

由Facebook开源的Presto是其中的佼佼者,它是以MPP为架构的OLAP引擎中的中流砥柱。如果你学习过Spark、Flink的源码,会惊喜地发现,其中的多个设计思路和实现都参考了Presto,甚至于2019年在北京召开的Flink Forward大会上介绍Flink OLAP发展方向时,对比的对象都是Presto
OLAP引擎底层技术中有很多数据库相关的知识点和优化技术,有些实现甚至是对数据库技术的直接借鉴和模仿。所以,我们以Presto为例来学习数据库知识,了解OLAP引擎底层技术。但是,仅看Presto源码是不够的,还需要上升到理论,再用理论指导实践,这样才能够完全看懂和理解Presto的代码。
除了Presto是MPP架构之外,其实我们常用的大数据计算引擎有很多都是MPP架构的,像我们熟悉的Impala、ClickHouse、Druid、Doris等都是MPP架构。
亿级秒开
一、MPP架构
MPP是系统架构角度的一种服务器分类方法。
目前商用的服务器分类大体有三种:
我们今天的主角是 MPP,因为随着分布式、并行化技术成熟应用,MPP引擎逐渐表现出强大的高吞吐、低时延计算能力,有很多采用MPP架构的引擎都能达到“亿级秒开”。
先了解下这三种结构:
1. SMP
SMP服务器的主要特征是共享扩展能力非常有限
2. NUMA
每个CPU可以访问整个系统的内存
这种结构也有一定的缺陷,由于访问异地内存的时延远远超过访问本地内存,因此,当CPU数量增加时,系统性能无法线性增加。
3. MPP
完全无共享(Share Nothing)结构
MPP结构扩展能力最强,理论可以无限扩展。由于MPP是多台SPM服务器连接的,每个节点的CPU不能访问另一个节点内存,所以也不存在异地访问的问题。
MPP架构图:
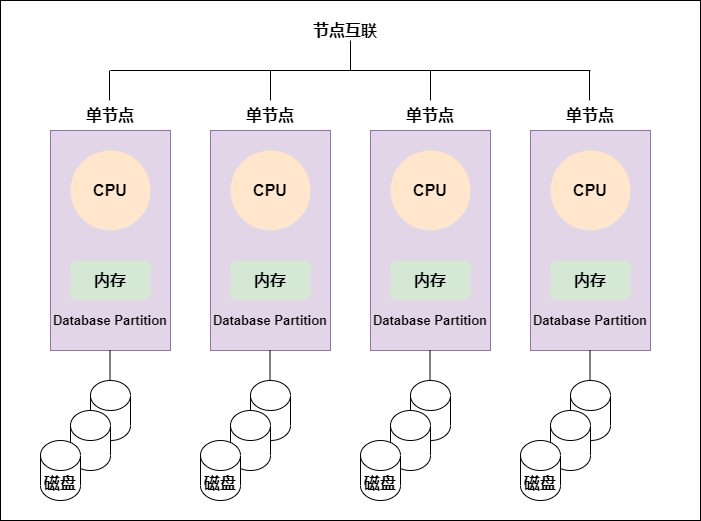
图片说明: 图片
数据重分配
但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前,一些基于MPP技术的服务器往往通过系统级软件(如数据库)来屏蔽这种复杂性。举个例子,Teradata就是基于MPP技术的一个关系数据库软件(这是最早采用MPP架构的数据库),基于此数据库来开发应用时,不管后台服务器由多少节点组成,开发人员面对的都是同一个数据库系统,而无需考虑如何调度其中某几个节点的负载。
MPP架构特征:
NUMA和MPP区别:
二者有许多相似之处,首先NUMA和MPP都是由多个节点组成的;其次每个节点都有自己的CPU,内存,I/O等;都可以都过节点互联机制进行信息交互。
节点互联机制不同
内存访问机制不同
二、批处理架构和MPP架构
批处理架构(如 MapReduce)与MPP架构的异同点,以及它们各自的优缺点是什么呢?
相同点:
批处理架构与MPP架构都是分布式并行处理
不同点:
对于MapReduce来说,这些tasks被随机的分配在空闲的Executor上;而对于MPP架构的引擎来说,每个处理数据的task被绑定到持有该数据切片的指定Executor上
正是由于以上的不同,使得两种架构有各自优势也有各自缺陷:
如果某个Executor执行过慢,那么这个Executor会慢慢分配到更少的task执行
会将中间结果写入到磁盘中
MPP架构不需要将中间数据写入磁盘
整个集群的性能就会受限于这个故障节点的执行速度短板效应MPP架构的集群节点不易过多
这是因为MPP将mapper和reducer同时运行,而MapReduce将它们分成有依赖关系的tasks(DAG),这些task是异步执行的,因此必须通过写入中间数据共享内存来解决数据的依赖
批处理架构和MPP架构融合:
目前批处理和MPP也确实正在逐渐走向融合
三、 MPP架构的OLAP引擎
采用MPP架构的OLAP引擎有很多,下面只选择常见的几个引擎对比下,可为公司的技术选型提供参考。
采用MPP架构的OLAP引擎分为两类,一类是自身不存储数据,只负责计算的引擎;一类是自身既存储数据,也负责计算的引擎
1)只负责计算,不负责存储的引擎
1. Impala
直接使用内存进行计算
提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由Java和C++实现的,Java提供的查询交互的接口和实现,C++实现了查询引擎部分。
Impala支持共享Hive Metastore,但没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
Impala经常搭配存储引擎Kudu一起提供服务,这么做最大的优势是查询比较快,并且支持数据的Update和Delete。
2. Presto
支持跨数据源的级联查询
内存计算引擎
2)既负责计算,又负责存储的引擎
1. ClickHouse
列式数据库
它自包含了存储和计算能力,完全自主实现了高可用,而且支持完整的SQL语法包括JOIN等,技术上有着明显优势。相比于hadoop体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社区仍旧在迅猛发展中,并且在国内社区也非常火热,各个大厂纷纷跟进大规模使用。
竭尽所能榨干硬件能力,提升查询速度
实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能
2. Doris
海量分布式 KV 存储系统
Doris可以实现海量存储,线性伸缩、平滑扩容,自动容错、故障转移,高并发,且运维成本低。部署规模,建议部署4-100+台服务器。
Doris3 的主要架构:DT(Data Transfer)负责数据导入、DS(Data Seacher)模块负责数据查询、DM(Data Master)模块负责集群元数据管理,数据则存储在 Armor 分布式 Key-Value 引擎中。Doris3 依赖 ZooKeeper 存储元数据,从而其他模块依赖 ZooKeeper 做到了无状态,进而整个系统能够做到无故障单点。
3. Druid
开源、分布式、面向列式存储的实时分析数据存储系统
Druid的关键特性如下:
4. TiDB
分布式关系型数据库
TiDB 适合高可用、强一致要求较高、数据规模较大
5. Greenplum
关系型分布式数据库
介绍一本OLAP引擎底层原理的书籍
这是一本从OLAP核心概念出发,以Presto为例,从整体执行流程到不同SQL的执行原理,完整呈现OLAP查询的核心流程和OLAP引擎设计思路,并指导读者形成OLAP引擎设计解决方案的专业技术工具书
本书不仅面向初级读者介绍了OLAP查询的基本原理和Presto使用方法,还从源码级剖析了OLAP引擎核心原理,包括SQL查询解析器、优化器、调度器、执行器等核心组件,并将内容扩展到OLAP引擎的常见高性能优化方案上。全书由浅入深,图文并茂,把晦涩难懂的内容讲解得透彻易懂。








暂无评论内容