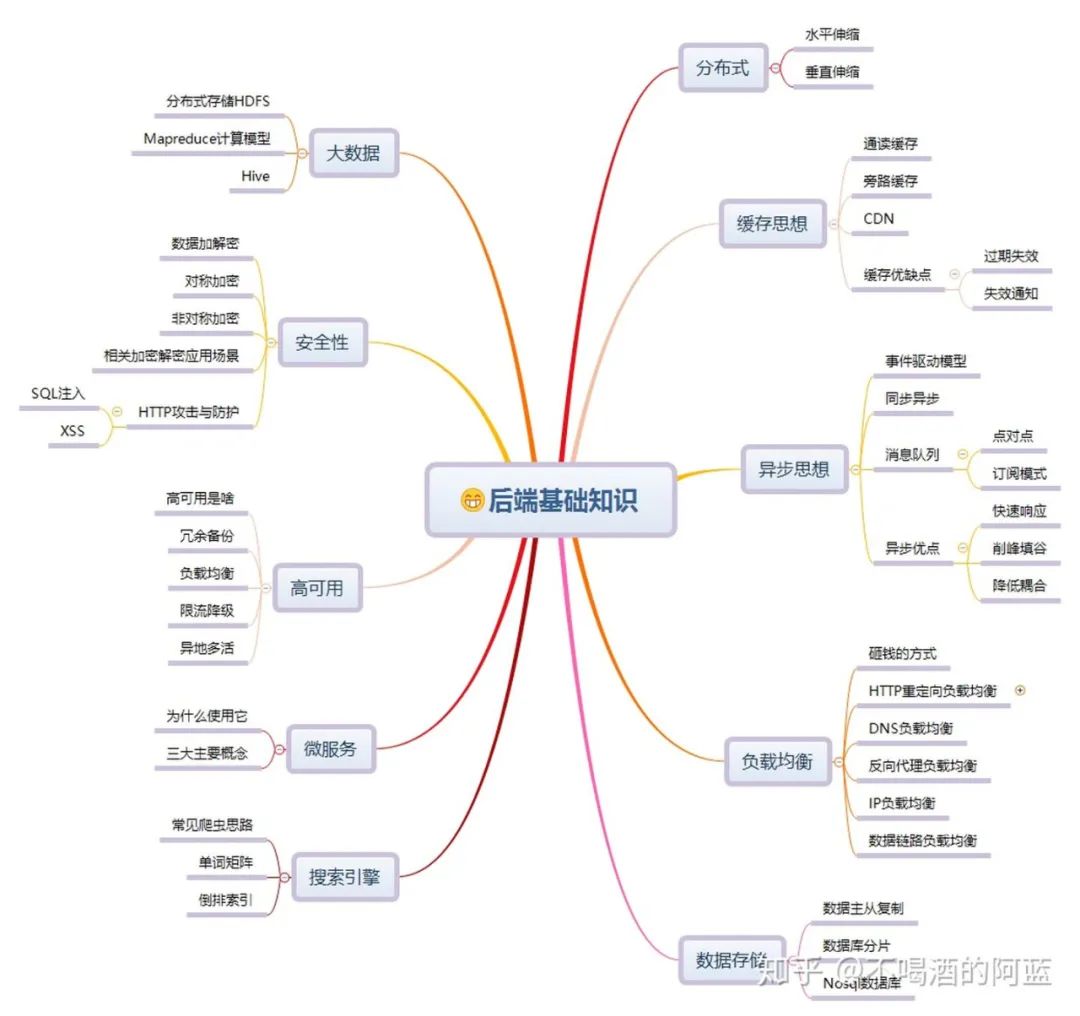
大数据分享 第17页
排序

2024中国软件150强出炉
近日,中国科学院旗下权威媒体《互联网周刊》联合德本咨询等共同布“2024中国软件150强”榜单。榜单根据一套严格的评估体系评定出的结果,评定因素会涉及技术实力、市场地位、服务质量、发展前...

Hive十亿级以上数据全局排序的一种实现方式
背景 大数据时代,日常工作中经常会处理数以亿计的数据。笔者近期就遇到了一个十亿级以上的数据排序需求,并输出序号。如果是小规模数据我们直接使用row_number全局排序就可以了,但是当数据规模...
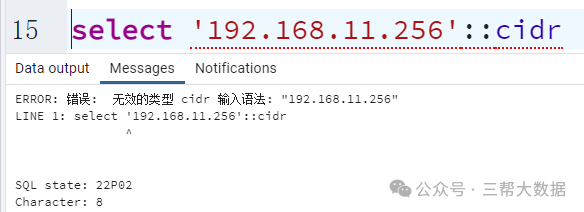
PostgreSQL基础(六):PostgreSQL基本操作(二)
PostgreSQL基本操作(二) 一、字符串类型 字符串类型用的是最多的一种,在PGSQL里,主要支持三种: character(就是MySQL的char类型),定长字符串。(最大可以存储1G) character varying(va...
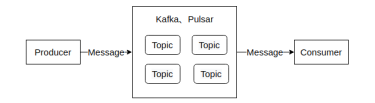
两个优秀的分布式消息流平台:Kafka与Pulsar剖析
本文向读者介绍两个优秀的分布式消息流平台:Kafka与Pulsar。Kafka与Pulsar。 Apache Kafka(简称Kafka) Apache Pulsar(简称Pulsar) 基础功能: (1)消息系统: 优点: 系统解耦:生产者与...
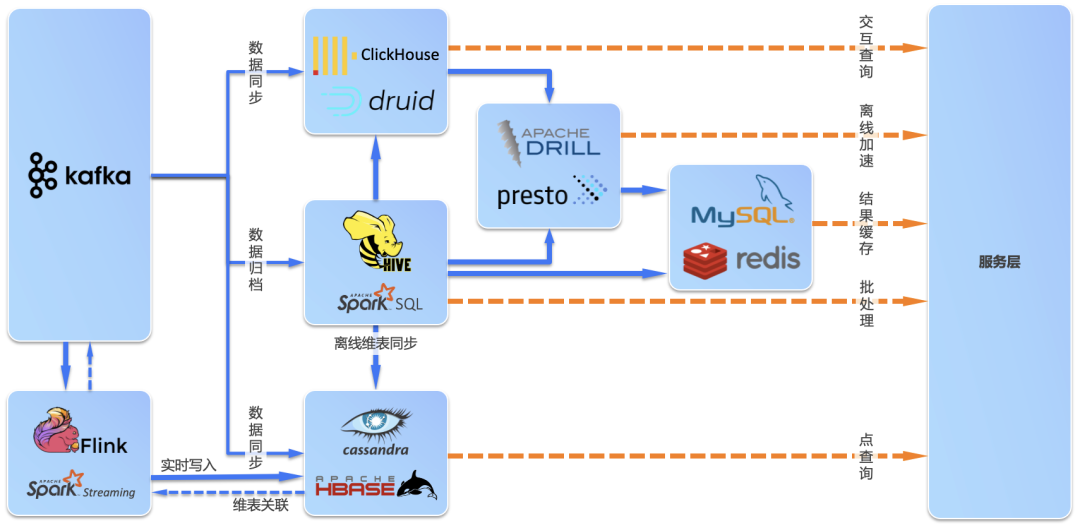
实时数仓分层架构超全解决方案
ODS:Operation Data Store,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,是后续数据仓库加工数据的来源。 DW数据分层,由下到上一般分为DWD,DWB,DWS。 D...

普通人如何抓住DeepSeek红利?(65页PPT)
下面这份PPT探讨了普通人如何利用 DeepSeek 这款通用人工智能工具来提升工作效率、学习效率和生活质量。介绍了 DeepSeek 的功能和能力,包括文本生成、语义分析、代码生成等,并展示了其深度思...
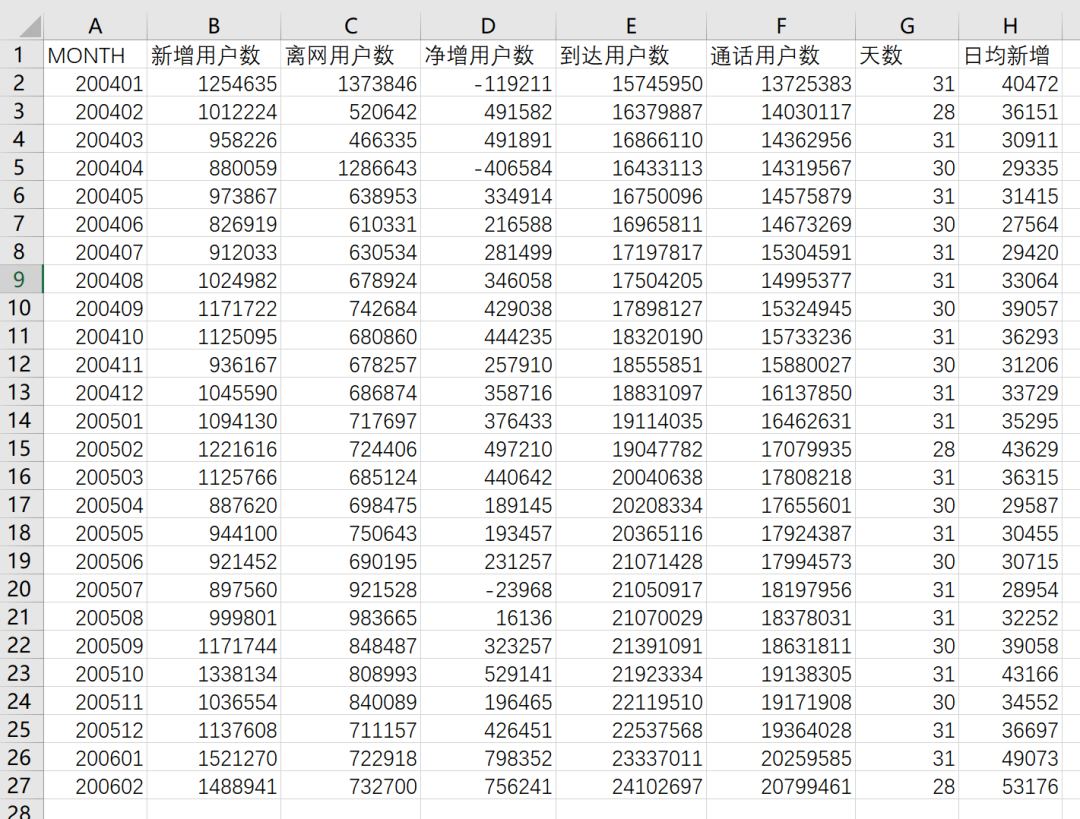
ChatGPT、Claude的数据分析能力已经到了何种水平?
ChatGPT 4o现在也具备了该能力,但距离Claude 3.5有差距,比如针对案例一,其识别出的数据明显不准确,200602的离网用户数被识别为了52000,但肉眼可见的数据应该在70000以上。 针对案例二,把...
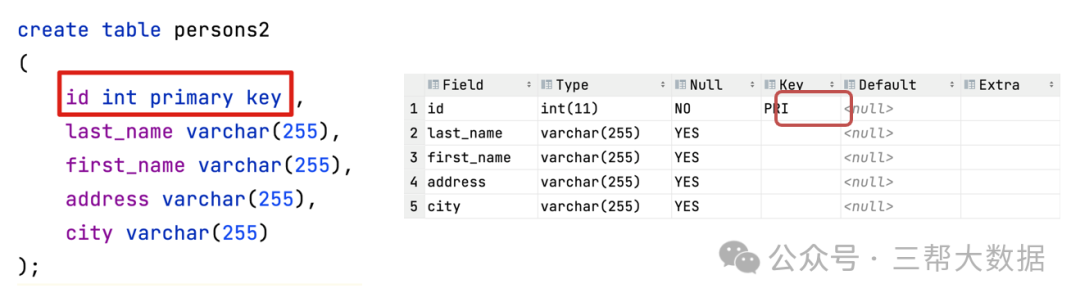
MySQL数据库基础(九):SQL约束
SQL约束 一、主键约束 遵循原则: 创建主键约束: 删除主键约束:如需撤销 PRIMARY KEY 约束,请使用下面的 SQL 补充:自动增长 我们通常希望在每次插入新记录时,数据库自动生成字段的值。 我...

Spark数据倾斜解决
一、数据倾斜表现 数据倾斜就是数据分到各个区的数量不太均匀,可以自定义分区器,想怎么分就怎么分。 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据...