





晋升季,如何减少 50%+ 的答辩材料准备时间、调整心态(个人经验总结)
1.前言 陪伴了小伙伴萌这么久,写的都是一些技术干货,还没有聊过工作上成长的经验。 那么为什么突然要聊这么一个话题呢,有两个原因: 因此萌生了分享一下晋升答辩准备过程的想法,有一些方法...
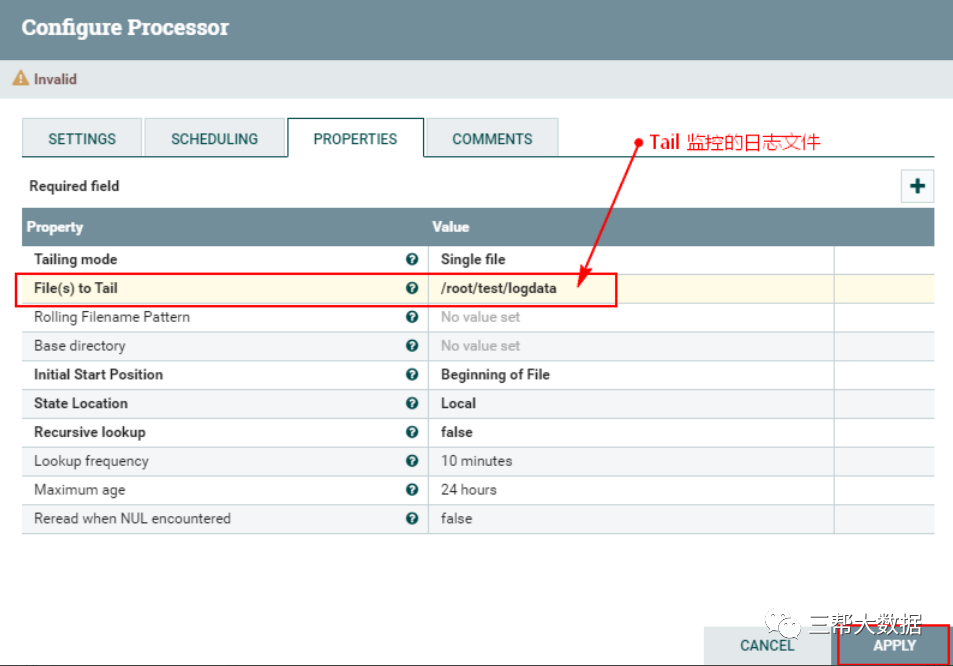
大数据NiFi(二十一):监控日志文件生产到Kafka
监控日志文件生产到Kafka 案例:监控某个目录下的文件内容,将消息生产到Kafka中。 此案例使用到“TailFile”和“PublishKafka_1_0”处理器。 一、配置“TailFile”处理器 创建“TailFile”处理...
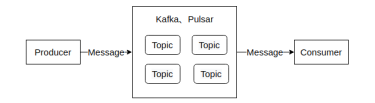
两个优秀的分布式消息流平台:Kafka与Pulsar剖析
本文向读者介绍两个优秀的分布式消息流平台:Kafka与Pulsar。Kafka与Pulsar。 Apache Kafka(简称Kafka) Apache Pulsar(简称Pulsar) 基础功能: (1)消息系统: 优点: 系统解耦:生产者与...
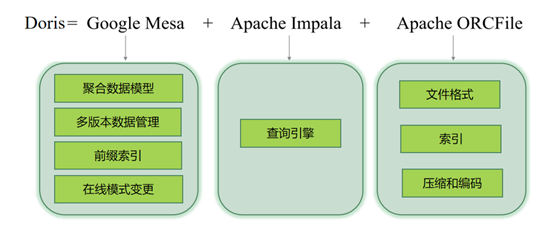
Doris数仓的4大特点,一篇讲明白(文末送Doris书籍)
Doris从设计上来说,融合了Google Mesa的数据存储模型、Apache的ORCFile存储格式、Apache Impala查询引擎和MySQL交互协议,是一个拥有先进技术和先进架构的领先设计产品,如图1所示。 ▲图1 Do...
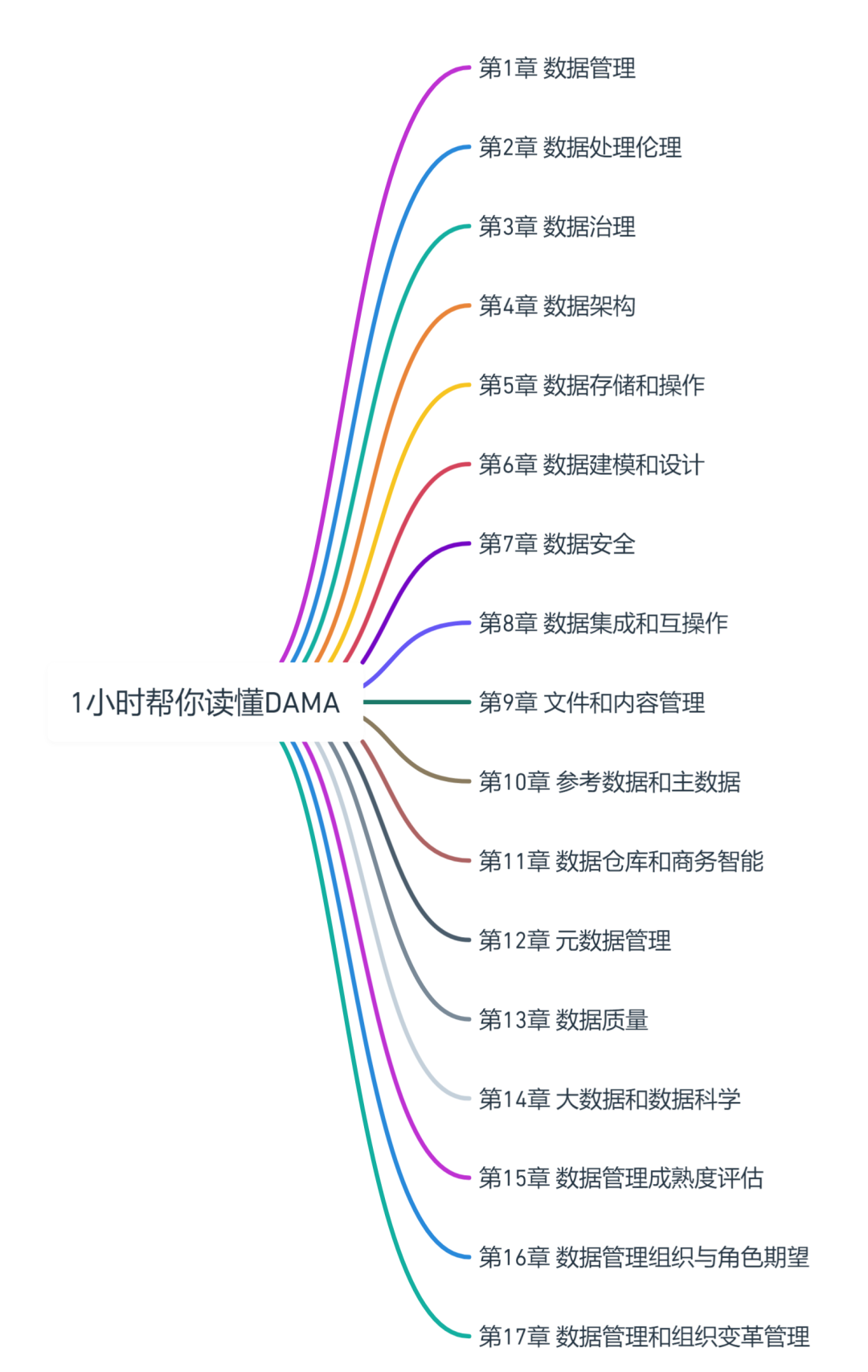
ChatGPT:1小时学会DAMA数据管理(上篇)
满足企业及其利益相关方的信息需求 确保数据的质量、完整性和安全性 保护数据隐私和机密性 防止数据被未经授权或不当访问和使用 确保数据能有效服务于企业增值目标 将数据视为独特属性的资产 重...
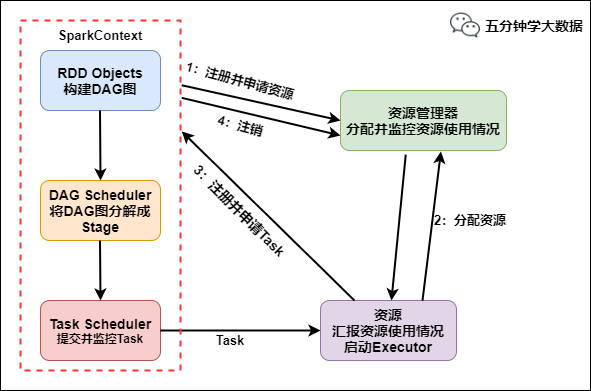
Spark底层执行原理详细解析
Spark简介 大规模数据处理高容错性高可伸缩性 Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执...
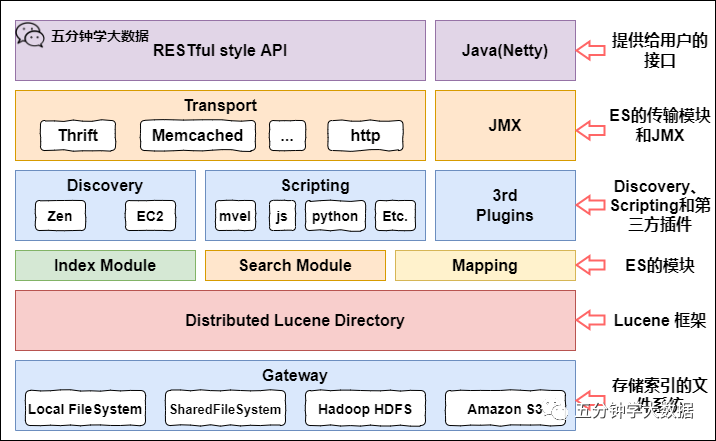
Elasticsearch 保姆级教程(文末送书)
Elasticsearch 介绍 1. Elasticsearch Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎...

ChatGPT:1小时学会DAMA数据管理(下)
ChatGPT:1小时学会DAMA数据管理(上) ChatGPT:1小时学会DAMA数据管理(中) 第12章 元数据管理 (一)数据的故事 某大型零售连锁企业决定实施元数据管理项目,以提升数据治理能力和决策效率...
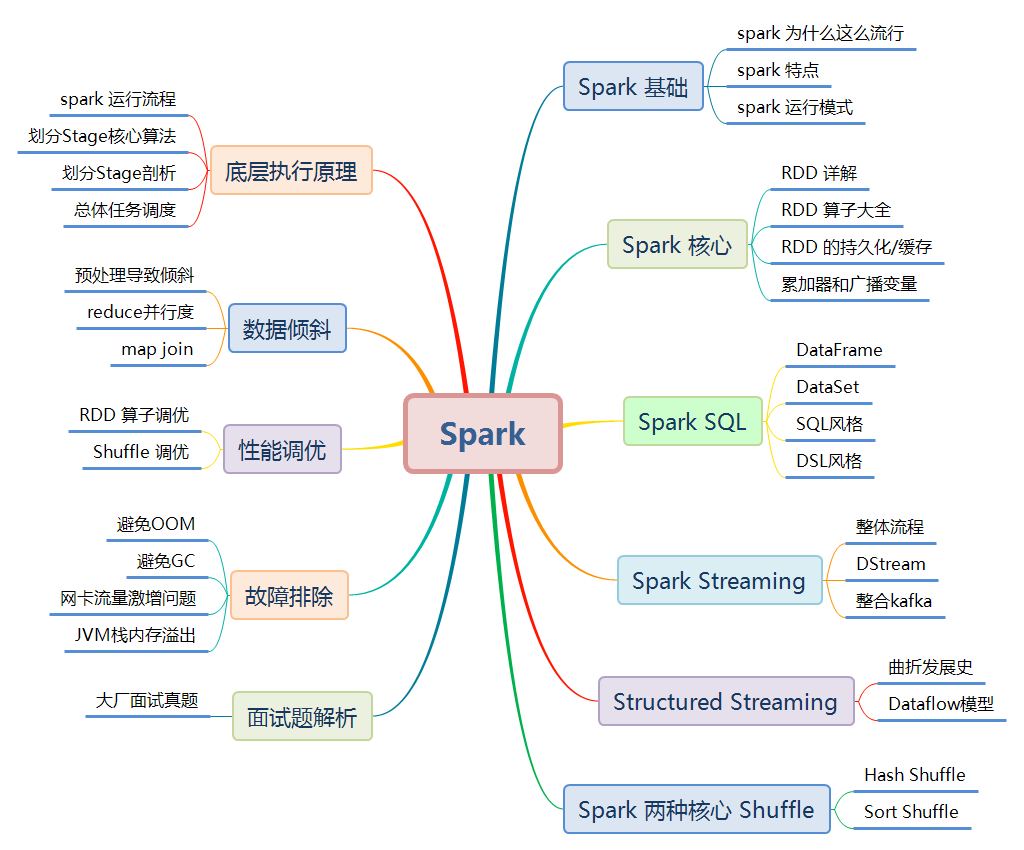
Spark知识体系五万字讲解,学习与面试收藏这篇就够了!
一、Spark 基础二、Spark Core三、Spark SQL四、Spark Streaming五、Structured Streaming六、Spark 两种核心 Shuffle七、Spark 底层执行原理八、Spark 数据倾斜九、Spark 性能调优十、Spark 故...

【果总谈BI】数据归IT,分析归业务
企业知识开源首席布道师陈果的答案是:数据归IT,分析归业务。即IT部门主要负责管理好数据、提供好工具,分析本质上是业务要做的事情。 为何会有这样的结论?陈果在「敏捷·创变——2024观远数...
