

滴滴指标标准化实践
==================================================

导读
1. 指标管理背景
2. 滴滴数据产品概况
3. 指标标准化建设
4. 后续规划
5. Q&A
分享嘉宾|曾晶 滴滴 专家工程师
编辑整理|唐唐
内容校对|李瑶
出品社区|DataFun
01
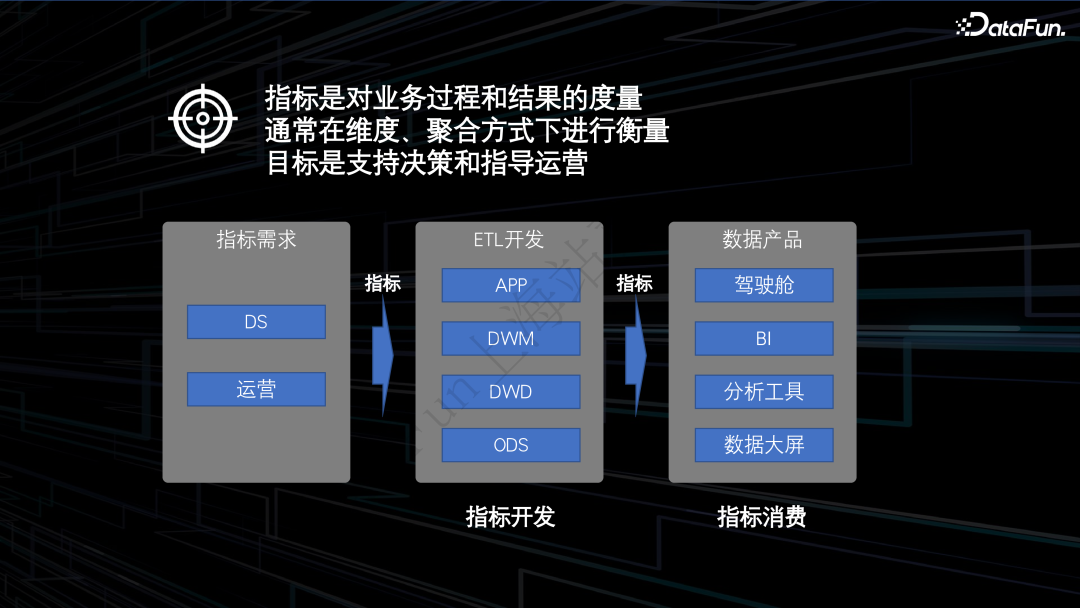
DS 或运营提出指标需求
数据 BP 或数据产品梳理确认指标口径
数仓工程师进行 ETL 开发
1.指标的基本要求
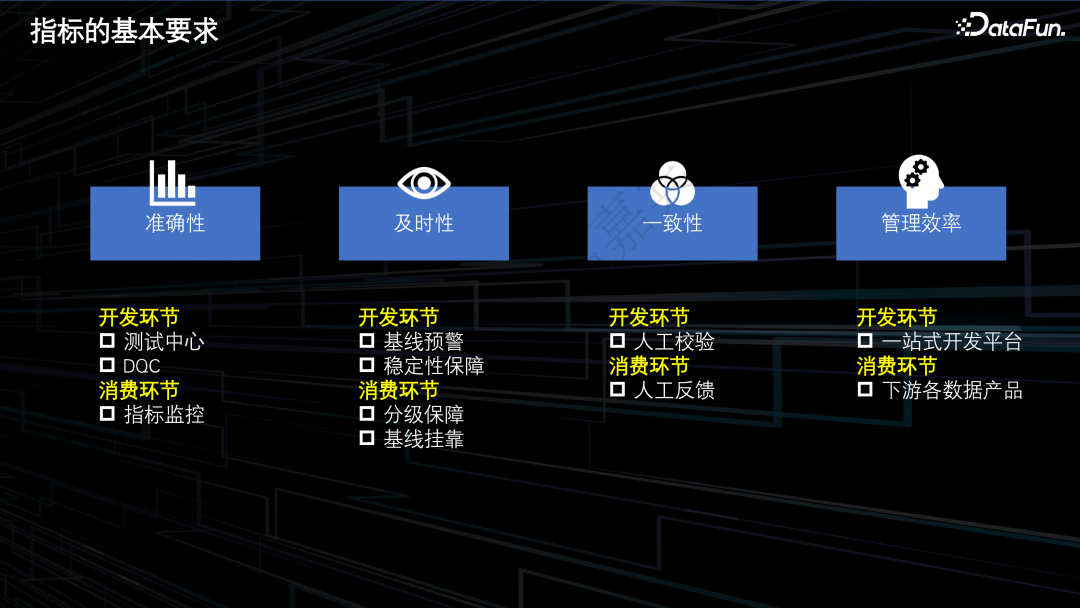
开发环节:通过测试中心进行指标数据的测试验收;通过配置数据质量规则监控指标新增分区的产出情况。
消费环节:通过配置指标监控监测数据异动。
开发环节:在指标的生产任务上关联对应的SLA基线,通过基线的智能预警,配合平台的稳定性保障措施,保证指标的及时产出。
消费环节:根据指标等级进行分级保障,不同等级的指标挂靠不同级别的基线,通过基线倒推保障下游数据的及时产出。
开发环节和消费环节:通过人工校验和反馈的方式确保指标的一致性。
开发环节:基于统一的一站式开发平台进行指标的开发。
消费环节:在下游各个数据产品中定义指标口径和取数逻辑。
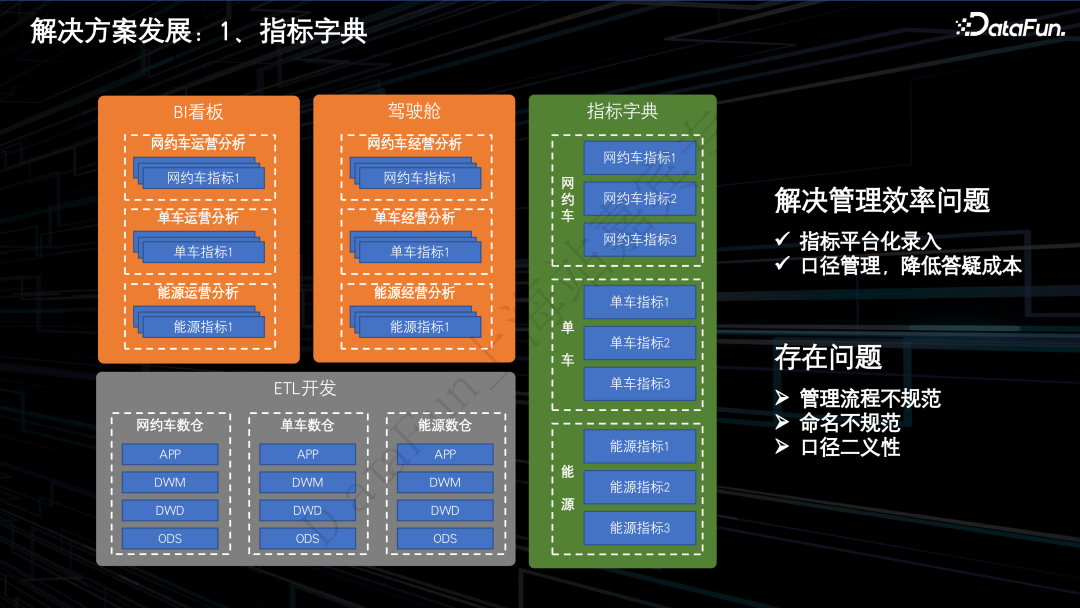
2.解决方案发展
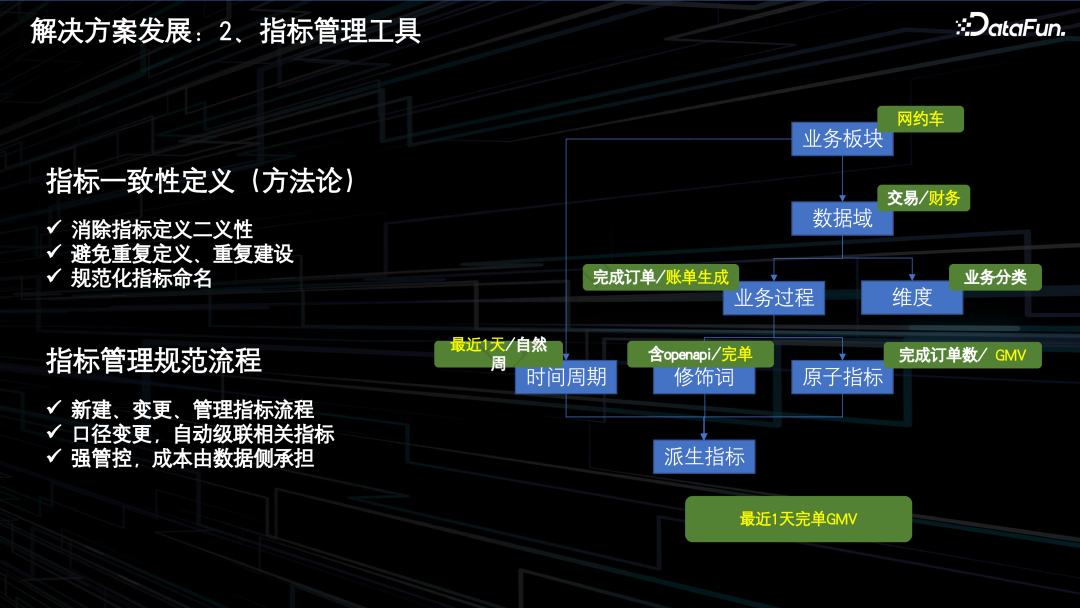
根据滴滴的业务属性,划分网约车、两轮车等独立的业务板块。
在业务板块下划分数据域以及时间周期。时间周期主要是用于描述数据统计的时间范围,数据域通常是业务过程或者维度进行抽象的集合。
在数据域下划分业务过程。业务过程通常是企业业务活动的事件。
在业务过程下划分原子指标以及修饰词。原子指标通常是某个业务过程的度量,是业务定义中不可再分的指标。修饰词通常是除维度以外的限定条件。原子指标和修饰词以及时间周期构成了派生指标。
滴滴数据产品概况
1.数据产品多样,各自消费指标

指标管理工具和指标生产、消费链路是脱离的,指标管理工具等同于一个规范化的线上 wiki,指标管理的业务价值难以评估。
下游各个数据产品各自维护指标的计算口径, 指标口径的一致性无法得到保障。
下游用户只能基于数仓提供的APP表中包含的维度进行数据分析,无法进行灵活的下钻分析。
2.敏捷 BI 难以管控指标口径
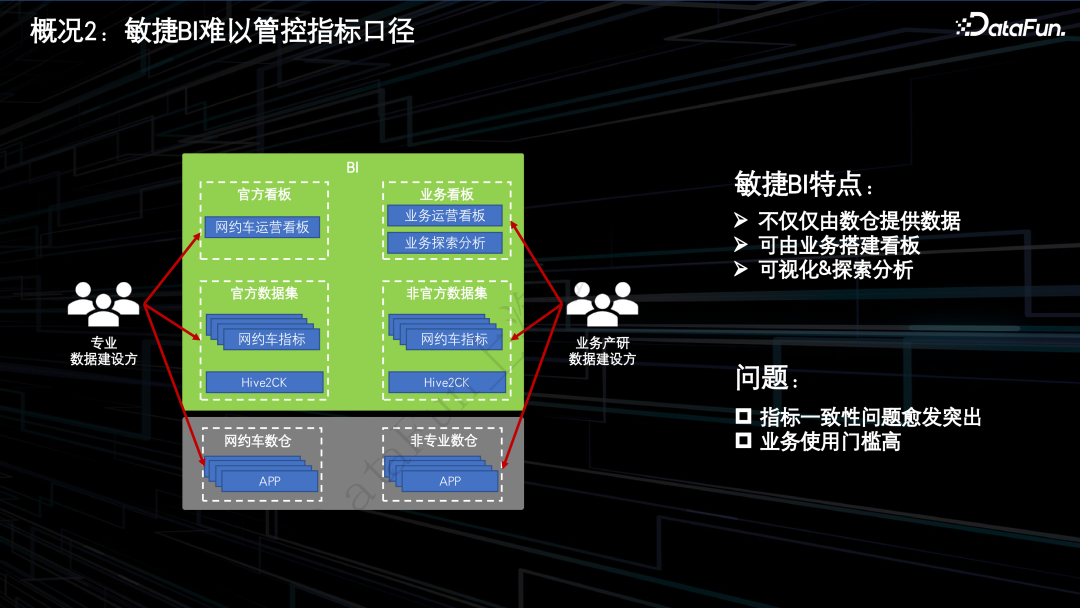
指标的计算口径由业务人员维护,并且散落在各个数据产品以及数据集中,导致指标口径的一次性问题变得更加严峻。
指标加工对于业务人员来说,存在一定的门槛。
3.问题总结
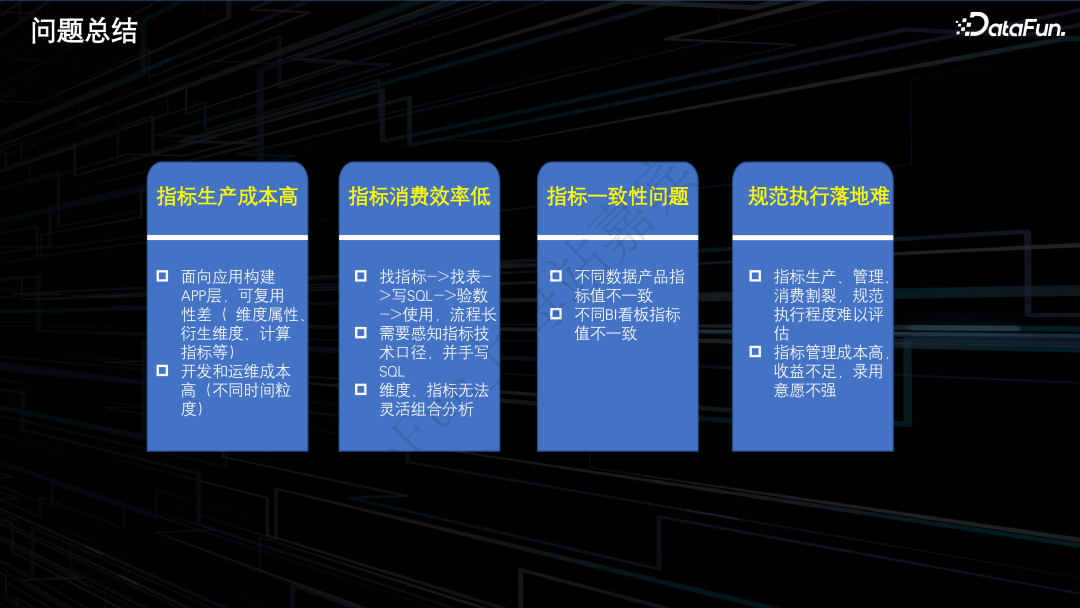
指标生产成本高。数仓面向应用层去构建 APP 表,可复用性差,譬如需要在 APP 表中冗余存储维度属性,针对衍生维度或者计算指标需要做二次计算。此外,开发和运维成本高,譬如针对于不同时间粒度下的同一个指标,数仓需要开发多张 APP 表,指标的生产成本高进而影响数仓的交付效率。
指标消费效率低。在传统数仓模式下,基于 APP 表的交付方式很难支撑业务进行灵活的自助分析。在敏捷 BI 模式下,如果业务需要分析某个指标,首先需要在指标管理工具中找到该指标,然后基于指标对应的物理表和计算口径手写 SQL 进行取数验数,不但流程长,而且使用门槛高。
指标口径存在一致性问题。由于指标的取数逻辑沉淀在各个数据产品以及数据集中,所以会造成不同数据产品间指标数据的不一致,乃至同一数据产品上不同BI看板间指标数据的不一致。
规范执行落地难。由于指标管理游离在指标生产和消费链路之外,导致指标管理的规范执行程度难以评估。其次,指标管理的成本较高,而下游消费指标场景比较单一,导致指标管理的收益不足,进而影响数据BP的录入意愿,从而加重了指标管理执行的难度。
指标标准化建设
1.整体方案
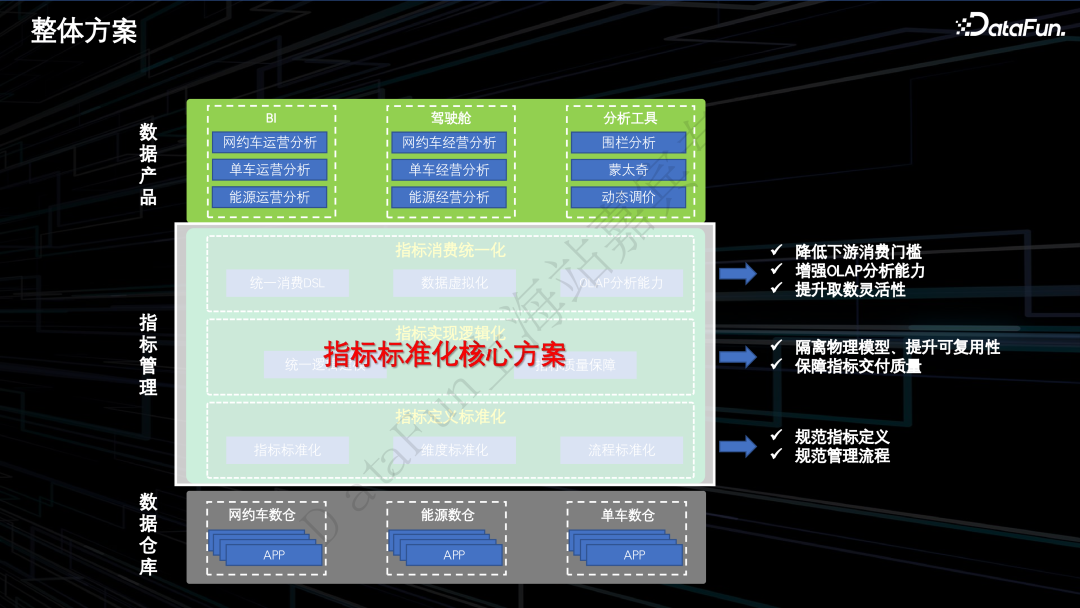
指标定义标准化:基于指标管理工具,进行指标的标准化定义以及流程管控。
指标实现逻辑化:通过逻辑模型隔离指标生产和消费,提升物理模型可复用性,保障指标交付质量。
指标消费统一化:基于指标维度的统一查询 DSL,降低下游消费门槛,通过接入统一查询服务,保障指标口径一致性,通过数据虚拟化技术增强 OLAP 的分析能力,提升取数灵活性。
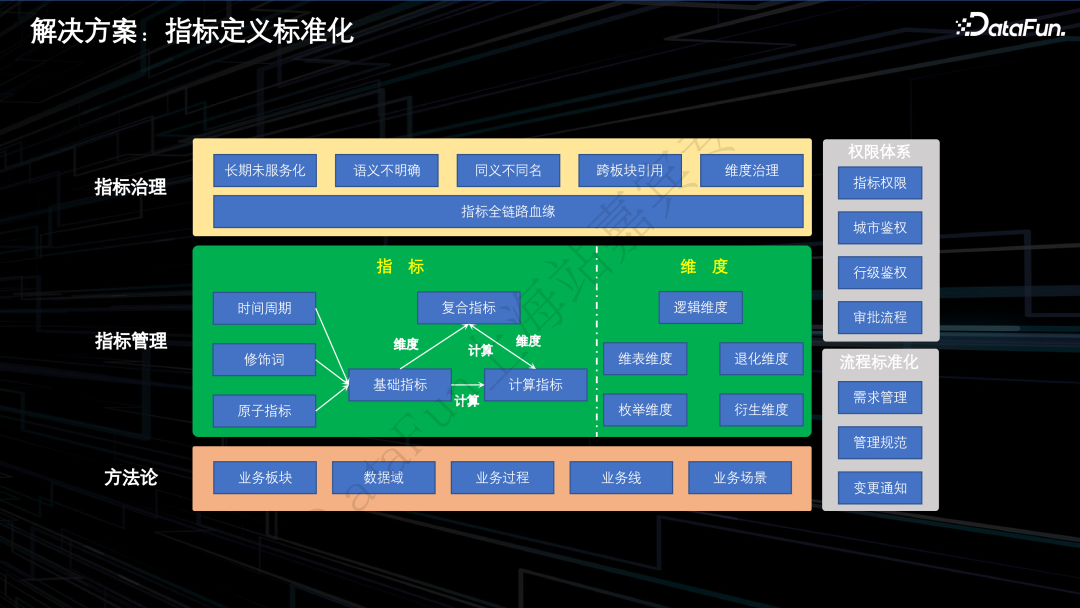
基础指标:对应于物理表上的某个字段。
计算指标:基于其他指标四则计算得到。
复合指标:基于其他指标复合维度得到。
维表维度:对应于一张维表,维表包含唯一的主键以及其他的维度属性,譬如城市维度。
枚举维度:用来描述可枚举的 k-v 键值对,譬如业务线维度,key 是业务线 ID,value 是业务线名称。
退化维度:某些场景下,一些维度在不同的物理表上有不同的计算逻辑,但代表的是同一个维度。退化维度主要用于解决这种场景。
衍生维度:和退化维度类似,区别在于衍生维度的计算逻辑比较通用,可以进行集中化管理。
将 DS 提指标需求、数据 BP 录入指标、数据开发交付指标的流程进行线上化。
对指标的变更流程进行强管控,当指标口径发生变更时,所有下游指标会自动级联变更,并通知到所有的下游应用。
在看清方面,构建了从基础指标、时间周期、修饰词到基础指标,基础指标和维度到计算指标和复合指标的全链路血源。
在治理措施方面,针对长期未使用的指标维度,会自动进入废弃状态,针对公共的指标维度,支持跨业务板块引用和管理。
3.解决方案:指标实现逻辑化——逻辑建模
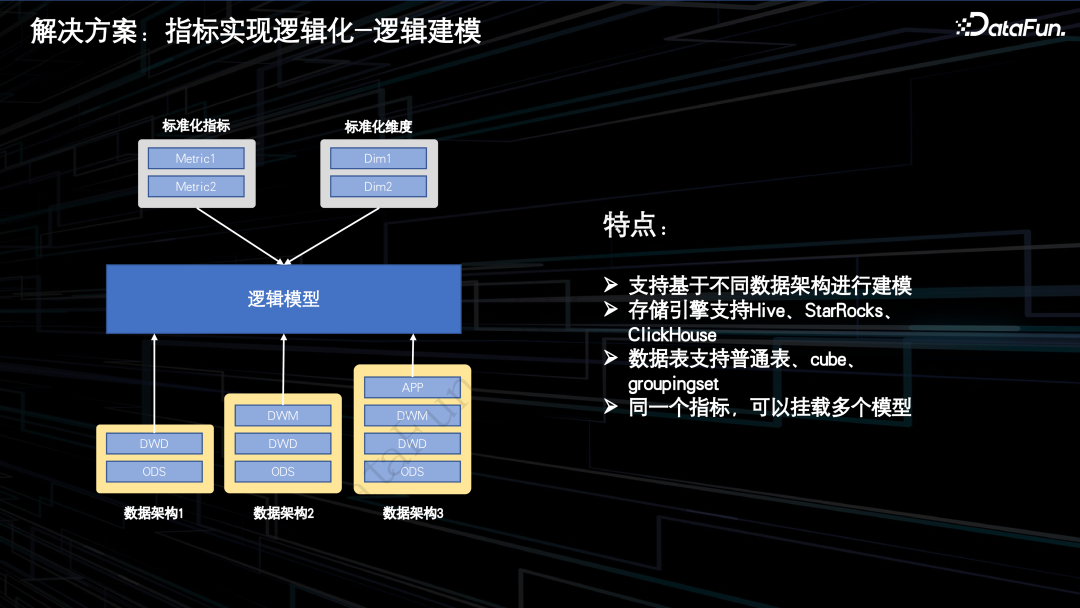
逻辑模型可以适配不同的计算引擎,对用户屏蔽了不同引擎的计算差异。
逻辑模型可以适配不同的表粒度,对用户屏蔽 cube 表、groupingsets 表以及普通表在数据存储上的差异。
逻辑模型可以适配不同的数仓架构,不仅支持 APP 表的接入,也支持直接接入 DWM 和 DWD 表。
逻辑模型可以实现配置即开发。譬如针对同一指标不同时间粒度的情况,数仓只需要开发天粒度的指标,自然周、自然月指标可以基于最近一天指标上卷得到,譬如计算指标和复合指标可以通过实时计算得到,无需落表开发,譬如通过逻辑维度可以自动构建数仓的星形模型和雪花模型。
4.解决方案:指标实现逻辑化——指标质量保障
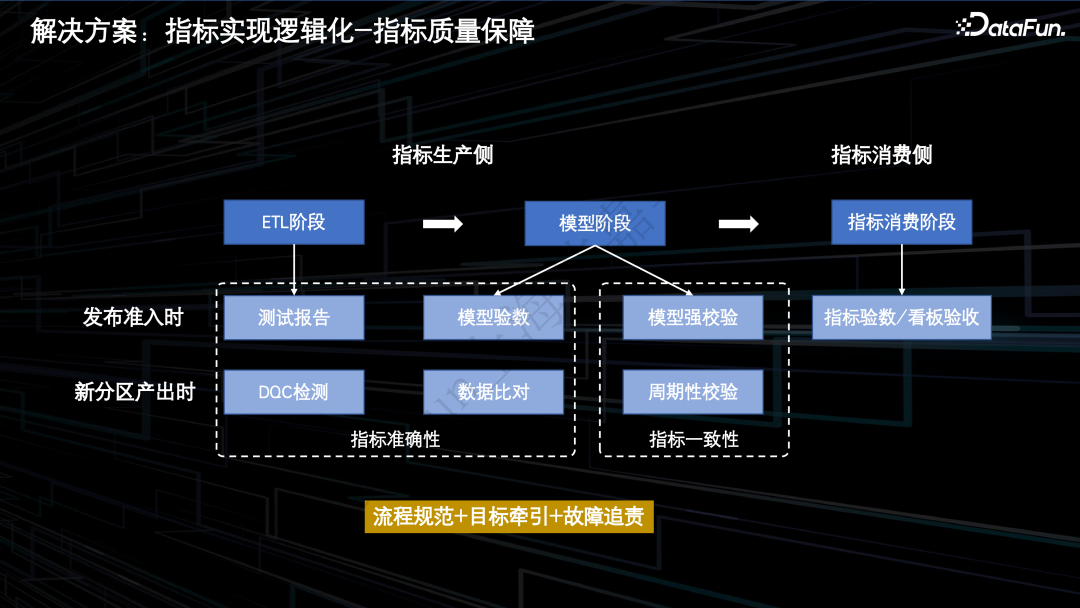
ETL 阶段:当指标的生产任务变更时,需要产出指标的测试报告后方可准入。同时在 DQC 上配置指标的数据质量规则,用来检测新增分区的产出质量。
逻辑模型阶段:在模型发布前,需要针对模型上的指标进行验数,并且需要和线上版本的数据进行比对,以确保模型的正确配置和变更。为了保证指标的一致性,针对模型上的所有指标进行不同模型间的一致性校验,只有数据一致才允许发布到线上。同时,平台会默认监听模型分区的变更,并自动进行系统一致性校验,一旦出现数据不一致的情况则会及时告知用户。
5.解决方案:指标实现逻辑化——指标质量保障
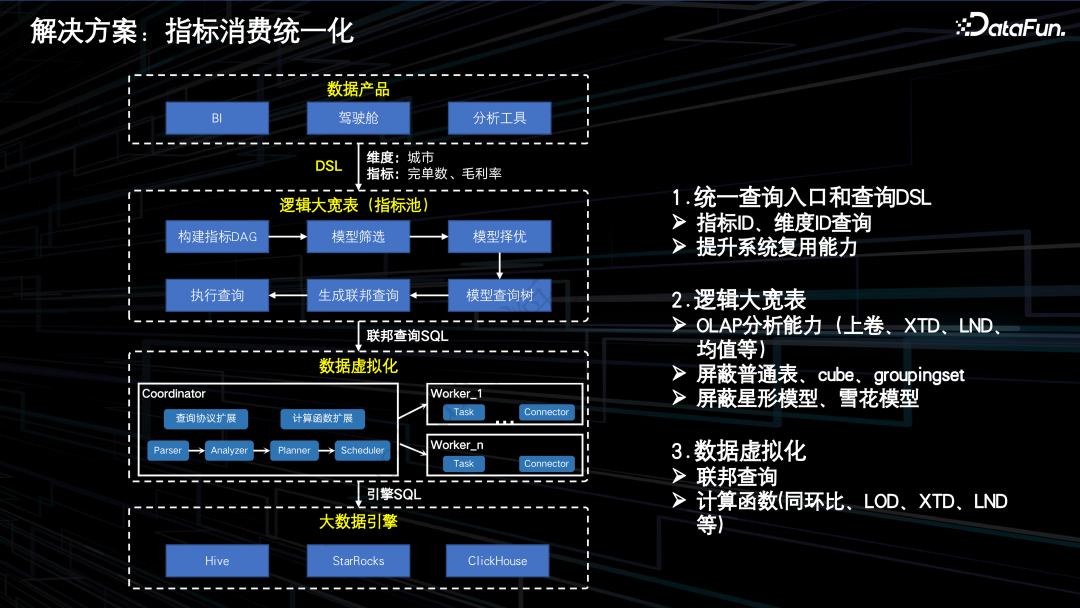
周期排序:譬如自然月指标同时存在天模型和月模型中,优先选取月模型,通过减少计算数据量提高查询速度。
引擎排序:譬如指标同时存在 Hive 模型和 SR 模型中,优先选取 SR 模型,充分利用 OLAP 引擎的计算能力。
粒度排序:譬如指标同时存在 Cube 表模型和普通表模型中, 优先选取 Cube 表模型,通过指标的预计算提高查询速度。
效率排序:譬如优先选取能够满足更多指标查询请求的模型,针对同一个模型上的指标进行查询请求的合并,通过减少查询次数提高查询速度。
引擎 SQL:描述同一模型上所有指标的查询 SQL,不同模型的引擎 SQL 会根据引擎类型发送到不同的数据引擎执行数据查询。
MPP SQL:描述不同模型间指标的计算关系,用于汇聚不同模型间的指标并进行二次计算,比如周、月、季、年的上卷,XTD,最近 N 天的上卷以及同环比均值等。
6.重塑消费体系
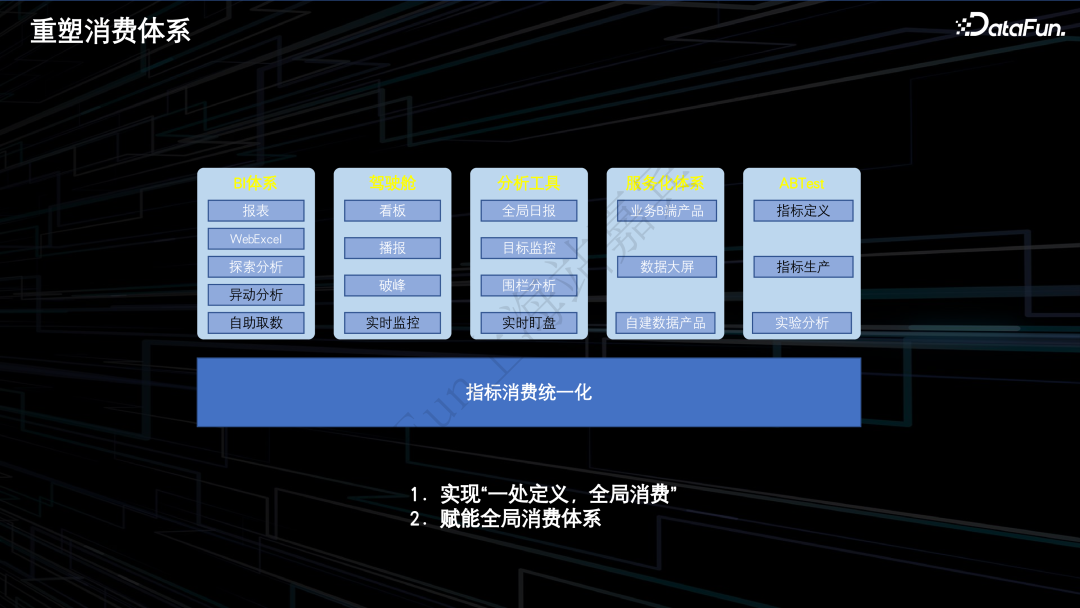
7.收益总结
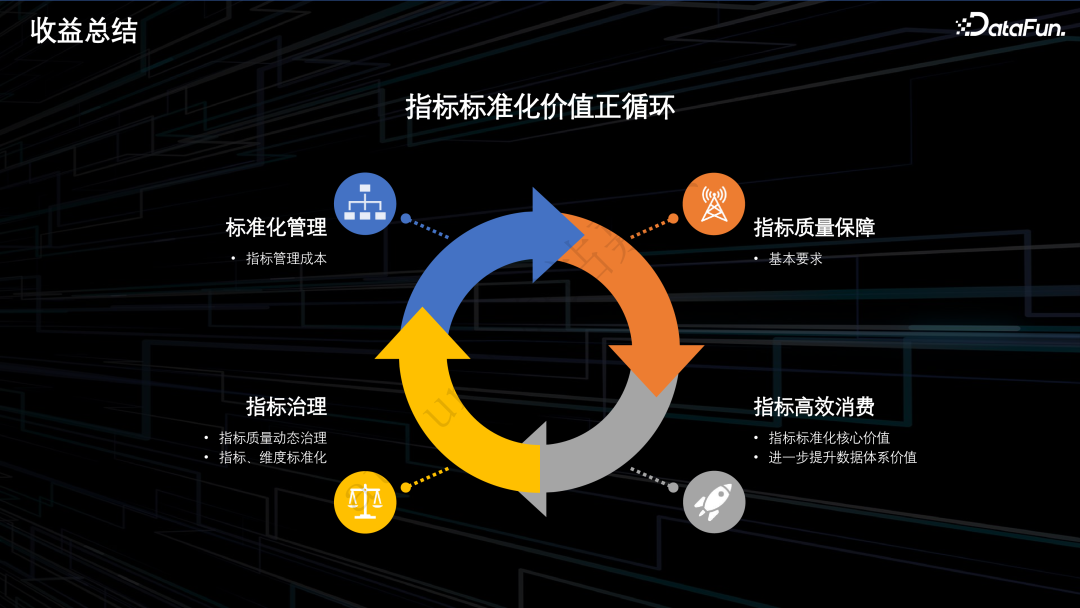
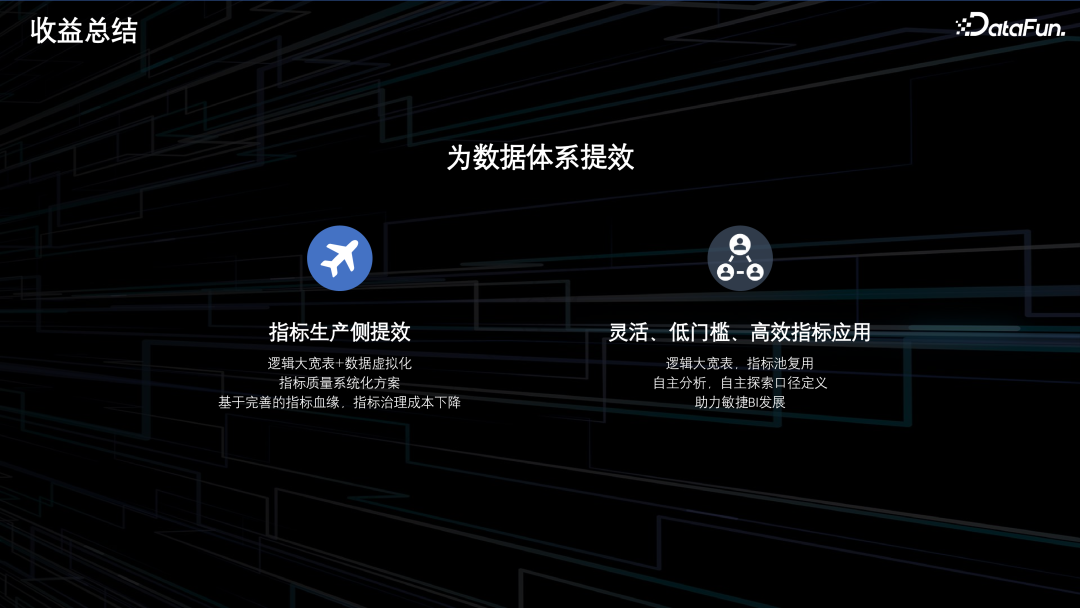
通过逻辑大宽表和数据虚拟化的方案,使得部分指标维度无需落表开发,降低数仓的开发成本,提升数仓的需求交付效率。
通过提供系统化的指标质量保障方案,保障指标口径的一致性,降低数仓的运维成本。
通过构建完善的指标维度血缘,为数仓治理提供可靠的依据,降低数仓的治理成本。
(2)消费侧
04
后续规划
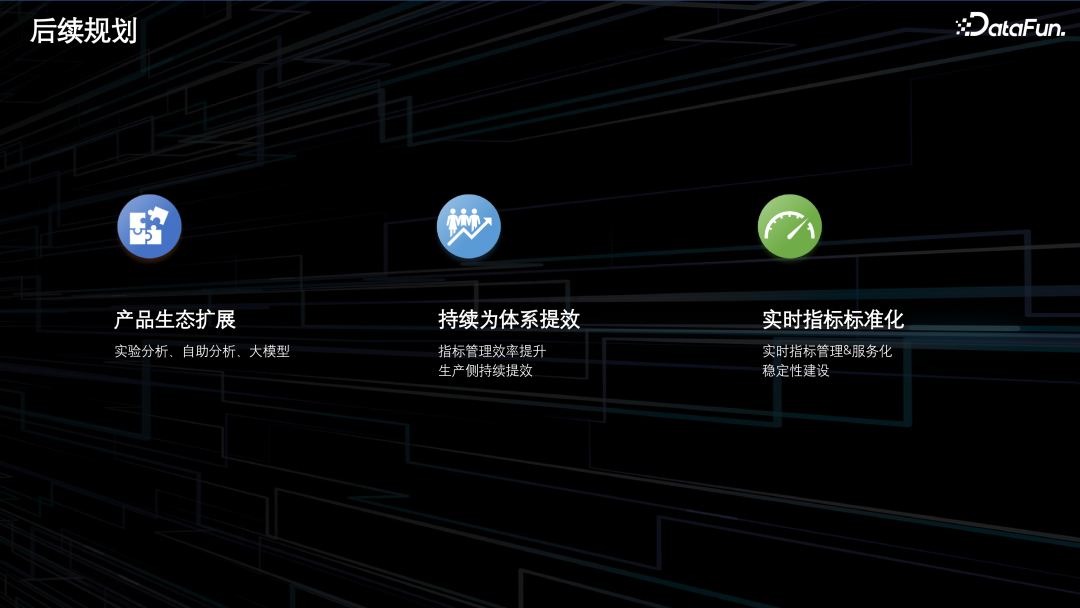
打通实验分析领域,保证实验指标和 BI 指标口径的一致性。
通过自助分析产品,提供更加灵活的取数方式,为 DS 及运营提效, 提升指标标准化建设的价值感知。
探索基于大模型的指标取数方式,进一步降低下游取数的门槛。
从指标录入效率和模型构建灵活性等方面,进一步提升指标管理和开发的效率。
基于统一的指标监控告警能力,进一步保障指标的交付质量。
打通指标生产链路,实现指标生产自动化,进一步降低数仓的开发成本。








暂无评论内容