

表的基本操作(二)
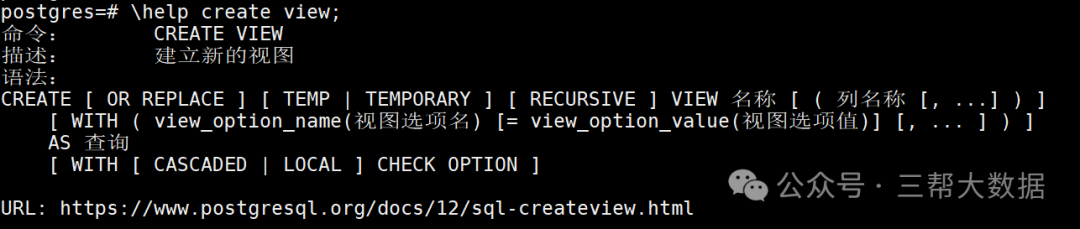
一、视图
跟MySQL的没啥区别,把一些复杂的操作封装起来,还可以隐藏一些敏感数据。
视图对于用户来说,就是一张真实的表,可以直接基于视图查询一张或者多张表的信息。
视图对于开发来说,就是一条SQL语句。
在PGSQL中,简单(单表)的视图是允许写操作的。
但是强烈不推荐对视图进行写操作,虽然PGSQL默认允许(简单的视图)。
写入的时候,其实修改的是表本身
多表视图

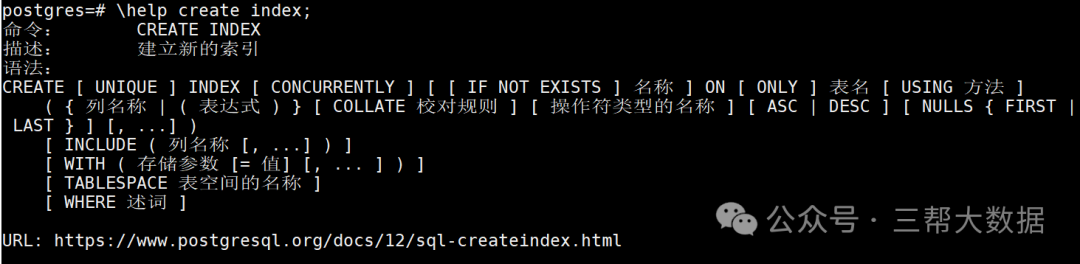
二、索引
1、索引的基本概念
先了解概念和使用
索引是数据库中快速查询数据的方法。
索引能提升查询效率的同时,也会带来一些问题
增加了存储空间
写操作时,花费的时间比较多
索引可以提升效率,甚至还可以给字段做一些约束
2、索引的分类
B-Tree索引:最常用的索引。
Hash索引:跟MySQL类似,做等值判断,范围不可以。
GIN索引:针对字段的多个值的类型,比如数组类型。
3、创建索引看效果
准备大量测试数据,方便查看索引效果。
在没有索引的情况下,先基于name做等值查询,看时间,同时看执行计划。
在有索引的情况下,再基于name做等值查询,看时间,同时看执行计划。
测试GIN索引效果
在没有索引的情况下,基于phone字段做包含查询
给phone字段构建GIN索引,在查询。
三、物化视图
前面说过普通视图,本质就是一个SQL语句,普通的视图并不会本地磁盘存储任何物理。
每次查询视图都是执行这个SQL。效率有点问题。
物化视图从名字上就可以看出来,必然是要持久化一份数据的。使用套路和视图基本一致。这样一来查询物化视图,就相当于查询一张单独的表。相比之前的普通视图,物化视图就不需要每次都查询复杂SQL,每次查询的都是真实的物理存储地址中的一份数据(表)。
物化视图因为会持久化到本地,完全脱离原来的表结构。
而且物化视图是可以单独设置索引等信息来提升物化视图的查询效率。
But,有好处就有坏处,更新时间不太好把控。 如果更新频繁,对数据库压力也不小。 如果更新不频繁,会造成数据存在延迟问题,实时性就不好了。
如果要更新物化视图,可以采用触发器的形式,当原表中的数据被写后,可以通过触发器执行同步物化视图的操作。或者就基于定时任务去完成物化视图的数据同步。
看一下语法:

物化视图如何从原表中进行同步操作。
PostgreSQL中,对物化视图的同步,提供了两种方式,一种是全量更新,另一种是增量更新。
全量更新语法,没什么限制,直接执行,全量更新。
增量更新,增量更新需要一个唯一标识,来判断哪些是增量,同时也会有行数据的版本号约束。








暂无评论内容