
大数据分享 第4页
排序
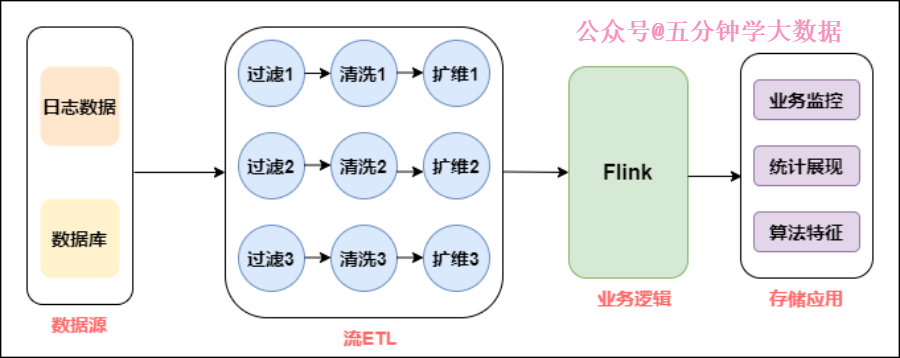
基于Flink构建全场景实时数仓
本文目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才...
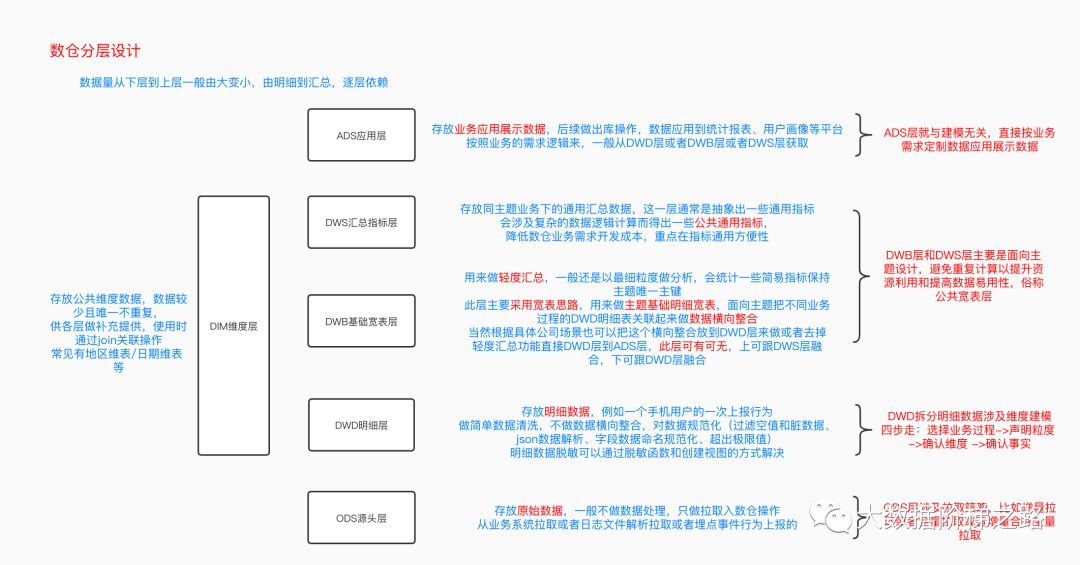
【原创长文】数据仓库指北 聊聊这表那表(附PDF获取)
1. 数据仓库的基础必备问题2. 数据仓库的几种数据表3. 数据仓库分层设计及各层作用4. 数据仓库几种数据模型5. 维度建模 一、 灵魂十二问 Q1:大数据的数据来源? 埋点上报数据业务数据库数据日...


两万字详解性能优化的十种手段(好文收藏)
引言:取与舍 软件设计开发某种意义上是“取”与“舍”的艺术。 关于性能方面,就像建筑设计成抗震9度需要额外的成本一样,高性能软件系统也意味着更高的实现成本,有时候与其他质量属性甚至会...

晋升季,如何减少 50%+ 的答辩材料准备时间、调整心态(个人经验总结)
1.前言 陪伴了小伙伴萌这么久,写的都是一些技术干货,还没有聊过工作上成长的经验。 那么为什么突然要聊这么一个话题呢,有两个原因: 因此萌生了分享一下晋升答辩准备过程的想法,有一些方法...
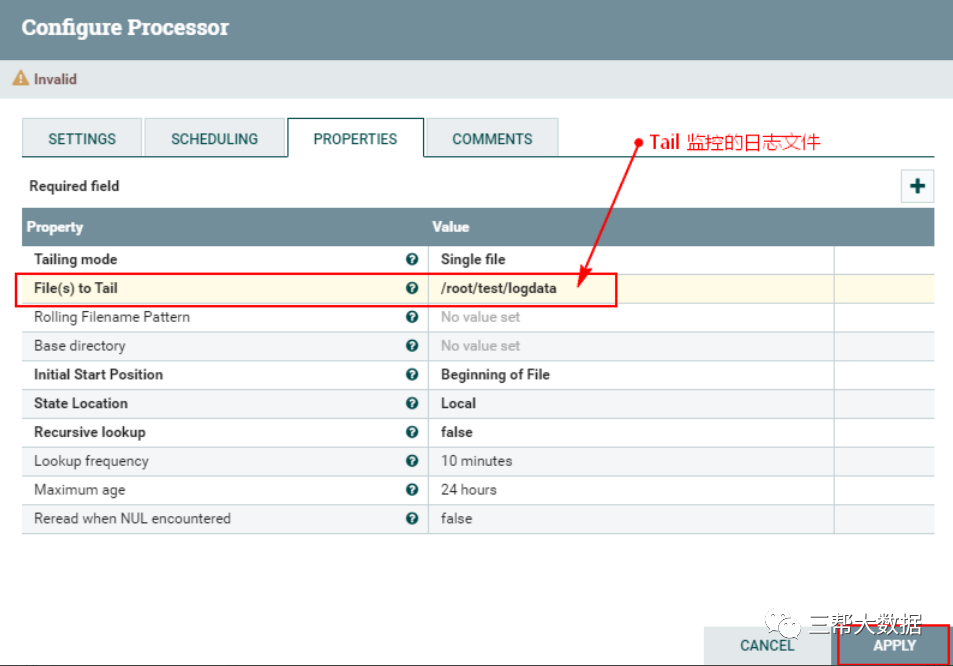
大数据NiFi(二十一):监控日志文件生产到Kafka
监控日志文件生产到Kafka 案例:监控某个目录下的文件内容,将消息生产到Kafka中。 此案例使用到“TailFile”和“PublishKafka_1_0”处理器。 一、配置“TailFile”处理器 创建“TailFile”处理...
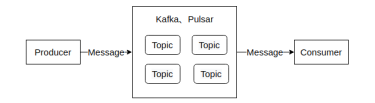
两个优秀的分布式消息流平台:Kafka与Pulsar剖析
本文向读者介绍两个优秀的分布式消息流平台:Kafka与Pulsar。Kafka与Pulsar。 Apache Kafka(简称Kafka) Apache Pulsar(简称Pulsar) 基础功能: (1)消息系统: 优点: 系统解耦:生产者与...
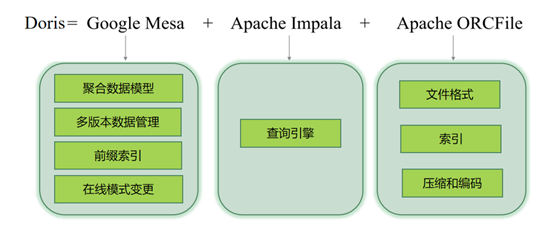
Doris数仓的4大特点,一篇讲明白(文末送Doris书籍)
Doris从设计上来说,融合了Google Mesa的数据存储模型、Apache的ORCFile存储格式、Apache Impala查询引擎和MySQL交互协议,是一个拥有先进技术和先进架构的领先设计产品,如图1所示。 ▲图1 Do...
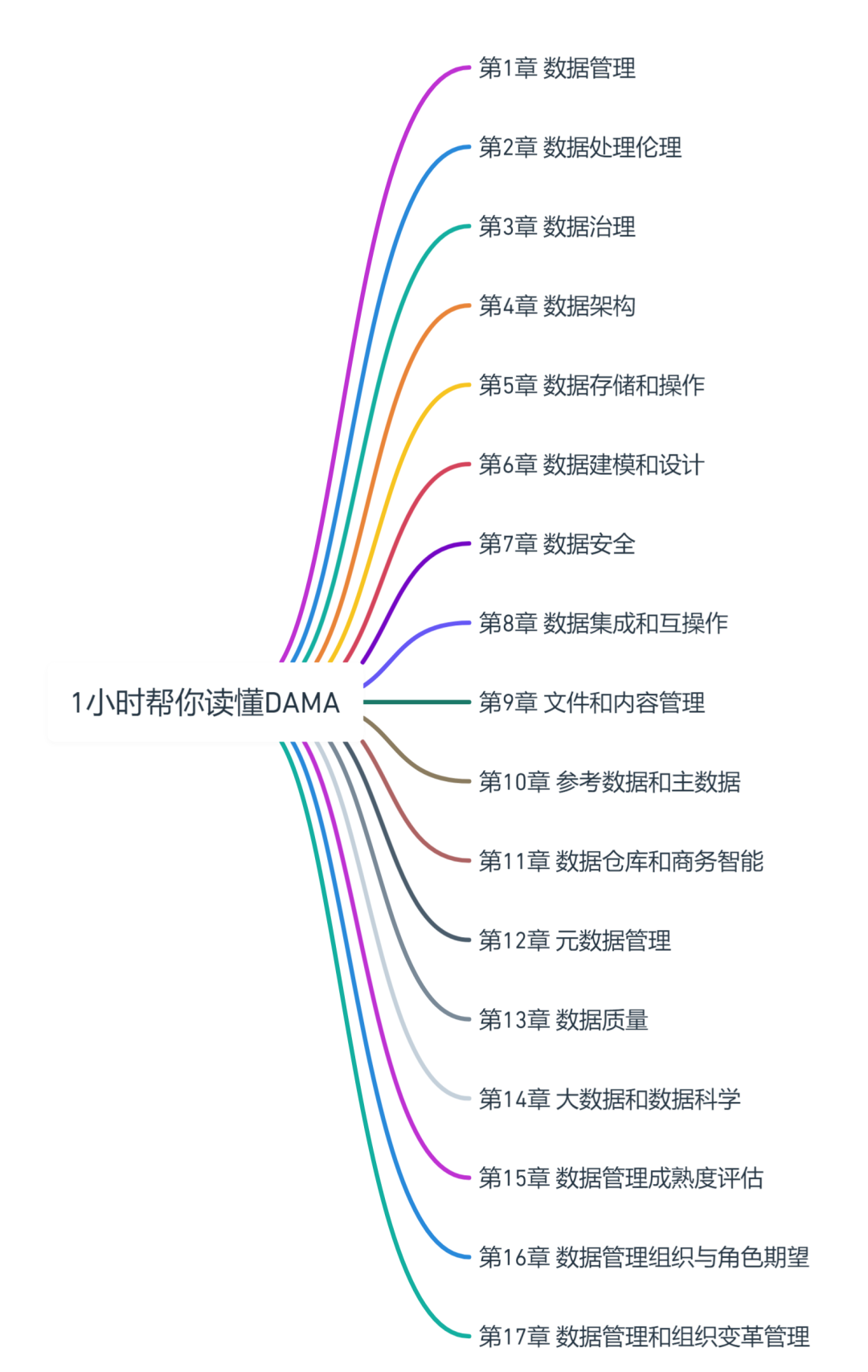
ChatGPT:1小时学会DAMA数据管理(上篇)
满足企业及其利益相关方的信息需求 确保数据的质量、完整性和安全性 保护数据隐私和机密性 防止数据被未经授权或不当访问和使用 确保数据能有效服务于企业增值目标 将数据视为独特属性的资产 重...
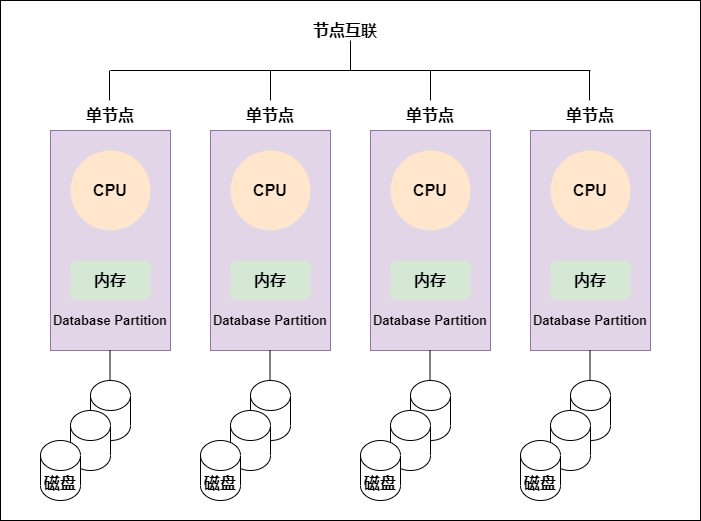
大数据OLAP引擎底层原理
由Facebook开源的Presto是其中的佼佼者,它是以MPP为架构的OLAP引擎中的中流砥柱。如果你学习过Spark、Flink的源码,会惊喜地发现,其中的多个设计思路和实现都参考了Presto,甚至于2019年在北...
