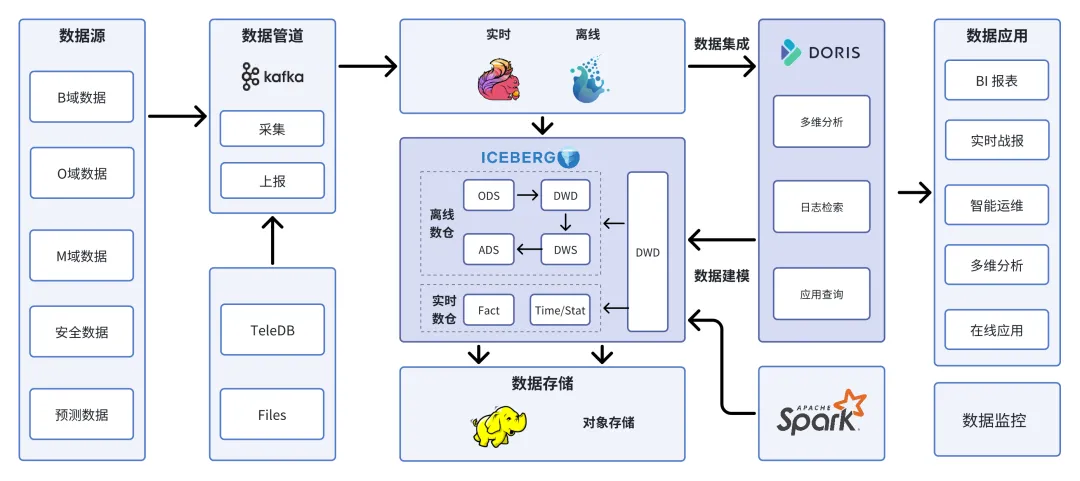
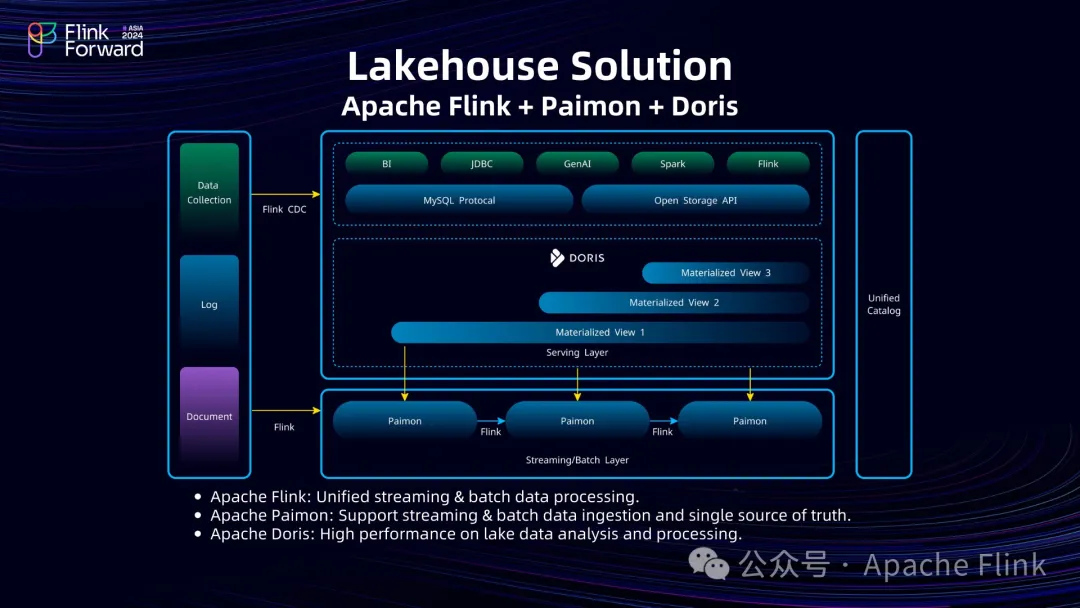
Doris+定时调度构建准实时数仓
第二类大的落地应用是通过定时调度的方式构建基于Doris的准实时数仓。
在很多情况,我们不需要数据秒级时效,这时候就可以通过Doris+分钟/小时级调度,实现数据的准实时处理。
例如在美团、抖音等公司的分享中,通过引入Doris引擎,结合定时调度构建了准实时生产数仓。
在该架构中,利用Doris的实时写入能力(如KafkaToDoris实现秒级延迟写入),配合可靠的 5、10、15、30分钟的调度保障能力,实现了业务数据的微批处理。
同时,通过将实时数据与离线数据在Doris中进行融合,利用Doris的高效OLAP交互能力,支撑业务的灵活查询访问。
业务层通过视图进行逻辑封装,直接复用汇总层多维模型,提高了开发效率,减少了运维成本。实践证明,以Doris引擎为驱动的准实时数仓模式,有效解决了数据生产和查询的难题,同时满足业务对数据时效性和灵活性的需求。
这里我们必须要提一个能力,Doris在2.1版本中引入了 Job Scheduler 功能,实现了自主任务调度能力,调度的精准度可达到秒级,这个能力大家可以谨慎评估接入使用,更推荐的是结合第三方的调度框架使用。
替代ES,多维分析
Elasticsearch这个框架在很多公司都有使用,广泛应用于实时分析、日志分析、全文搜索和数据监控等领域。在过去一段时间里,ES因为独有的DSL查询语音,比较高的成本受到诟病,因此有相当多的场景可以用Doris替代。
关于ES和Doris的一些对比,我们之前写过一篇文章可以参考:
「精华版」Doris VS Elasticsearch全方位对比和落地实践指导
Doris优化
关于Doris的优化,不同公司的关注点不同。但是基本都集中在读、写、compaction等。
我们在早些时候总结过,可以参考:
其他
此外,不同公司在使用Doris上有自己的一些「奇技淫巧」。这里我们不一一列举,大体上属于”旁门左道”,是基于自身业务特点和内部平台做的定制化的优化。
我们今天的分享就到这里。后面会继续更新其他组件在各大公司生产环境的最佳实践,欢迎持续关注。








暂无评论内容