

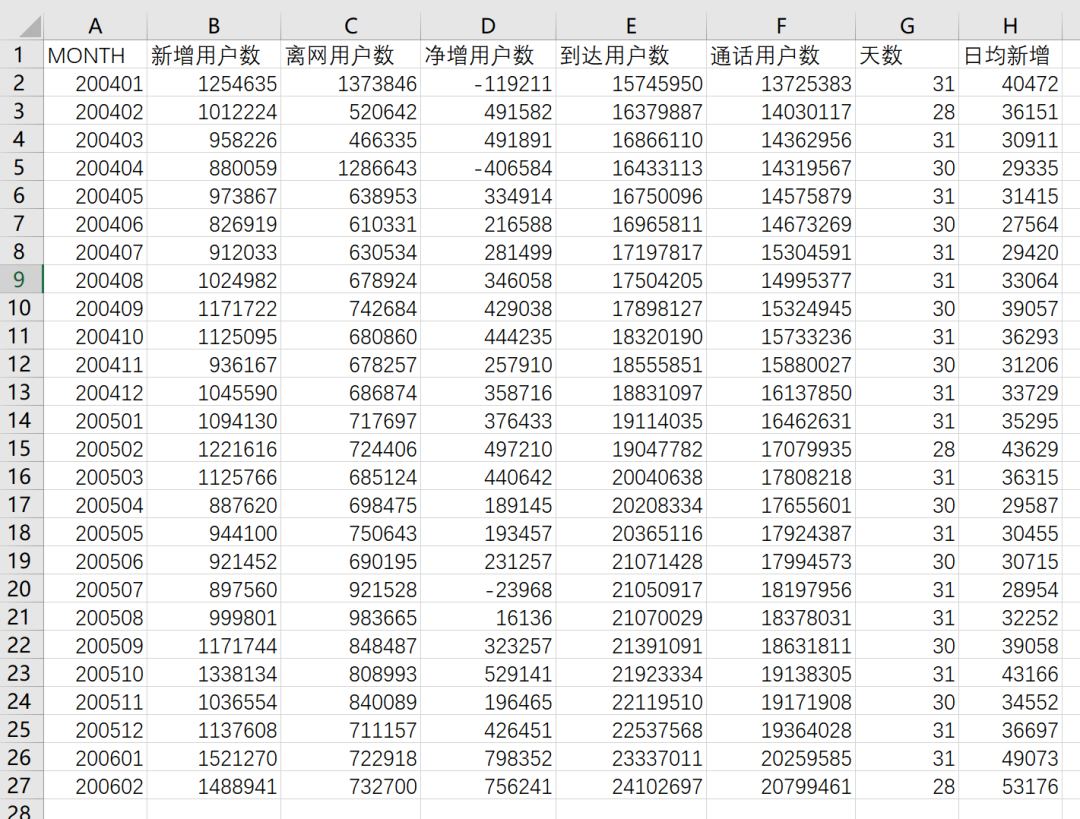
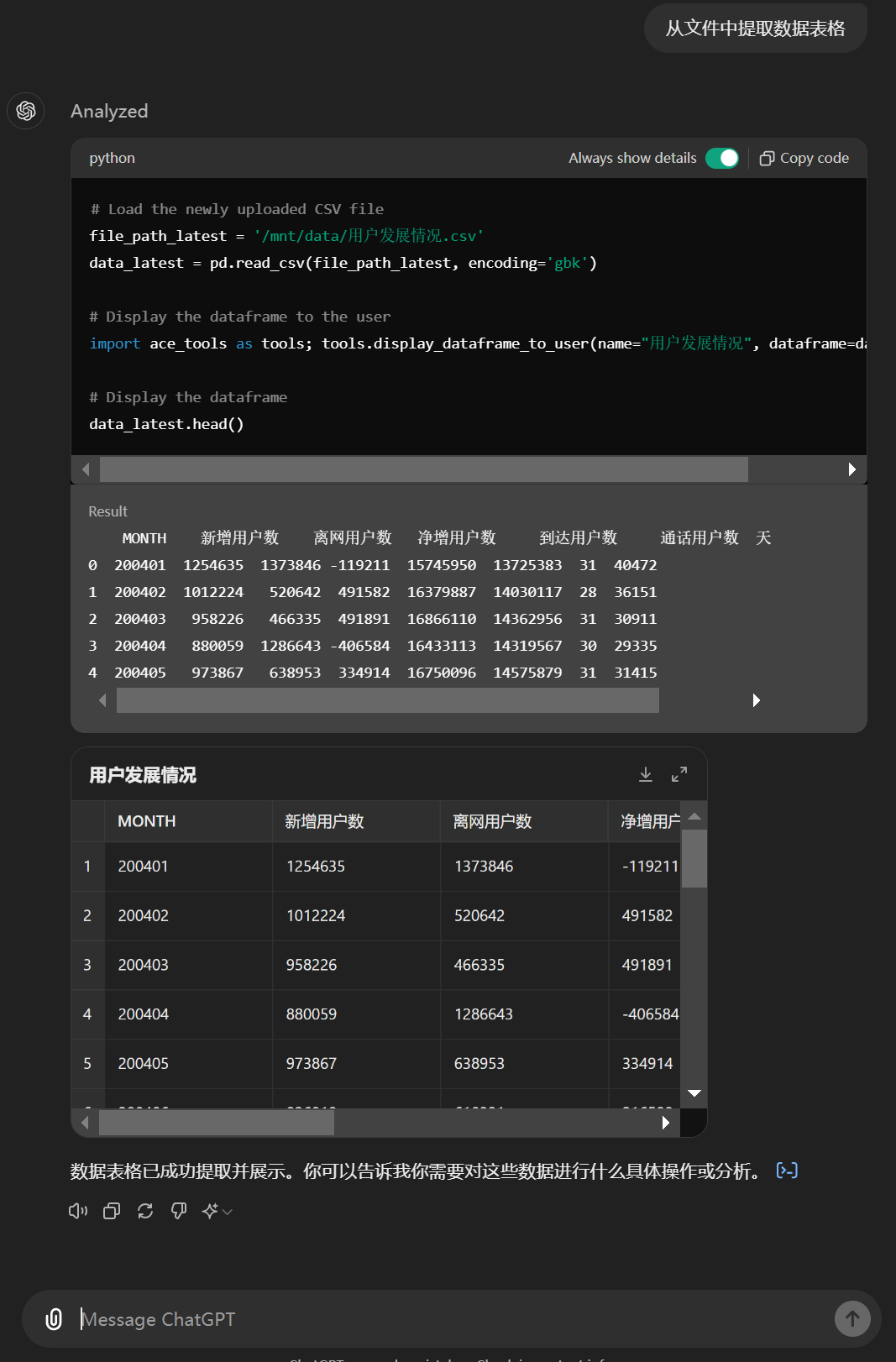
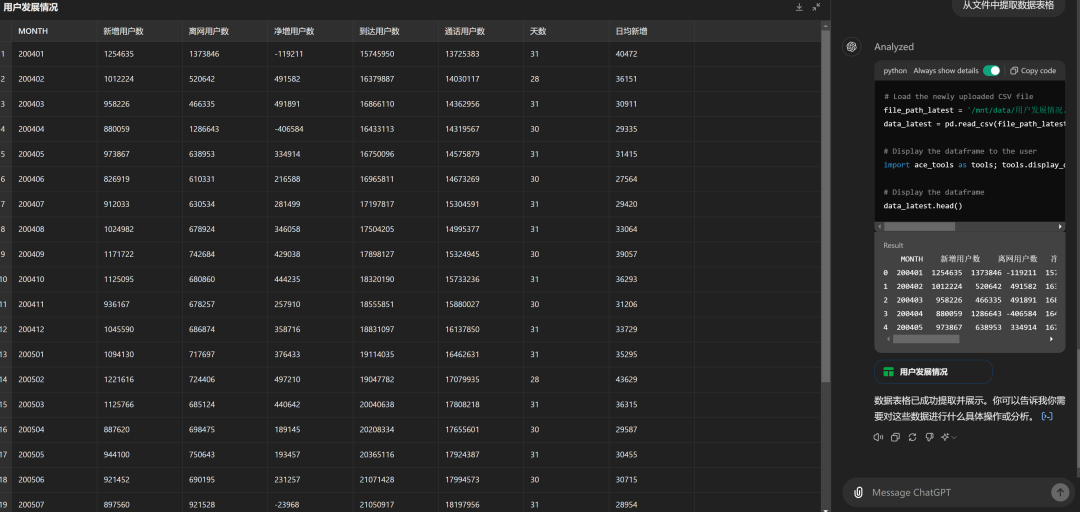
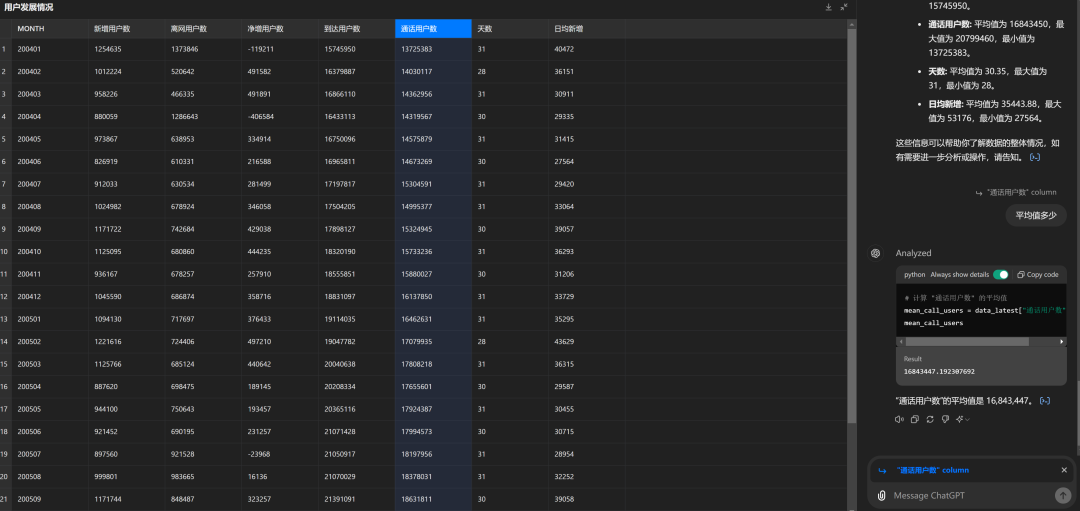


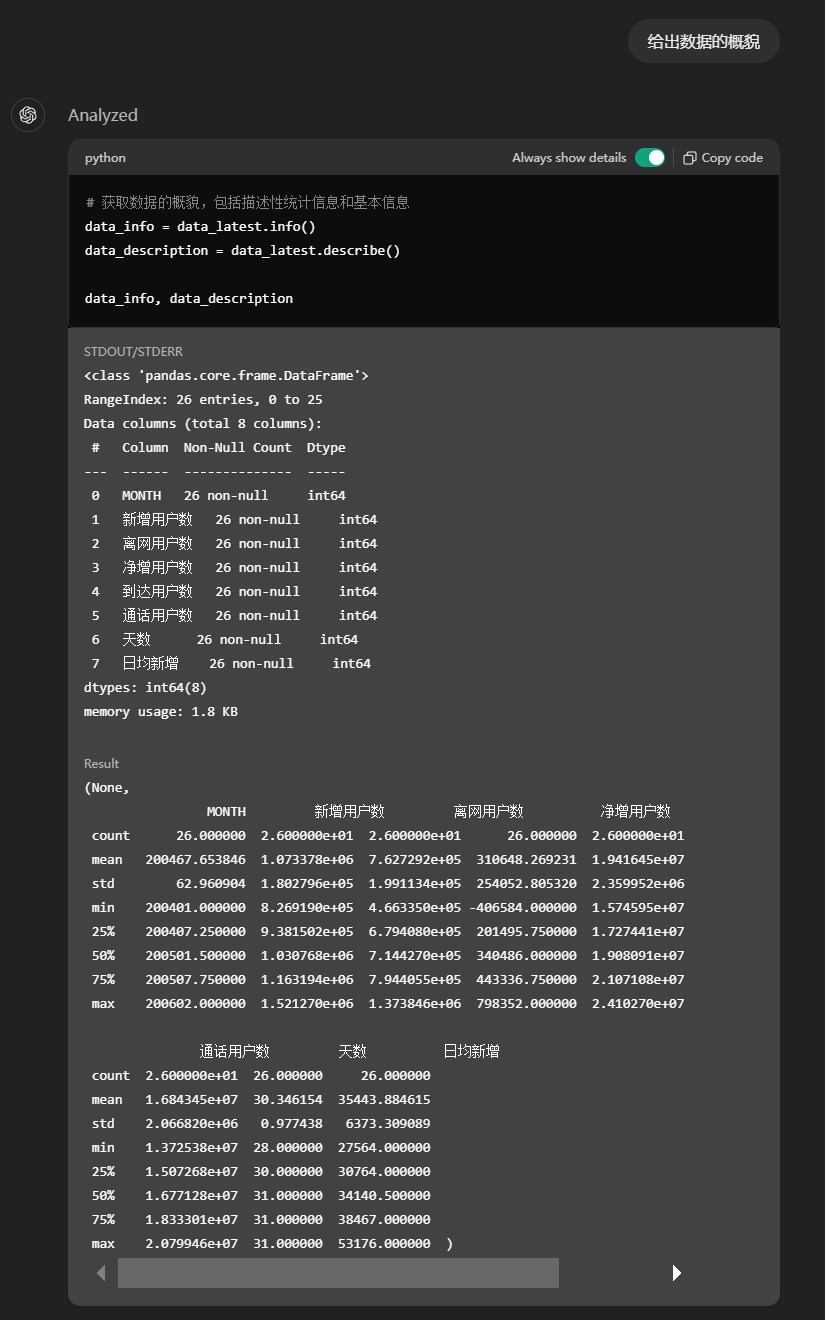



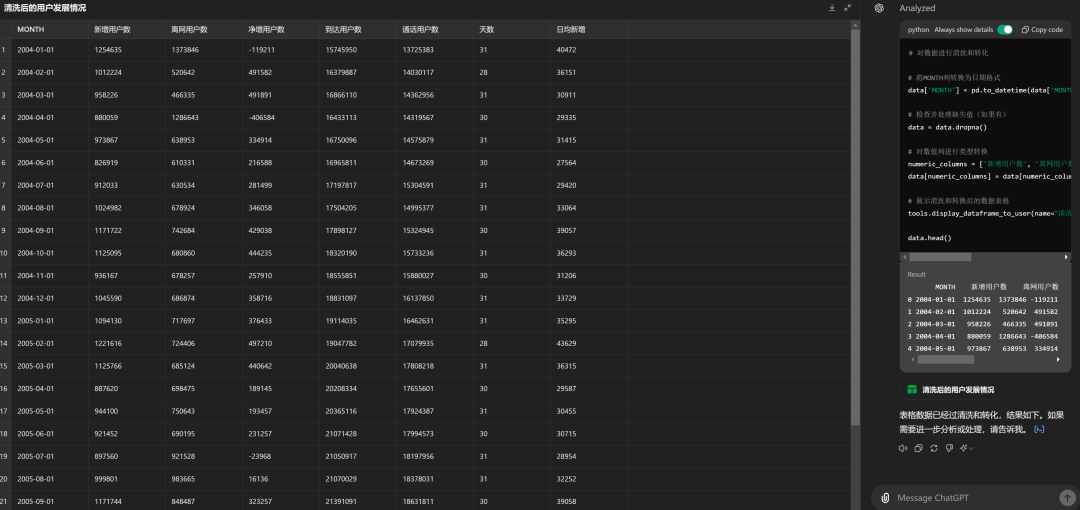


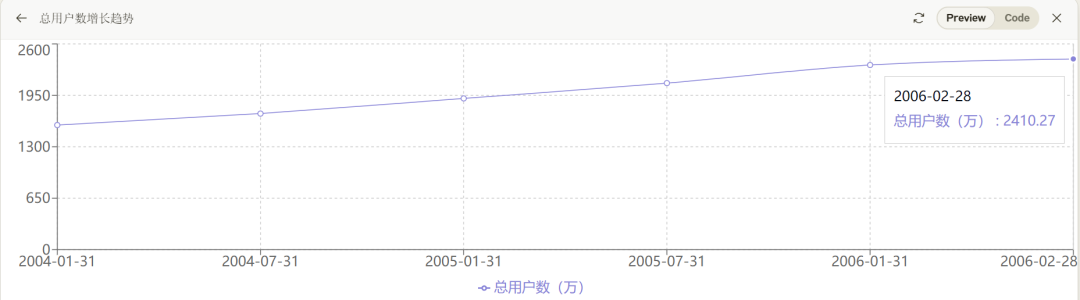
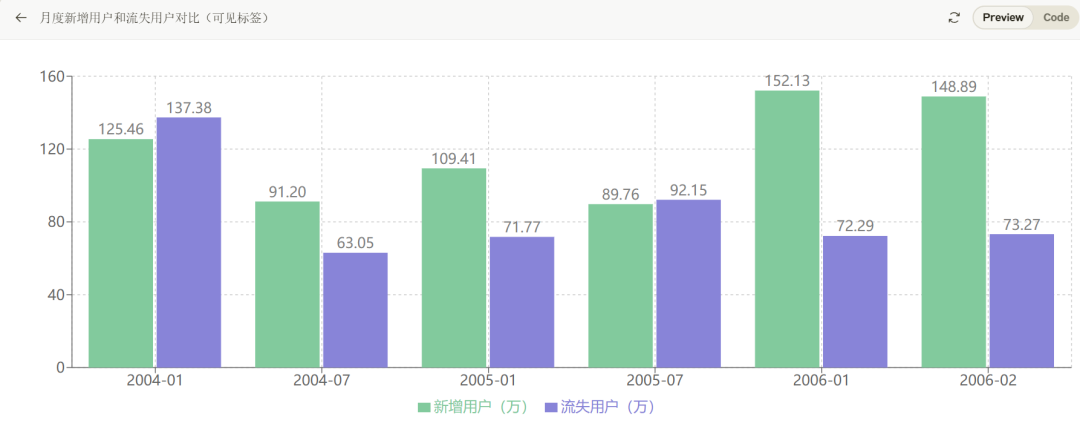
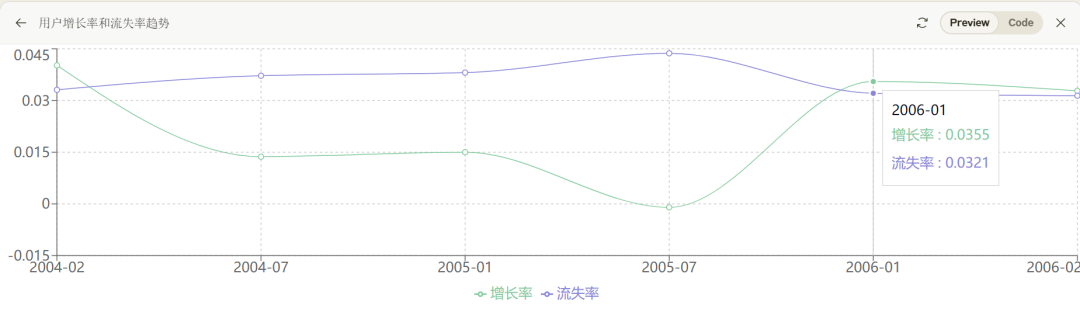


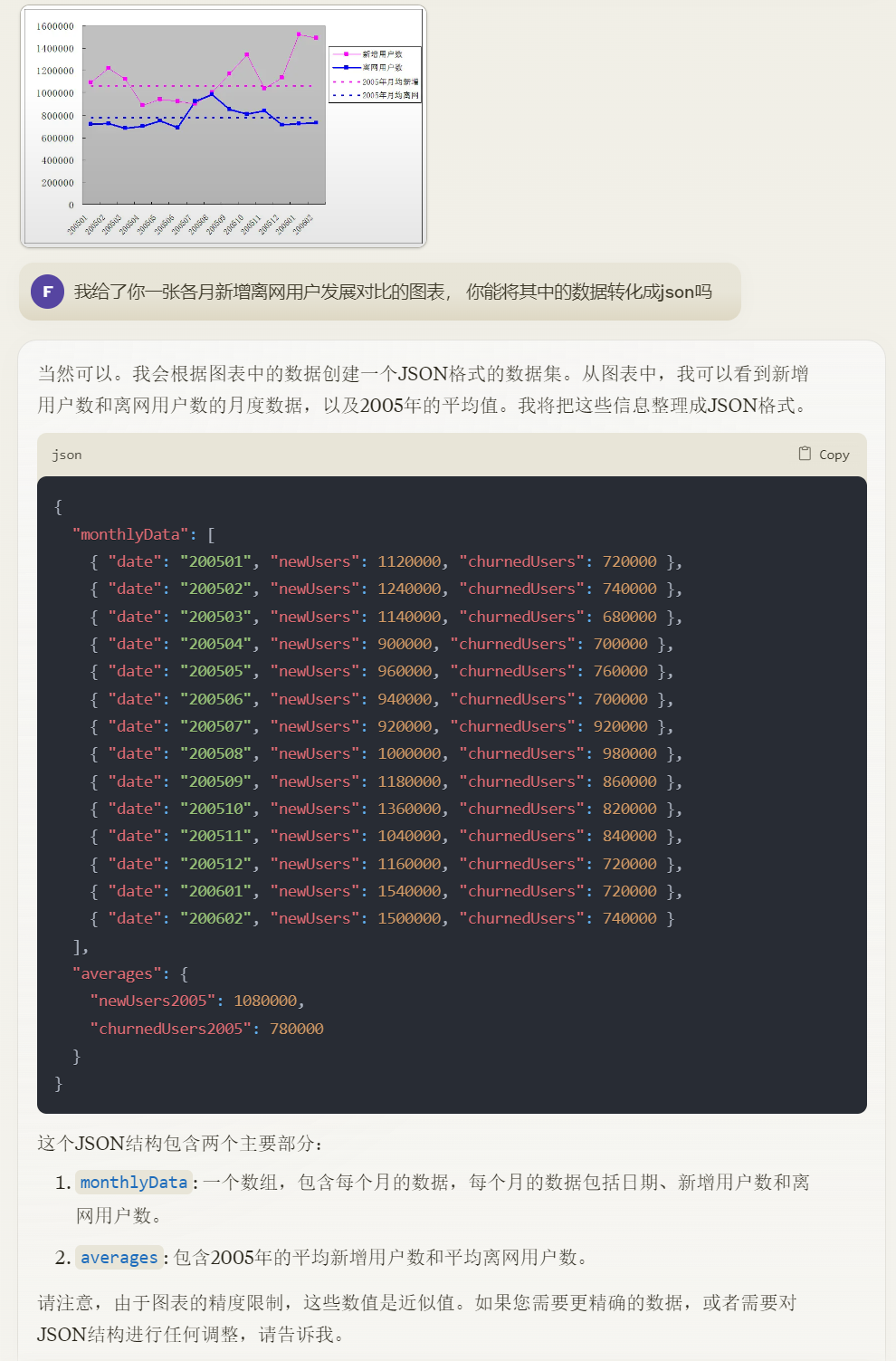

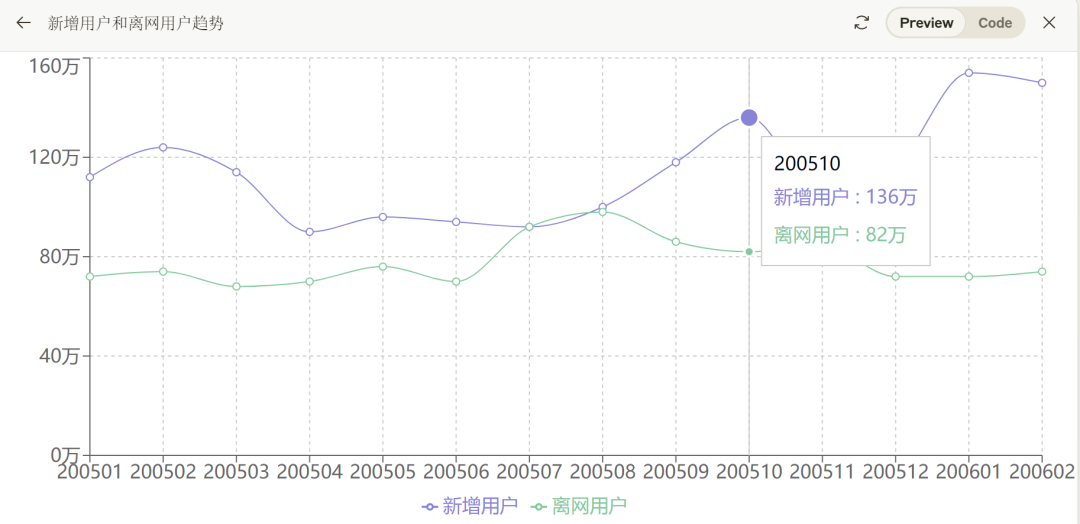
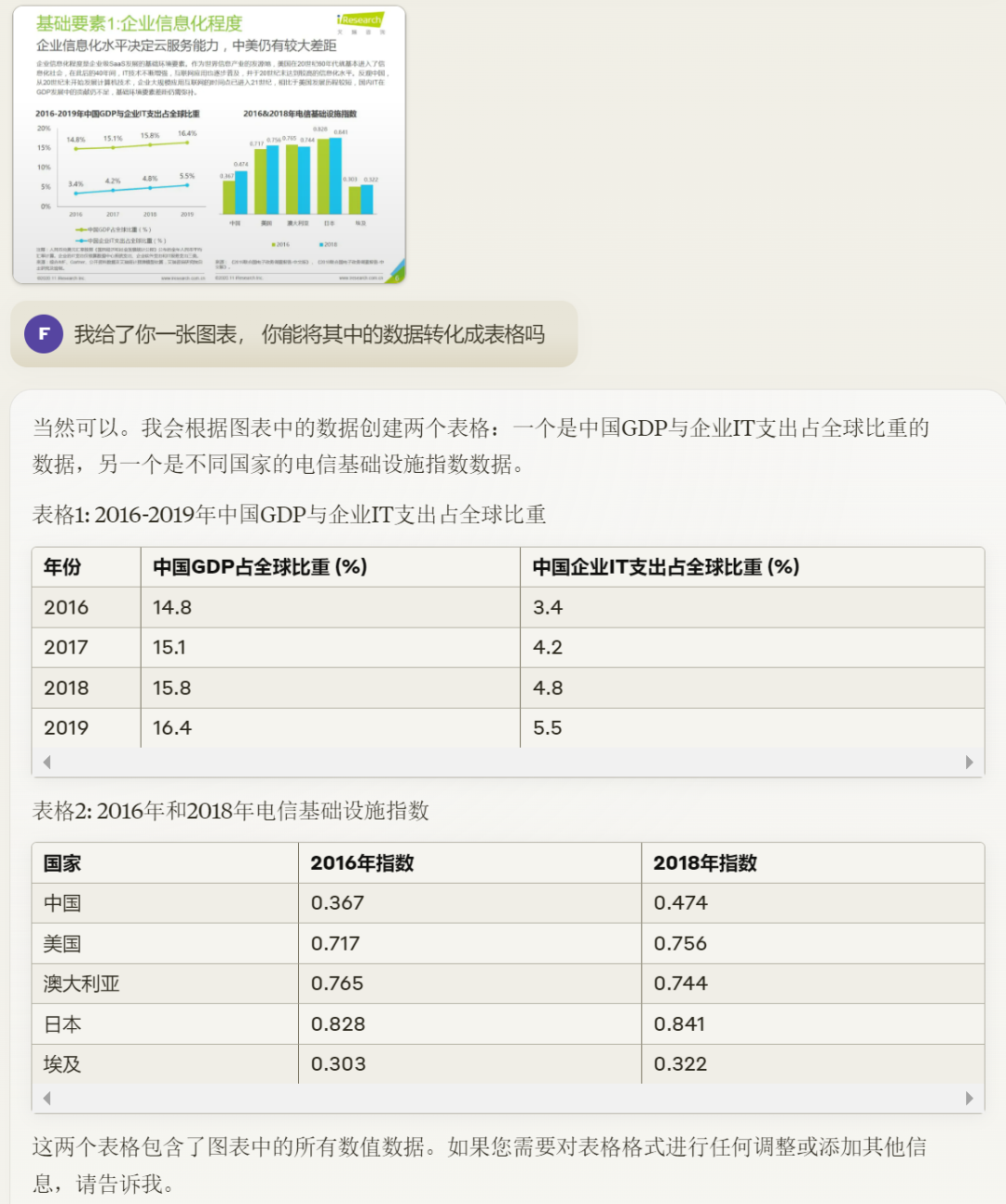
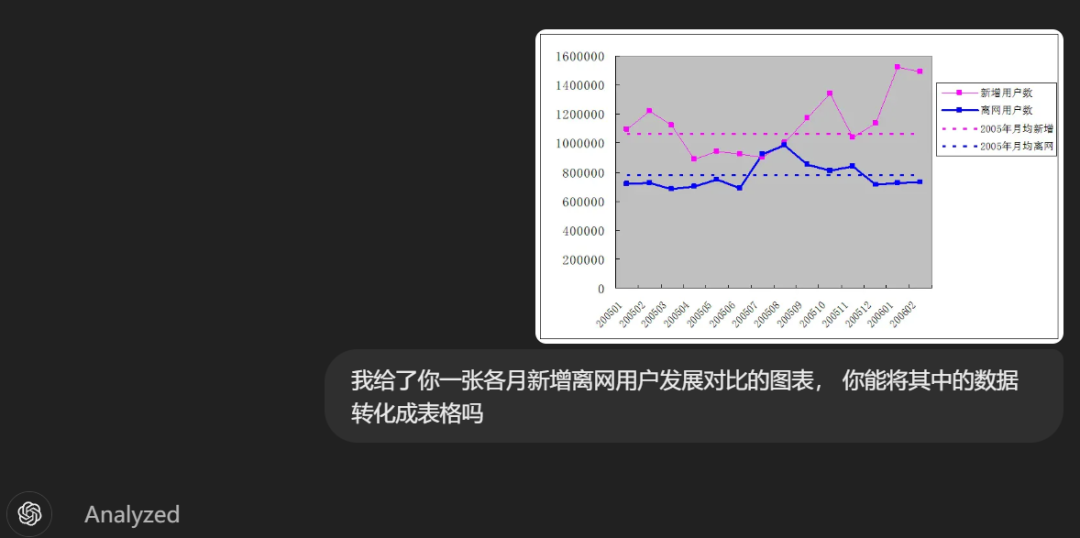
ChatGPT 4o现在也具备了该能力,但距离Claude 3.5有差距,比如针对案例一,其识别出的数据明显不准确,200602的离网用户数被识别为了52000,但肉眼可见的数据应该在70000以上。

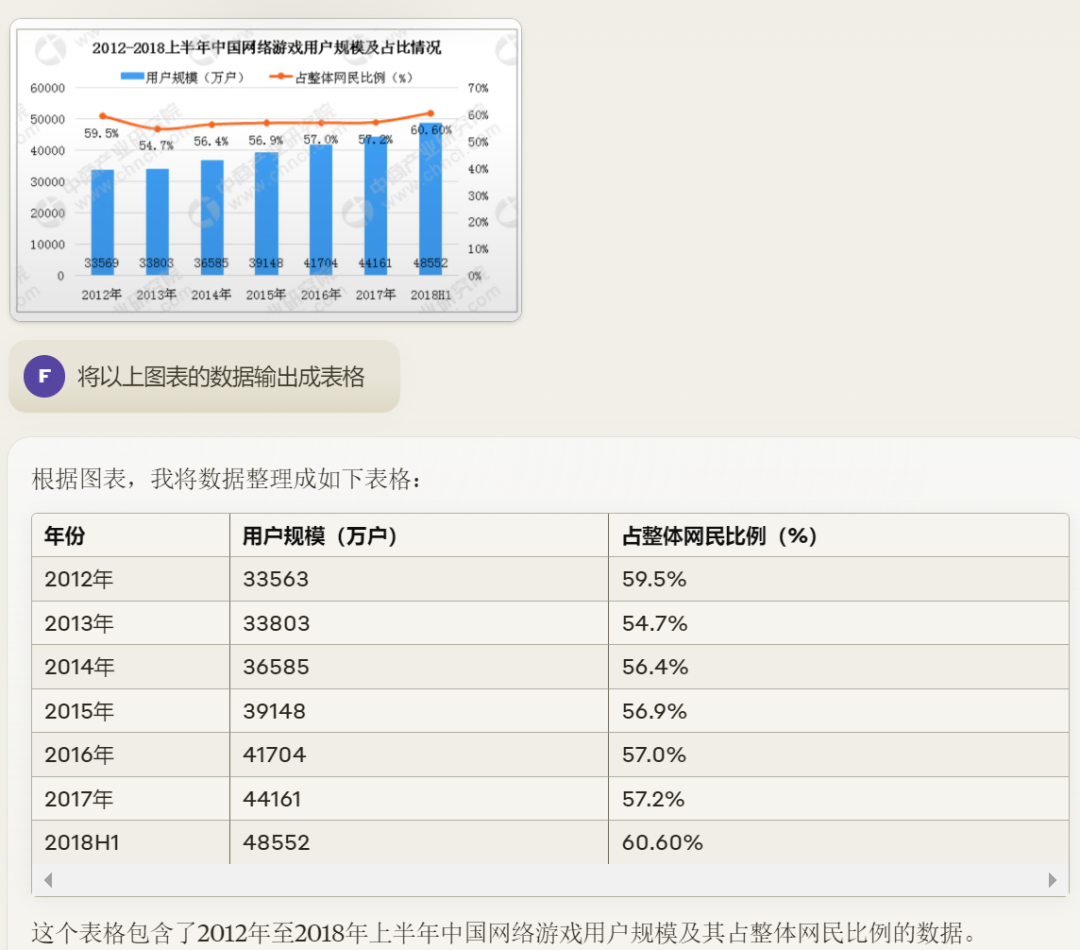
针对案例二,把国家“埃及”识别成了“坦桑尼亚”。
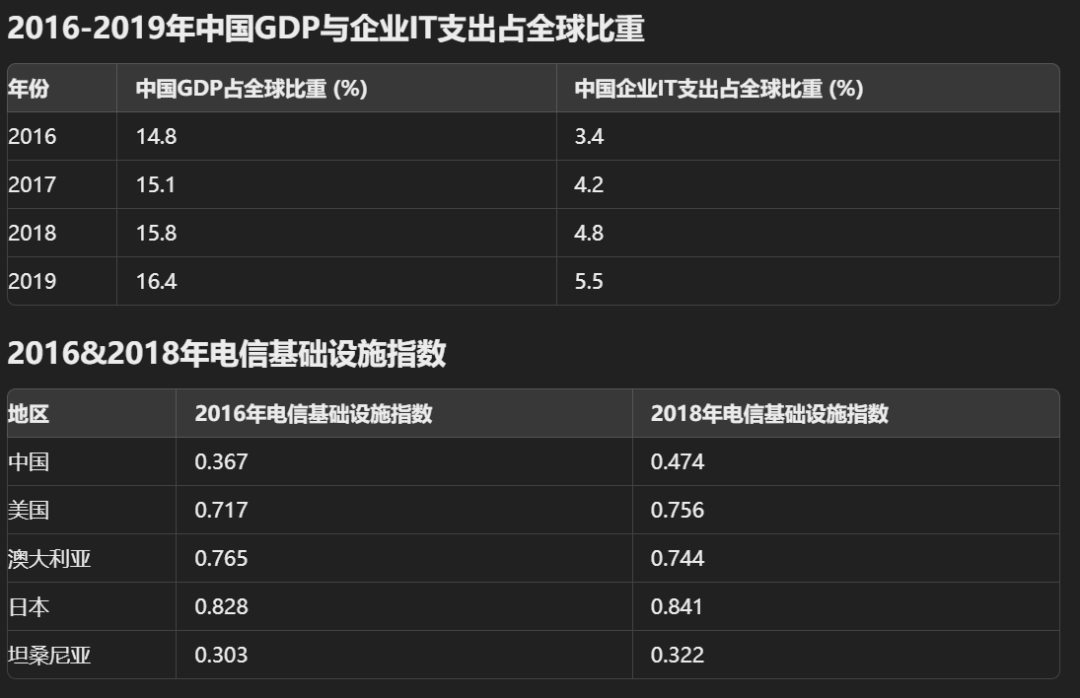
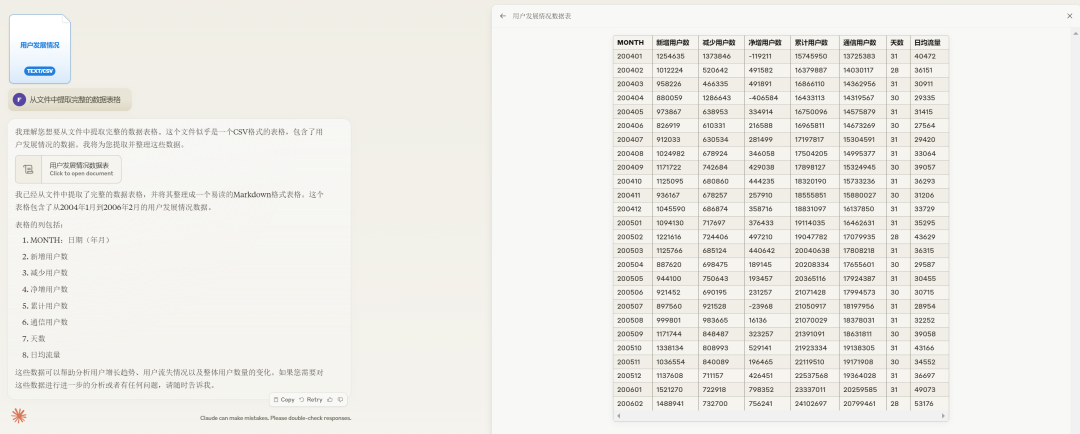
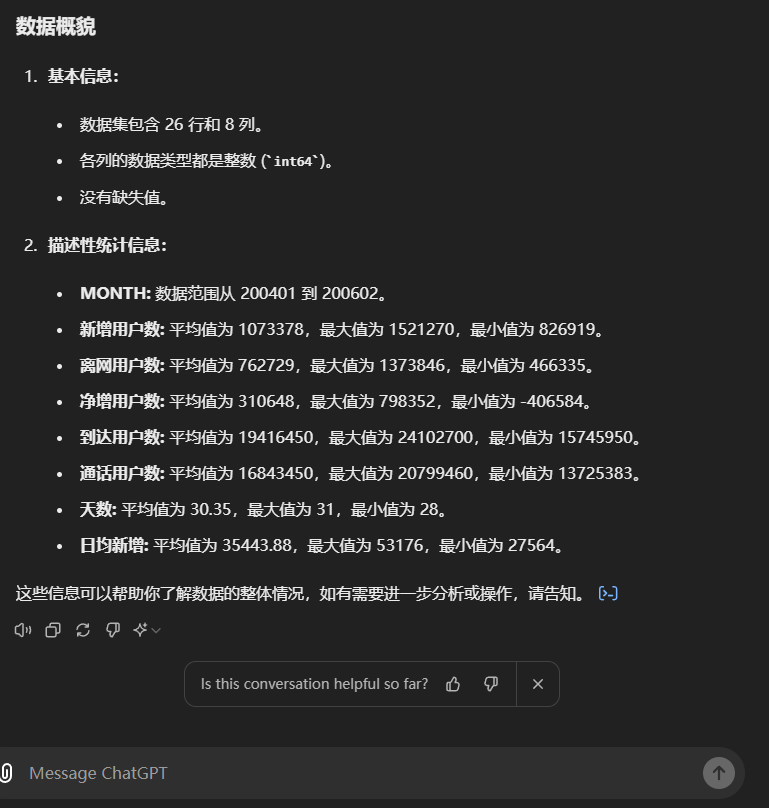
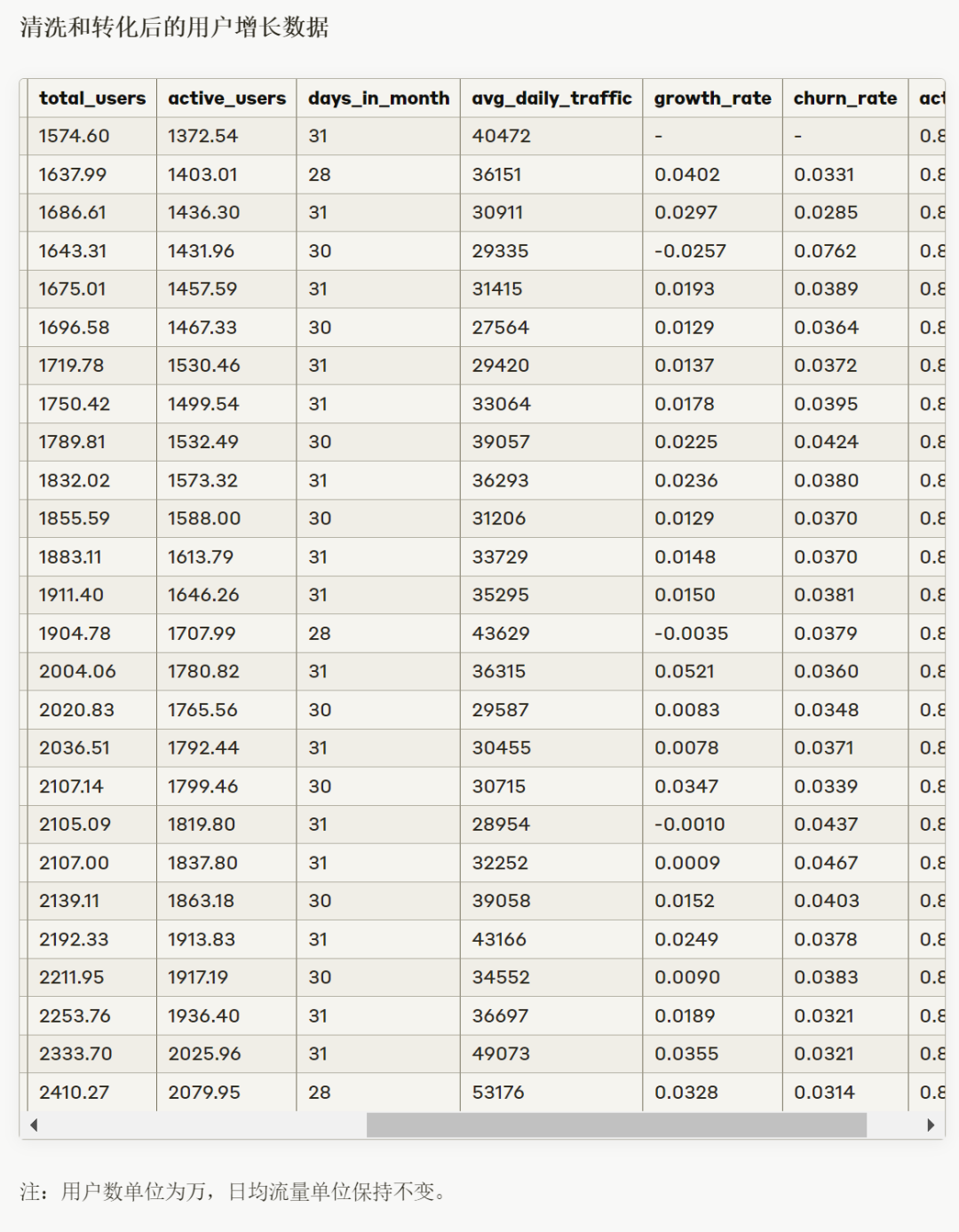
简单的测试结束。应该来讲,两个大模型都表现出了一定的分析潜力,特别是Claude 3.5 Sonnet,已经有初级数据分析师的味道了,特别是Artifacts协作空间很好,可以直接展示动态图表,图表解析功能的实用性也很高。而ChatGPT 4o报错太多,表现差强人意。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END








暂无评论内容