
技术学习 第20页
技术学习,技术分析,问题讨论
排序
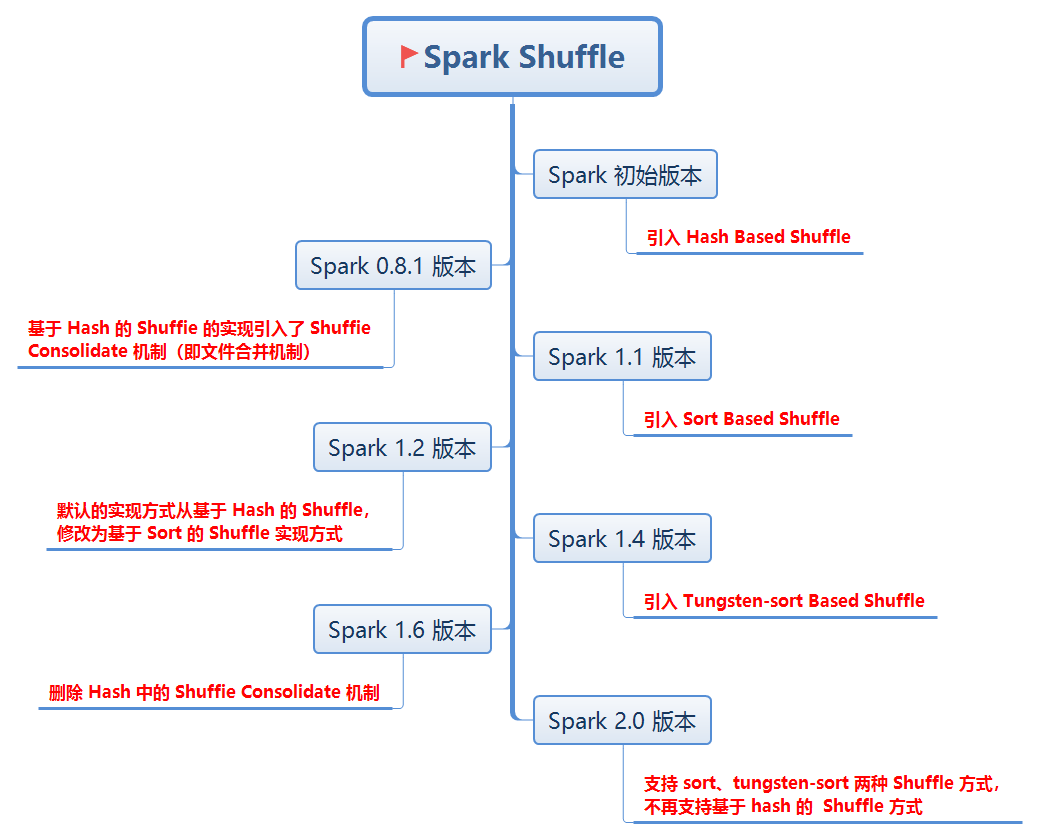
Spark的两种核心Shuffle详解
由于 Shuffle 涉及磁盘的读写和网络 I/O,因此 Shuffle 性能的高低直接影响整个程序的性能 Spark Shuffle Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle...
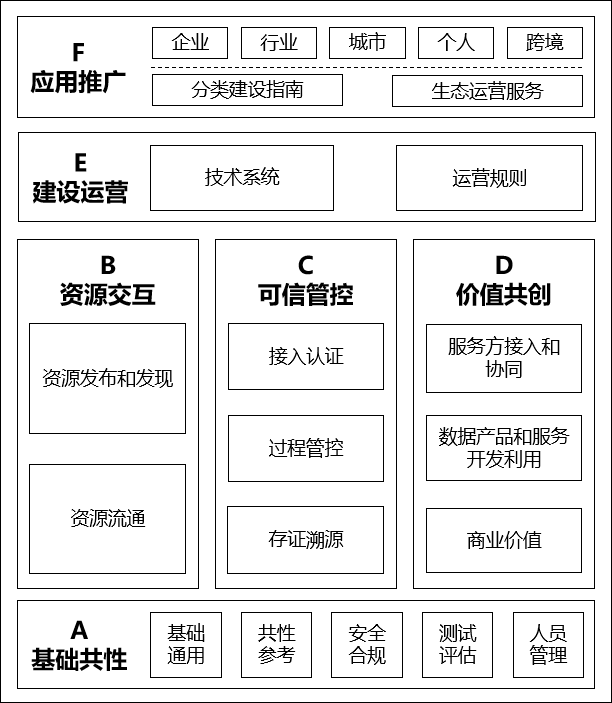
《可信数据空间标准体系建设指南(2025年版)》正式发布
2025年6月29日,《可信数据空间标准体系建设指南(2025年版)》(以下简称《指南》)正式发布。 该指南由可信数据空间发展联盟组织120家成员单位共同完成,旨在构建一套体系完备、层次清晰、协...

Shuffle慢?数据倾斜?Spark 1.0~4.0调优秘籍
一、背景 Spark SQL 通过缓存优化、分区管理、统计信息利用和动态执行计划调整等技术,显著提升 DataFrame 或 SQL 任务的性能。合理配置以下策略可解决数据倾斜、内存溢出、执行效率低下等常见...
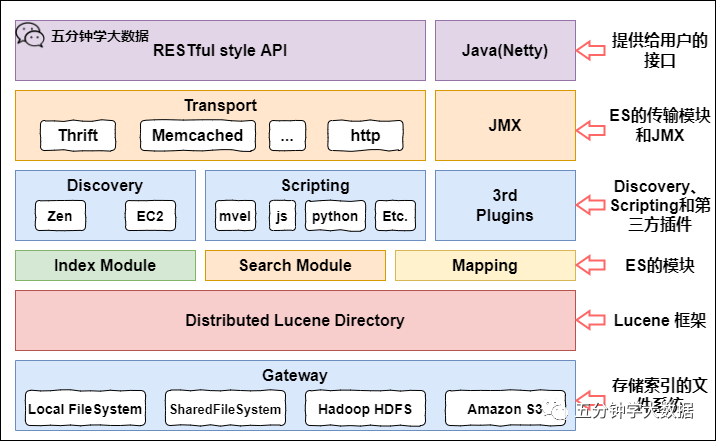
Elasticsearch 保姆级教程(文末送书)
Elasticsearch 介绍 1. Elasticsearch Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎...

一文读懂AI黑话:31个最流行的大模型术语(图解珍藏版)
一、时代基石 构成整个大语言模型时代的根基,是理解一切的前提。 1. 生成式AI (Generative AI) 2. Transformer架构 (Transformer Architecture) 3. 基础模型 (Foundation Models) 4. 预训练与...
Paimon数据丢失的常见场景和注意事项(避坑版)
Paimon数据丢失的常见场景和注意事项(避坑版) 大家好,我们又见面了。今天的内容很短小,关于写Paimon数据丢失的几种场景。 Paimon是数据湖领域最被广泛使用的框架之一。数据入Paimon的过程中造...
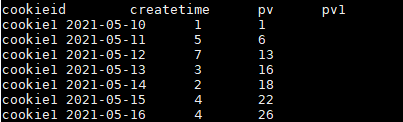
Hive窗口函数保姆级教程
在SQL中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的。但是有时我们想要既显示聚集前的数据...

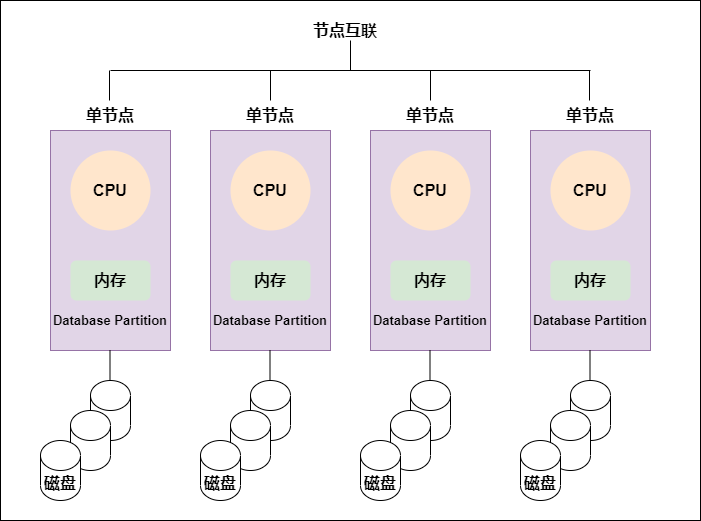
ClickHouse、Doris、 Impala等MPP架构详解
我们常用的大数据计算引擎有很多都是MPP架构的,像我们熟悉的Impala、ClickHouse、Druid、Doris等都是MPP架构。 亿级秒开 详解MPP架构MPP架构与批处理架构的异同点采用MPP架构的OLAP引擎介绍 一...

国标《GB_T 44109-2024 信息技术 大数据 数据治理实施指南 》发布
正文开始 《GB/T 44109-2024 信息技术 大数据 数据治理实施指南》是一项具有指导性和实践性的国家标准,旨在为各行业在大数据环境下实施数据治理提供具体的指导方法和实施路径。该标准规定了数...
