

Spark简介
大规模数据处理高容错性高可伸缩性
Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执行原理。
Spark运行流程
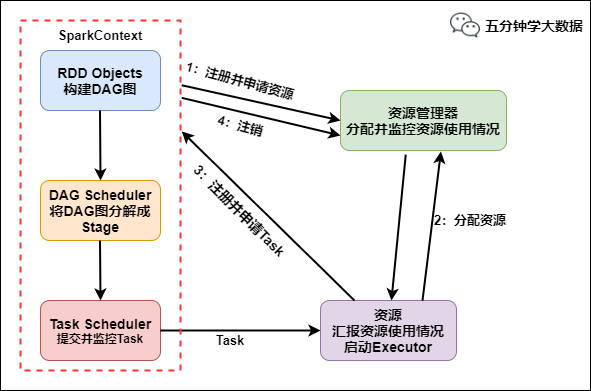
图片说明: Spark运行流程
具体运行流程如下:
SparkContext 向资源管理器注册并向资源管理器申请运行Executor
资源管理器分配Executor,然后资源管理器启动Executor
Executor 发送心跳至资源管理器
SparkContext 构建DAG有向无环图
将DAG分解成Stage(TaskSet)
把Stage发送给TaskScheduler
Executor 向 SparkContext 申请 Task
TaskScheduler 将 Task 发送给 Executor 运行
同时 SparkContext 将应用程序代码发放给 Executor
Task 在 Executor 上运行,运行完毕释放所有资源
1. 从代码角度看DAG图的构建
上述代码的DAG图如下所示:
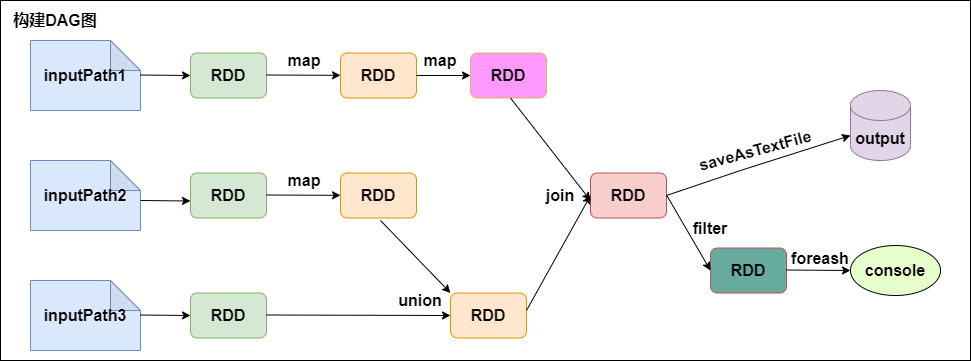
图片说明: 构建DAG图
Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是如上图所示的DAG。
Spark 的计算发生在RDD的Action操作,而对Action之前的所有Transformation,Spark只是记录下RDD生成的轨迹,而不会触发真正的计算
2. 将DAG划分为Stage核心算法
一个Application可以有多个job多个Stage:
Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:
Stage划分的依据就是宽依赖
窄依赖宽依赖
核心算法:回溯算法
从后往前回溯/反向解析,遇到窄依赖加入本Stage,遇见宽依赖进行Stage切分。
从后往前推
3. 将DAG划分为Stage剖析
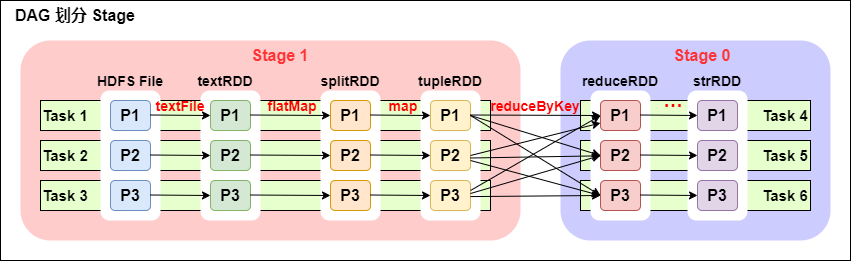
图片说明: DAG划分Stage
一个Spark程序可以有多个DAG(有几个Action,就有几个DAG,上图最后只有一个Action(图中未表现),那么就是一个DAG)
一个DAG可以有多个Stage(根据宽依赖/shuffle进行划分)。
同一个Stage可以有多个Task并行执行task数=分区数
可以看到这个DAG中只reduceByKey操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage。
从textFile到flatMap到map都是窄依赖,这几步操作可以形成一个流水线操作,通过flatMap操作生成的partition可以不用等待整个RDD计算结束,而是继续进行map操作,这样大大提高了计算的效率
4. 提交Stages
调度阶段的提交,最终会被转换成一个任务集的提交,DAGScheduler通过TaskScheduler接口提交任务集,这个任务集最终会触发TaskScheduler构建一个TaskSetManager的实例来管理这个任务集的生命周期,对于DAGScheduler来说,提交调度阶段的工作到此就完成了。
而TaskScheduler的具体实现则会在得到计算资源的时候,进一步通过TaskSetManager调度具体的任务到对应的Executor节点上进行运算。
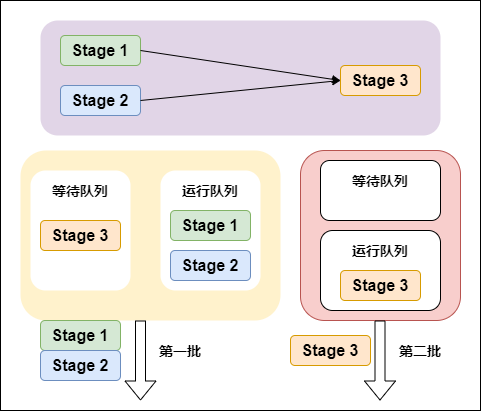
5. 监控Job、Task、Executor
DAGScheduler监控Job与Task:
要保证相互依赖的作业调度阶段能够得到顺利的调度执行,DAGScheduler需要监控当前作业调度阶段乃至任务的完成情况。
这通过对外暴露一系列的回调函数来实现的,对于TaskScheduler来说,这些回调函数主要包括任务的开始结束失败、任务集的失败,DAGScheduler根据这些任务的生命周期信息进一步维护作业和调度阶段的状态信息。
DAGScheduler监控Executor的生命状态:
如果某一个Executor崩溃了,则对应的调度阶段任务集的ShuffleMapTask的输出结果也将标志为不可用,这将导致对应任务集状态的变更,进而重新执行相关计算任务,以获取丢失的相关数据
6. 获取任务执行结果
结果DAGScheduler:
一个具体的任务在Executor中执行完毕后,其结果需要以某种形式返回给DAGScheduler,根据任务类型的不同,任务结果的返回方式也不同。
两种结果,中间结果与最终结果:
对于FinalStage所对应的任务,返回给DAGScheduler的是运算结果本身。
而对于中间调度阶段对应的任务ShuffleMapTask,返回给DAGScheduler的是一个MapStatus里的相关存储信息,而非结果本身,这些存储位置信息将作为下一个调度阶段的任务获取输入数据的依据。
DirectTaskResult与IndirectTaskResult
根据任务结果大小的不同,ResultTask返回的结果又分为两类:
如果结果足够小,则直接放在DirectTaskResult对象内中。
如果超过特定尺寸则在Executor端会将DirectTaskResult先序列化,再把序列化的结果作为一个数据块存放在BlockManager中,然后将BlockManager返回的BlockID放在IndirectTaskResult对象中返回给TaskScheduler,TaskScheduler进而调用TaskResultGetter将IndirectTaskResult中的BlockID取出并通过BlockManager最终取得对应的DirectTaskResult。
7. 任务调度总体诠释
一张图说明任务总体调度:
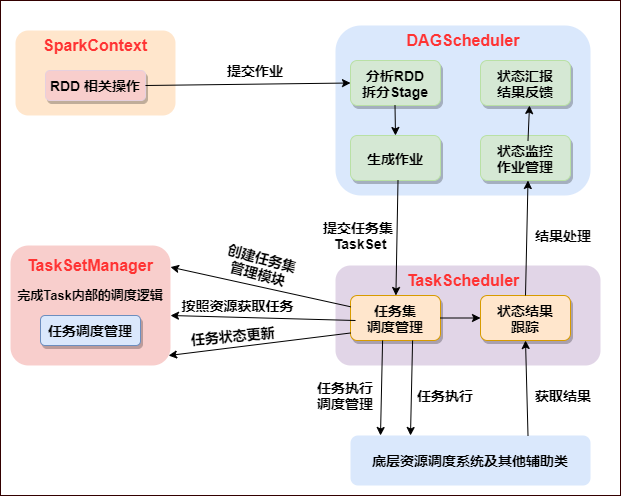
图片说明: 任务总体调度
Spark运行架构特点
1. Executor进程专属
每个Application获取专属的Executor进程,该进程在Application期间一直驻留,并以多线程方式运行Tasks
Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。如图所示:
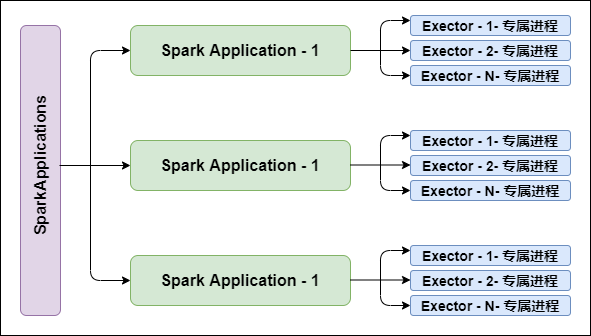
图片说明: Executor进程专属
2. 支持多种资源管理器
Spark与资源管理器无关,只要能够获取Executor进程,并能保持相互通信就可以了。
Spark支持资源管理器包含:Standalone、On Mesos、On YARN、Or On EC2。如图所示:
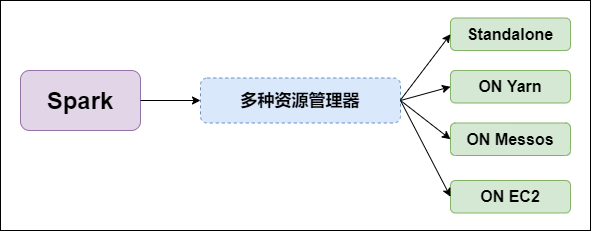
图片说明: 支持多种资源管理器
3. Job提交就近原则
提交SparkContext的Client应该靠近Worker节点(运行Executor的节点)
不要远离Worker运行SparkContext
如图所示:
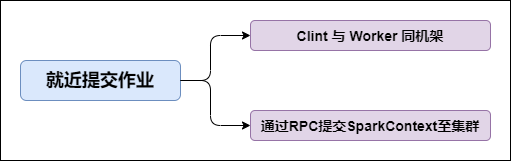
图片说明: Job提交就近原则
4. 移动程序而非移动数据的原则执行
移动程序而非移动数据的原则执行,Task采用了数据本地性和推测执行的优化机制
关键方法:taskIdToLocations、getPreferedLocations。
如图所示:







暂无评论内容