

长文详解HiveSQL执行计划
==================================================
本文目录:一、前言二、SQL的执行计划
一、前言
可以说执行计划是打开SQL优化大门的一把钥匙
要想学SQL执行计划,就需要学习查看执行计划的命令:explain,在查询语句的SQL前面加上关键字explain是查看执行计划的基本方法。
学会explain,能够给我们工作中使用hive带来极大的便利!
二、SQL的执行计划
Hive提供的执行计划目前可以查看的信息有以下几种:
explain
explain dependency
explain authorization
explain vectorization
explain analyze
explain cbo
explain locks
explain ast
explain extended
1. explain 的用法
Hive提供了explain命令来展示一个查询的执行计划
使用语法如下:
在 hive cli 中输入以下命令(hive 2.3.7):
得到结果:
看完以上内容有什么感受,是不是感觉都看不懂,不要着急,下面将会详细讲解每个参数,相信你学完下面的内容之后再看 explain 的查询结果将游刃有余。
一个HIVE查询被转换为一个由一个或多个stage组成的序列(有向无环图DAG)。这些stage可以是MapReduce stage,也可以是负责元数据存储的stage,也可以是负责文件系统的操作(比如移动和重命名)的stage
我们将上述结果拆分看,先从最外层开始,包含两个大的部分:
先看第一部分 stage dependencies ,包含两个 stage,Stage-1 是根stage,说明这是开始的stage,Stage-0 依赖 Stage-1,Stage-1执行完成后执行Stage-0。
再看第二部分 stage plan,里面有一个 Map Reduce,一个MR的执行计划分为两个部分:
这两个执行计划树里面包含这条sql语句的 operator:
2. explain 的使用场景
本节介绍 explain 能够为我们在生产实践中带来哪些便利及解决我们哪些迷惑
案例一:join 语句会过滤 null 的值吗?
现在,我们在hive cli 输入以下查询计划语句
上面这条 join 语句会过滤 id 为 null 的值吗
执行下面语句:
我们来看结果 (为了适应页面展示,仅截取了部分输出信息):
predicate: id is not null说明 join 时会自动过滤掉关联字段为 null值的情况,但 left join 或 full join 是不会自动过滤null值的
案例二:group by 分组语句会进行排序吗?
看下面这条sql
group by 分组语句会进行排序吗
直接来看 explain 之后结果 (为了适应页面展示,仅截取了部分输出信息)
说明是按照 id 字段进行正序排序的
案例三:哪条sql执行效率高呢?
观察两条sql语句
这两条sql语句输出的结果是一样的,但是哪条sql执行效率高呢
有人说第一条sql执行效率高,因为第二条sql有子查询,子查询会影响性能;
有人说第二条sql执行效率高,因为先过滤之后,在进行join时的条数减少了,所以执行效率就高了。
到底哪条sql效率高呢,我们直接在sql语句前面加上 explain,看下执行计划不就知道了嘛!
在第一条sql语句前加上 explain,得到如下结果
在第二条sql语句前加上 explain,得到如下结果
说明 hive 底层会自动帮我们进行优化,所以这两条sql语句执行效率是一样的
案例四:定位产生数据倾斜的代码段
数据倾斜大多数都是大 key 问题导致的。
如何判断是大 key 导致的问题,可以通过下面方法:
1. 通过时间判断
如果某个 reduce 的时间比其他 reduce 时间长的多,如下图,大部分 task 在 1 分钟之内完成,只有 r_000000 这个 task 执行 20 多分钟了还没完成。

注意
如果每个 reduce 执行时间差不多,都特别长,不一定是数据倾斜导致的,可能是 reduce 设置过少导致的。
有时候,某个 task 执行的节点可能有问题,导致任务跑的特别慢。这个时候,mapreduce 的推测执行,会重启一个任务。如果新的任务在很短时间内能完成,通常则是由于 task 执行节点问题导致的个别 task 慢。但是如果推测执行后的 task 执行任务也特别慢,那更说明该 task 可能会有倾斜问题。
2. 通过任务 Counter 判断
Counter 会记录整个 job 以及每个 task 的统计信息。counter 的 url 一般类似:
http://bd001:8088/proxy/application_1624419433039_1569885/mapreduce/singletaskcounter/task_1624419433039_1569885_r_000000/org.apache.hadoop.mapreduce.FileSystemCounter
通过输入记录数,普通的 task counter 如下,输入的记录数是 13 亿多:
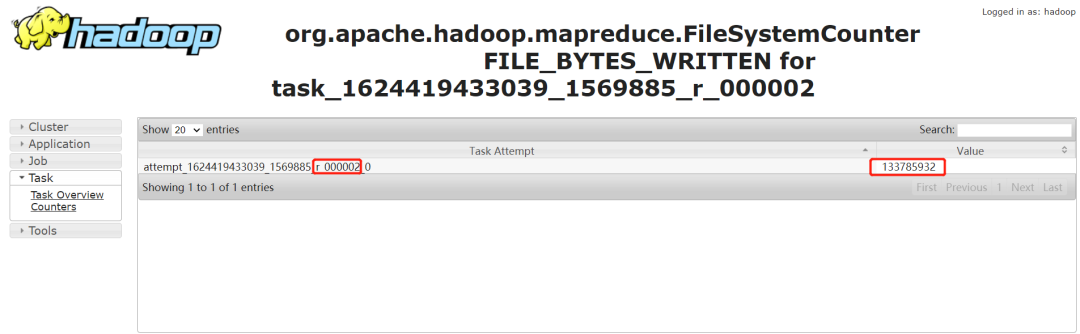
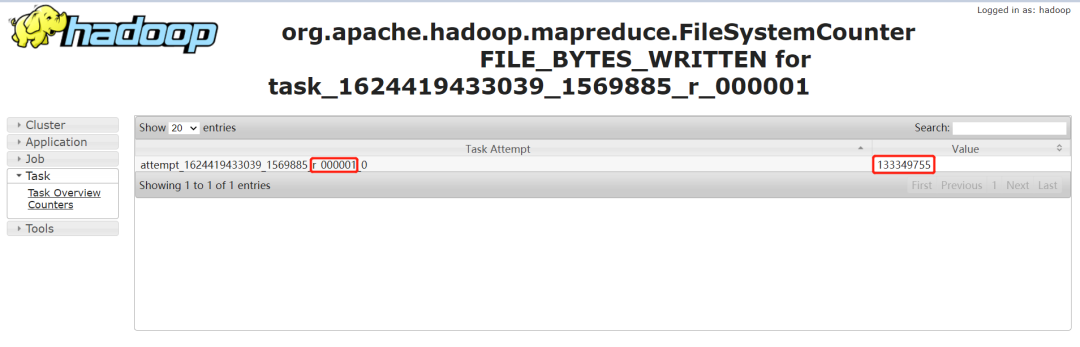
而 task=000000 的 counter 如下,其输入记录数是 230 多亿。是其他任务的 100 多倍:

定位 SQL 代码
1. 确定任务卡住的 stage
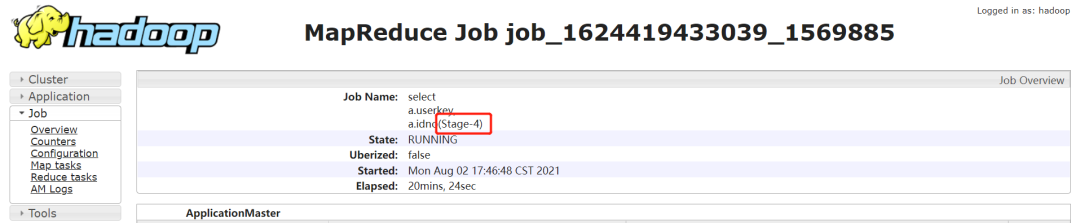
通过 jobname 确定 stage:
一般 Hive 默认的 jobname 名称会带上 stage 阶段,如下通过 jobname 看到任务卡住的为 Stage-4:
如果 jobname 是自定义的,那可能没法通过 jobname 判断 stage。需要借助于任务日志:
找到执行特别慢的那个 task,然后 Ctrl+F 搜索 “CommonJoinOperator: JOIN struct” 。Hive 在 join 的时候,会把 join 的 key 打印到日志中。如下:

struct<_col0:string, _col1:string, _col3:string>
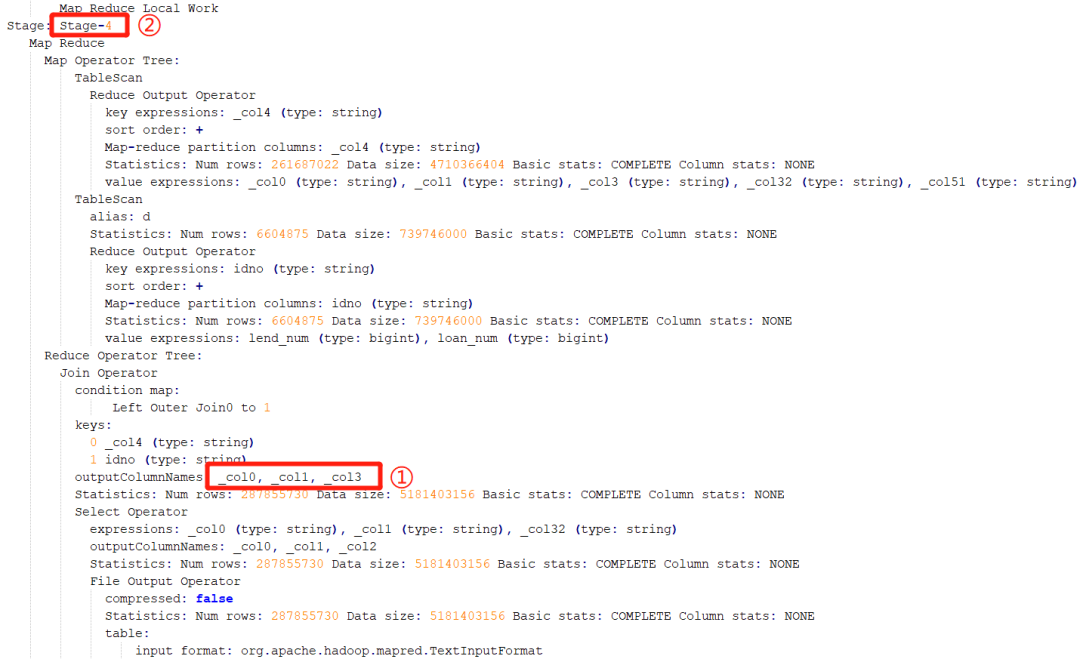
该 SQL 的执行计划。通过参考执行计划,可以断定该阶段为 Stage-4 阶段
2. 确定 SQL 执行代码
通过执行计划,则可以判断出是执行哪段代码时出现了倾斜
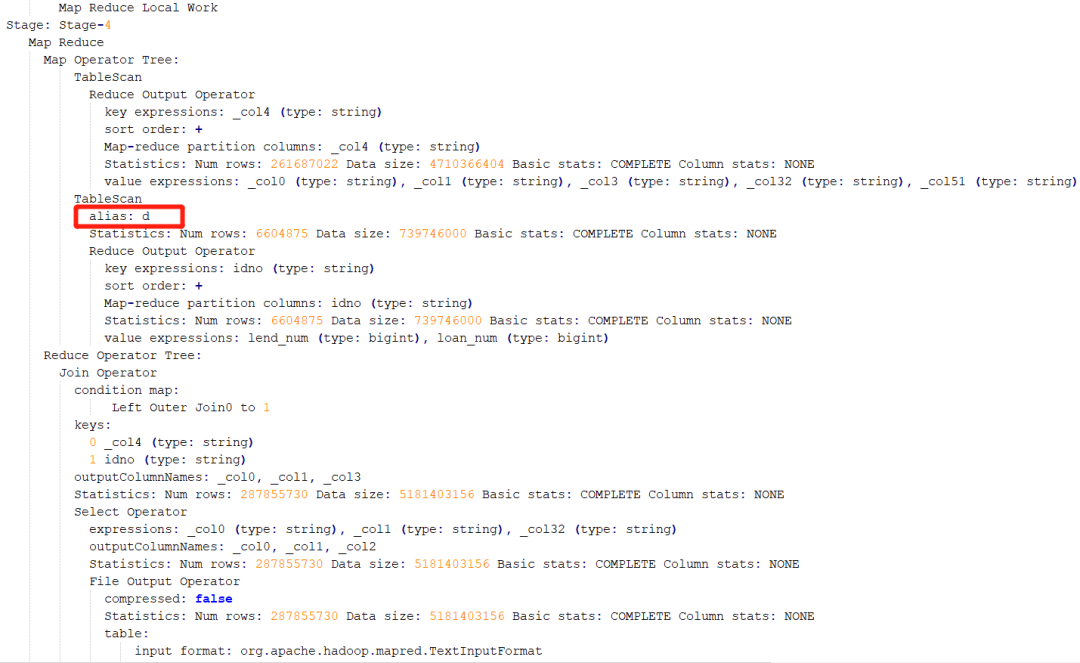
就可以推测出是在执行下面红框中代码时出现了数据倾斜,因为这行的表的别名是 d:

以上仅列举了4个我们生产中既熟悉又有点迷糊的例子,explain 还有很多其他的用途,如查看stage的依赖情况、hive 调优等,小伙伴们可以自行尝试。
3. explain dependency的用法
explain dependency用于描述一段SQL需要的数据来源,输出是一个json格式的数据,里面包含以下两个部分的内容:
input_partitions
input_tables
使用explain dependency查看SQL查询非分区普通表
得到结果:
使用explain dependency查看SQL查询分区表
得到结果:
explain dependency的使用场景有两个:
场景一
场景二
下面通过两个案例来看explain dependency的实际运用:
案例一:识别看似等价的代码
对于刚接触SQL的程序员,很容易将
select * from a inner join b on a.no=b.no and a.f>1 and a.f<3;
等价于
select * from a inner join b on a.no=b.no where a.f>1 and a.f<3;
我们可以通过案例来查看下它们的区别:
代码1:
代码2:
我们看下上述两段代码explain dependency的输出结果:
代码1的explain dependency结果
代码2的explain dependency结果
通过上面的输出结果可以看到,其实上述的两个SQL并不等价,代码1在内连接(inner join)中的连接条件(on)中加入非等值的过滤条件后,并没有将内连接的右表按照过滤条件进行过滤,内连接在执行时会多读取part=0的分区数据。而在代码2中,会过滤掉不符合条件的分区。
案例二:识别SQL读取数据范围的差别
代码1:
代码2:
以上两个代码的数据读取范围是一样的吗?答案是不一样,我们通过explain dependency来看下:
代码1的explain dependency结果
代码2的explain dependency结果
如果过滤条件是作用于右表(b表)有起到过滤的效果,则右表只要扫描两个分区即可,但是左表(a表)会进行全表扫描。如果过滤条件是针对左表,则完全没有起到过滤的作用,那么两个表将进行全表扫描
在使用过程中,容易认为代码片段2可以像代码片段1一样进行数据过滤,通过查看explain dependency的输出结果,可以知道不是如此。
4. explain authorization 的用法
通过explain authorization可以知道当前SQL访问的数据来源(INPUTS) 和数据输出(OUTPUTS),以及当前Hive的访问用户 (CURRENT_USER)和操作(OPERATION)。
在 hive cli 中输入以下命令:
结果如下:
从上面的信息可知:
上面案例的数据来源是defalut数据库中的 student_tb_orc表;
数据的输出路径是hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194-90f1475a3ed5/-mr-10000;
当前的操作用户是hdfs,操作是查询;
Hive在默认不配置权限管理的情况下不进行权限验证,所有的用户在Hive里面都是超级管理员,即使不对特定的用户进行赋权,也能够正常查询
最后
通过上面对explain的介绍,可以发现explain中有很多值得我们去研究的内容,读懂 explain 的执行计划有利于我们优化Hive SQL,同时也能提升我们对SQL的掌控力。
–END–








暂无评论内容