

实时数仓演进&方案对比选型落地
==================================================

【作者介绍】王磊,阿里云 MVP,华院计算技术总监。
著有:《图解 Spark 大数据快速分析实战》;《offer 来了:Java 面试核心知识点精讲(原理篇)》;《offer 来了:Java 面试核心知识点精讲(架构篇)》。
01
文章概览(一至五)
✦
一、为何需要实时数仓架构
二、数仓如何分层&各层用途
三、数仓分层的必要性
四、从Lambda架构说起
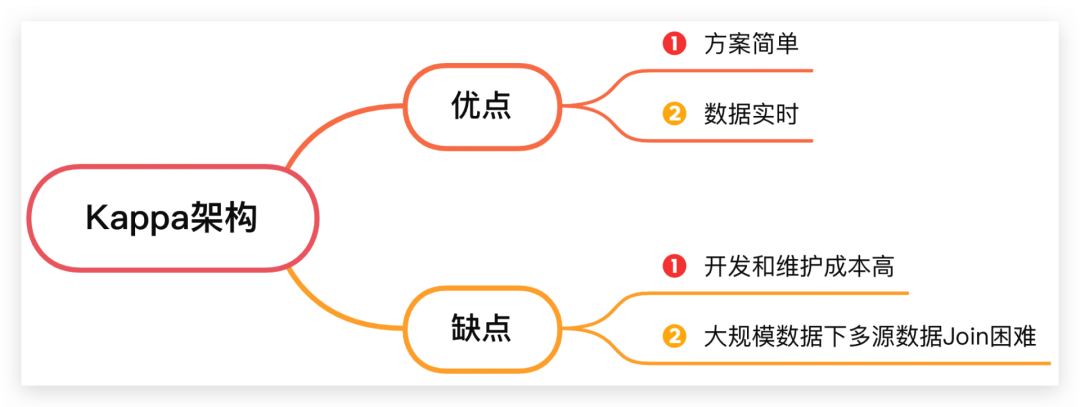
五、Kappa架构解决哪些问题
02
文章概览(六至九)
✦
六、深入实时数仓架构[五种方案讲解]
七、具体选型建议
八、大厂方案分享
九、结语&延伸思考
一、为何需要实时数仓架构

二、数仓如何分层 & 各层用途
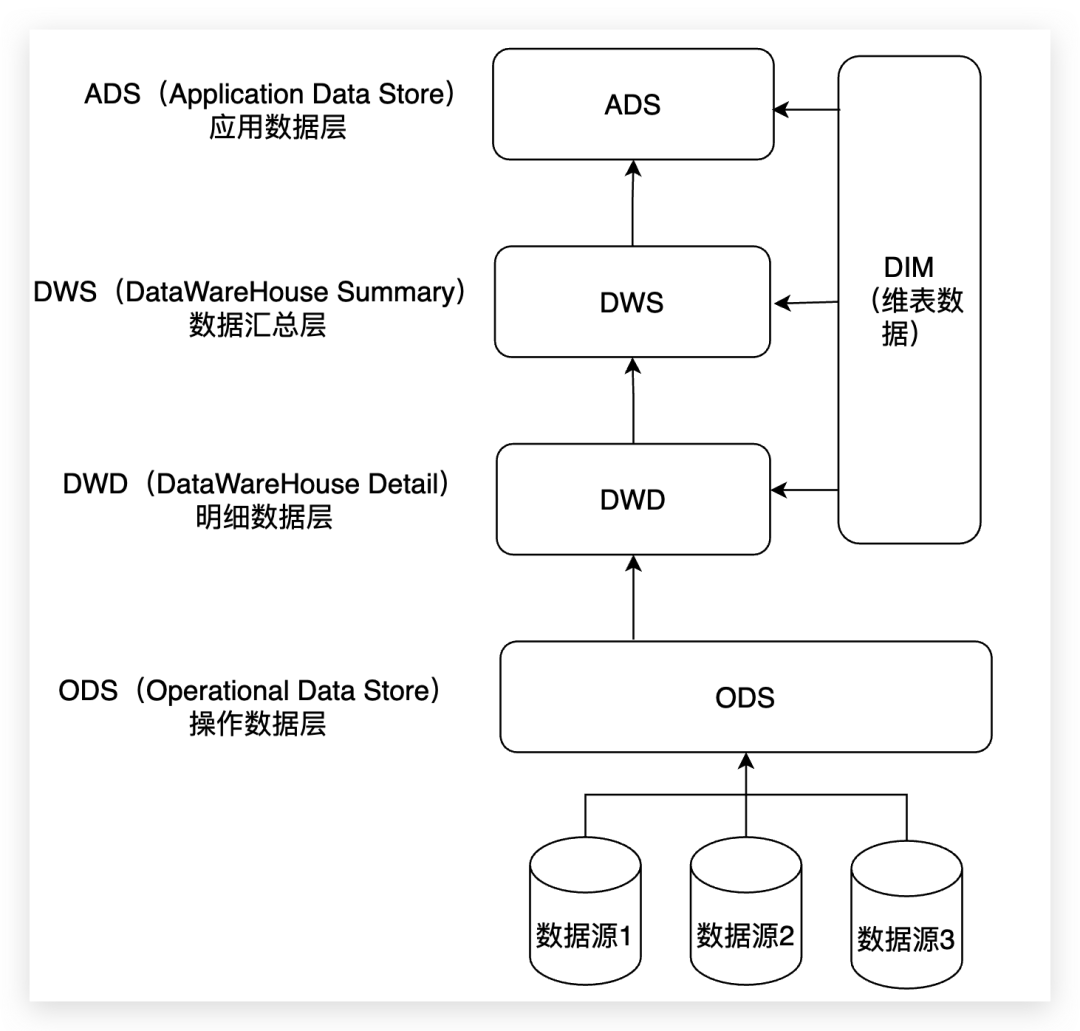
三、数仓分层的必要性

四、从Lambda架构说起
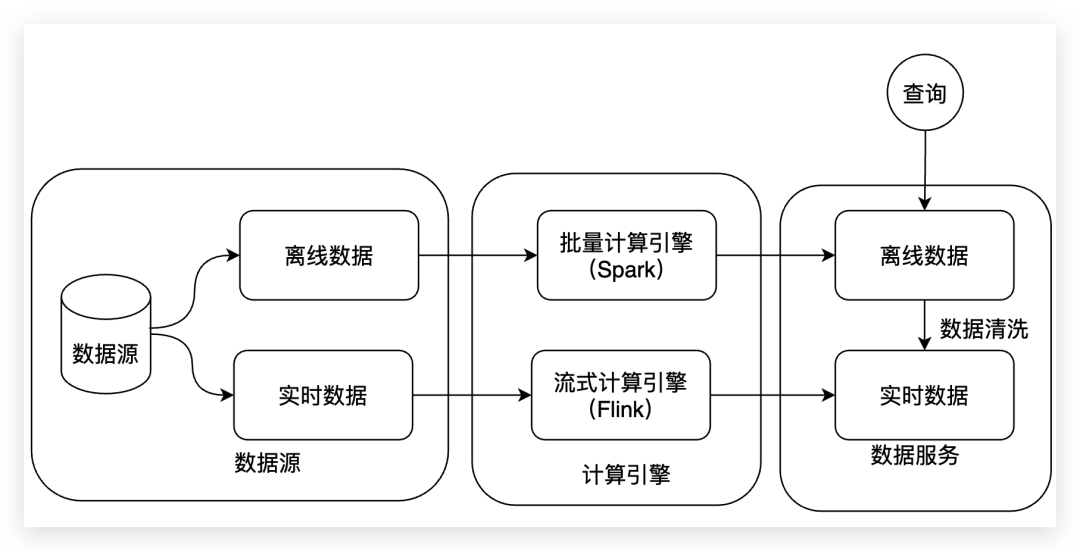
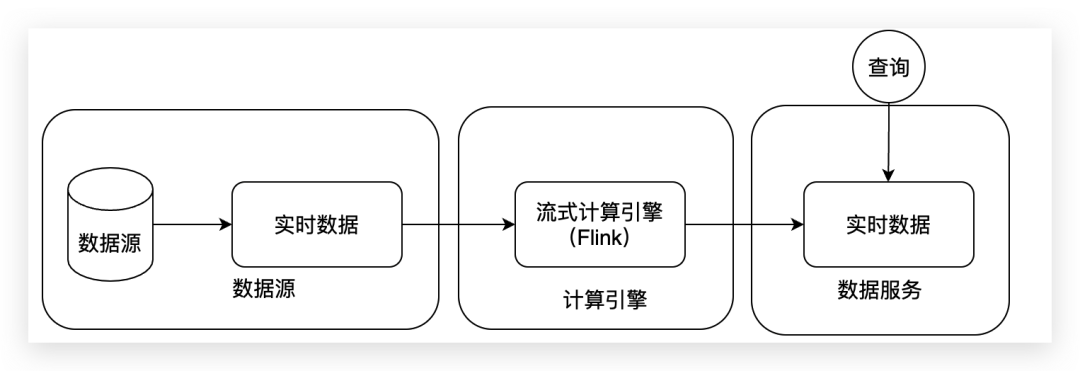
五、Kappa架构解决哪些问题
六、深入实时数仓架构

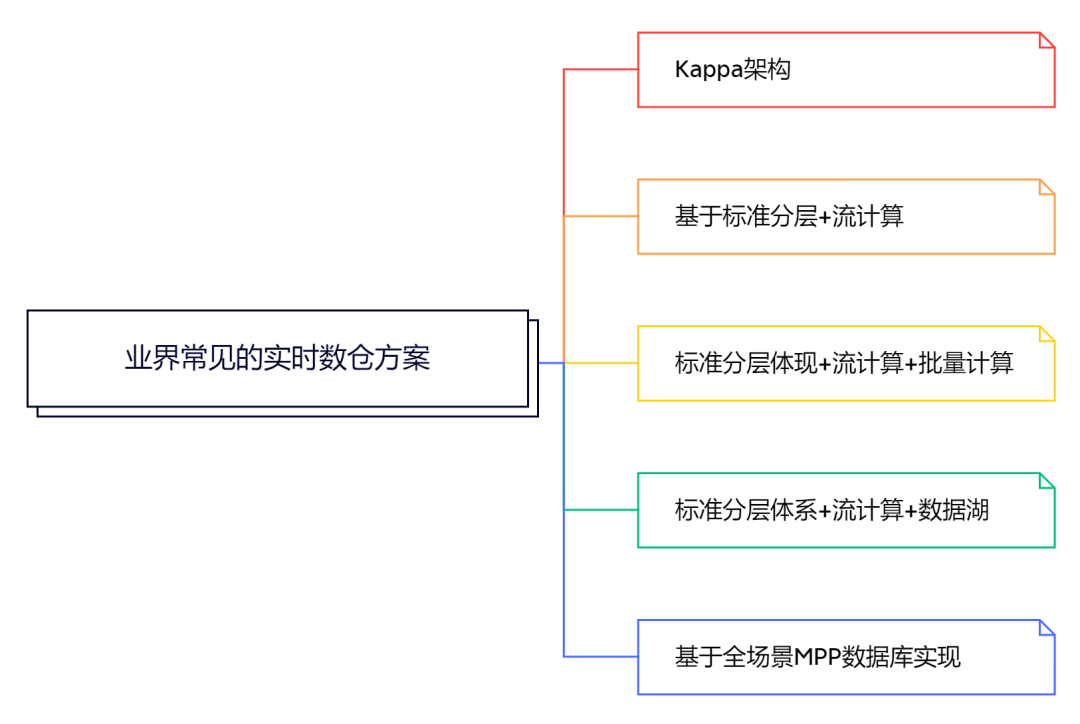
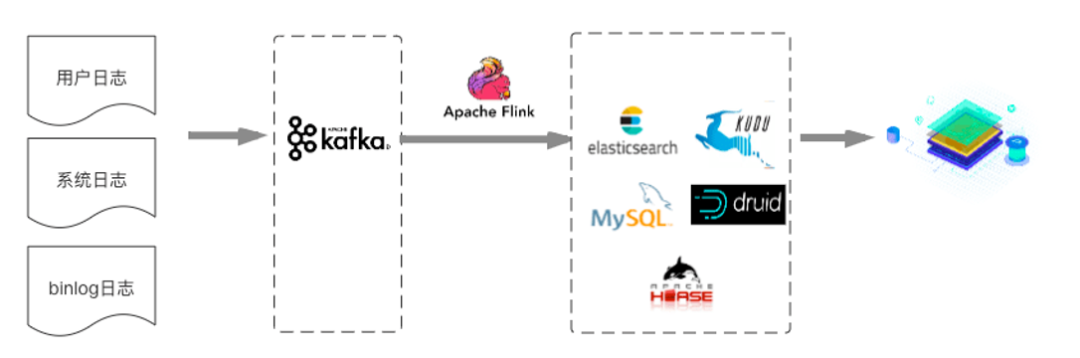
方案 1:Kappa架构
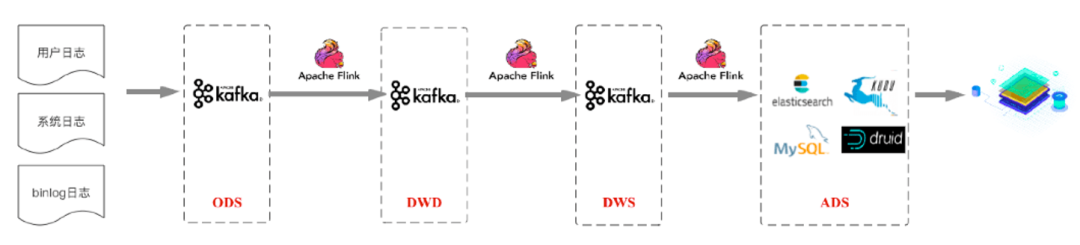
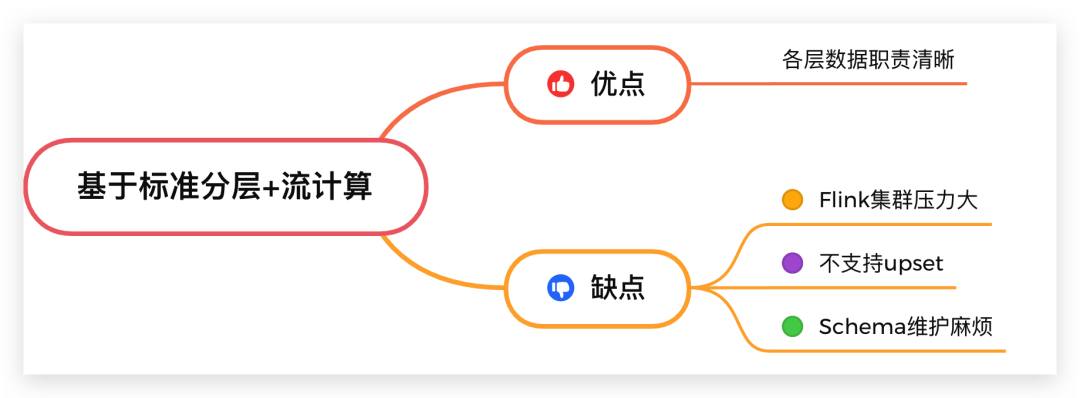
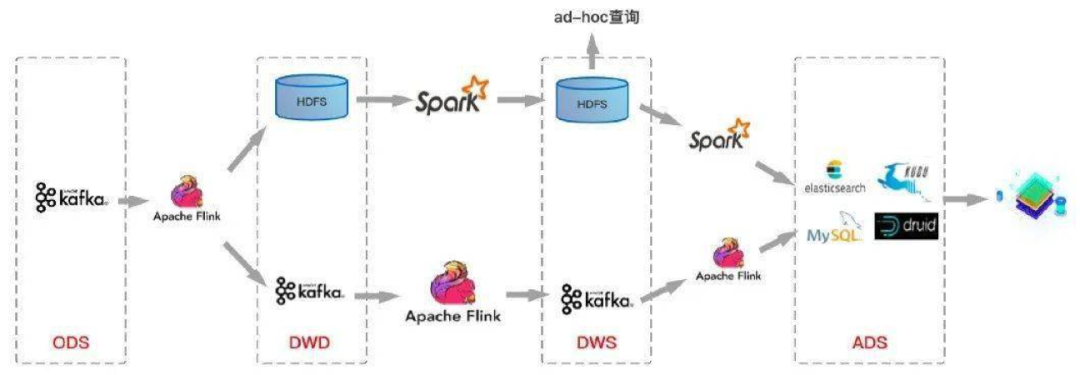
方案 2:基于标准分层 + 流计算
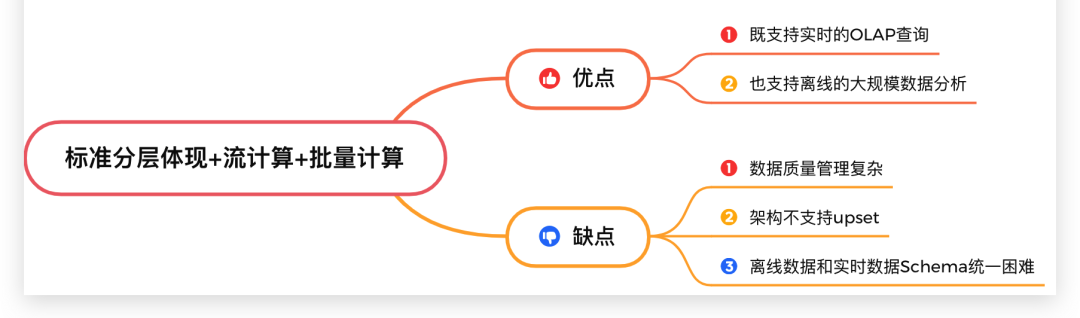
方案 3:标准分层体现+流计算+批量计算方案 3:标准分层体现+流计算+批量计算
方案 4:标准分层体系+流计算+数据湖

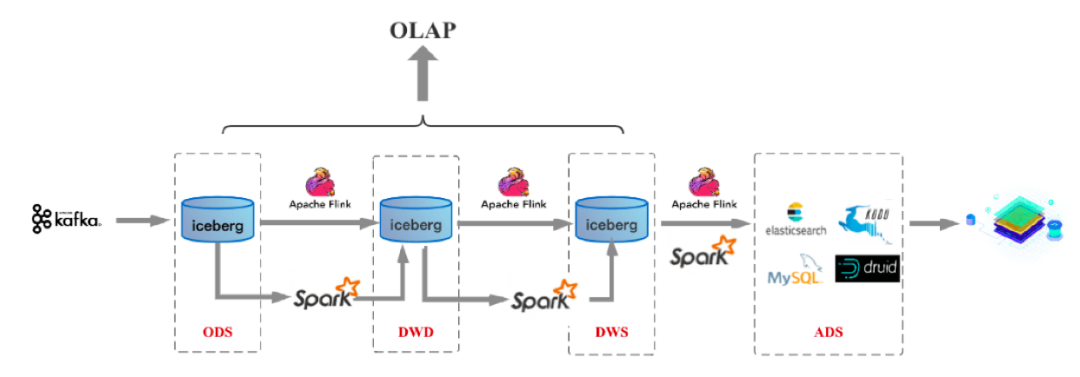
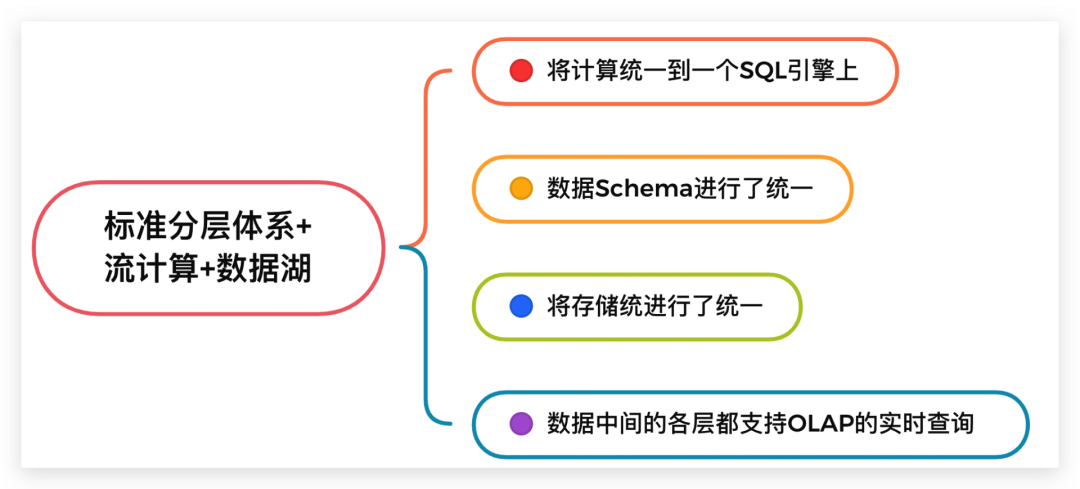
在编程上将流计算和批计算统一到同一个SQL引擎上,基于同一个Flink SQL既可以进行流计算,也可以进行批计算。
将流计算和批计算的存储进行了统一,也就是统一到Iceberg/HDFS上,这样数据的血缘关系的和数据质量体系的建立也变得简单了。
由于存储层统一,数据的Schema也自然统一起来了,这样相对流批单独两条计算逻辑来说,处理逻辑和元数据管理的逻辑都得到了统一。
数据中间的各层(ODS、DWD、DWS、ADS)数据,都支持OLAP的实时查询。
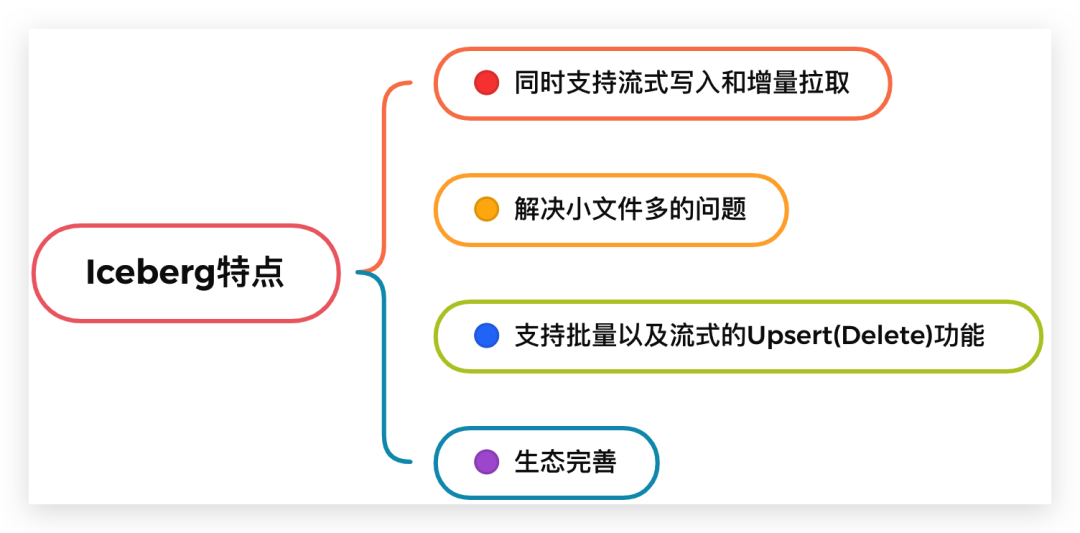
同时支持流式写入和增量拉取。
解决小文件多的问题。数据湖实现了相关合并小文件的接口,Spark / Flink上层引擎可以周期性地调用接口进行小文件合并。
支持批量以及流式的 Upsert(Delete) 功能。批量Upsert / Delete功能主要用于离线数据修正。流式upsert场景前面介绍了,主要是流处理场景下经过窗口时间聚合之后有延迟数据到来的话会有更新的需求。这类需求是需要一个可以支持更新的存储系统的,而离线数仓做更新的话需要全量数据覆盖,这也是离线数仓做不到实时的关键原因之一,数据湖是需要解决掉这个问题的。
同时 Iceberg 还支持比较完整的OLAP生态。比如支持Hive / Spark / Presto / Impala 等 OLAP 查询引擎,提供高效的多维聚合查询性能。
方案 5:基于全场景MPP数据库实现
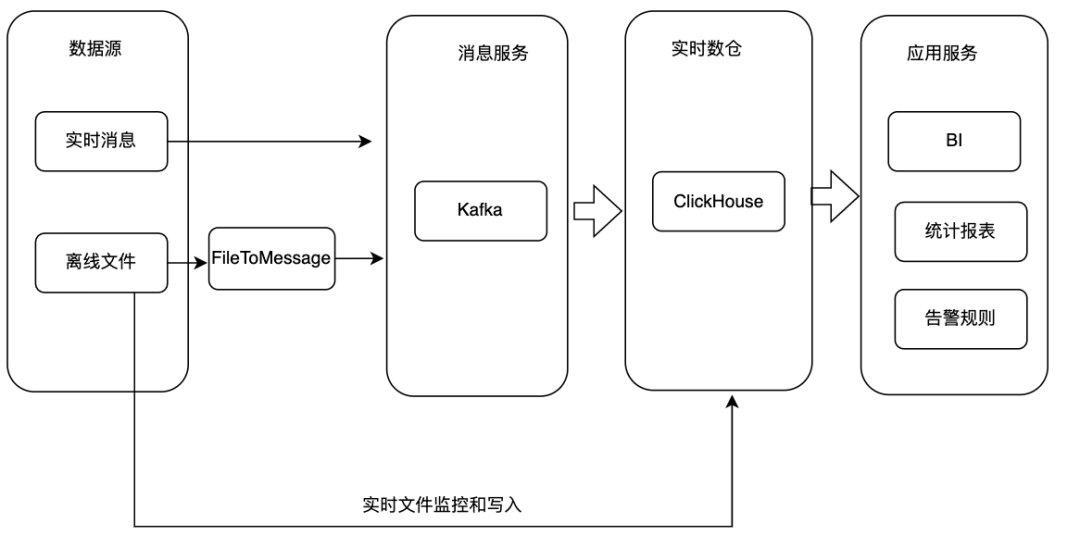
基于Darios或者ClickHouse构建实时数仓。来看下具体的实现方式:将数据源上的实时数据直接写入消费服务。
对于数据源为离线文件的情况有两种处理方式,一种是将文件转为流式数据写入Kafka,另外一种情况是直接将文件通过SQL导入ClickHouse集群。
ClickHouse接入Kafka消息并将数据写入对应的原始表,基于原始表可以构建物化视图、Project等实现数据聚合和统计分析。
应用服务基于ClickHouse数据对外提供BI、统计报表、告警规则等服务。
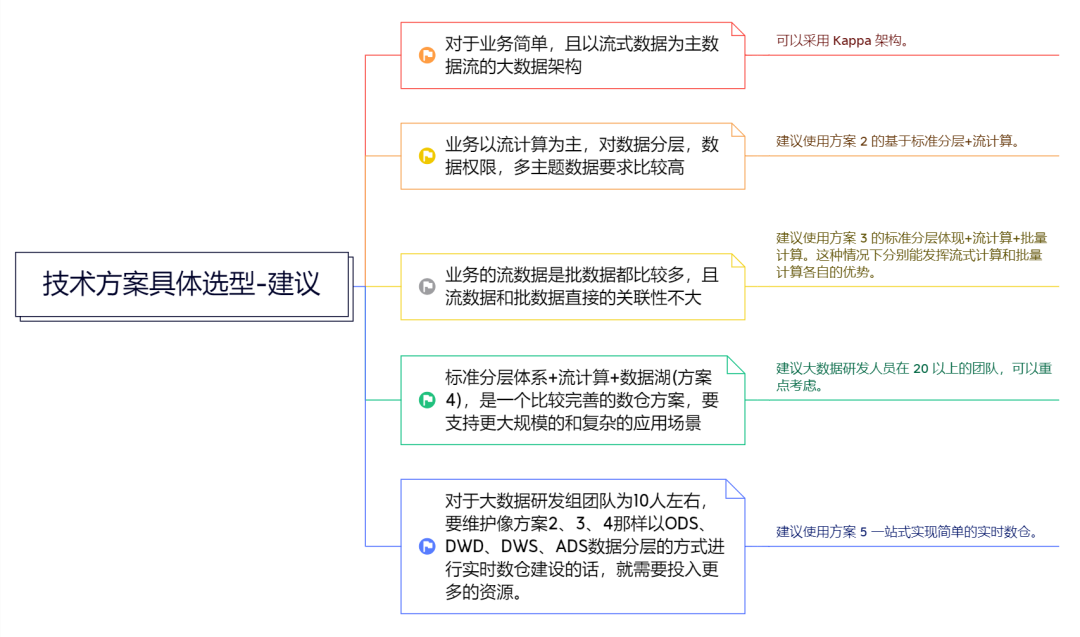
七、具体选型建议
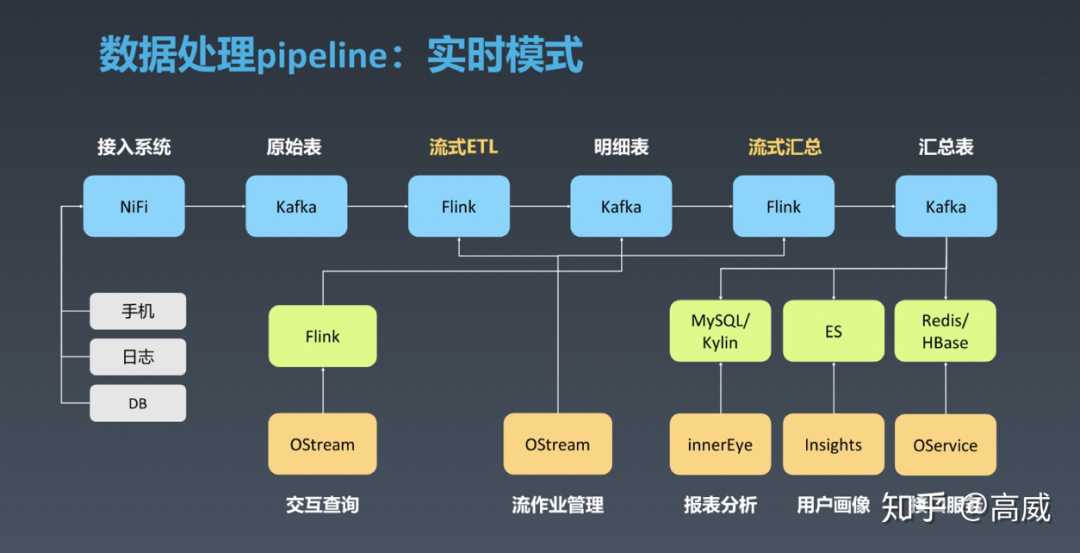
八、大厂方案分享
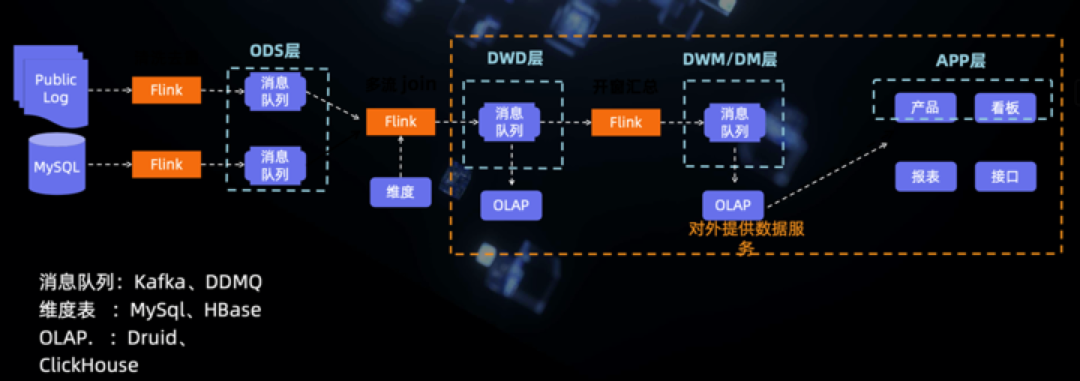
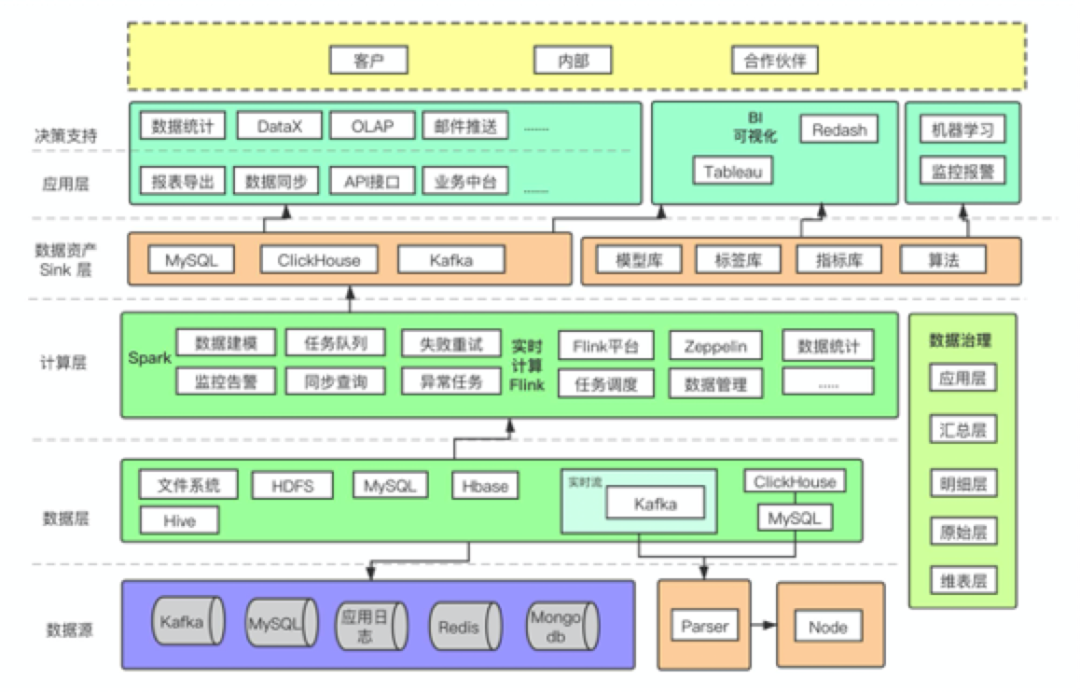
九、结语 & 延申思考
延申思考







暂无评论内容