
大数据分享 第10页
排序
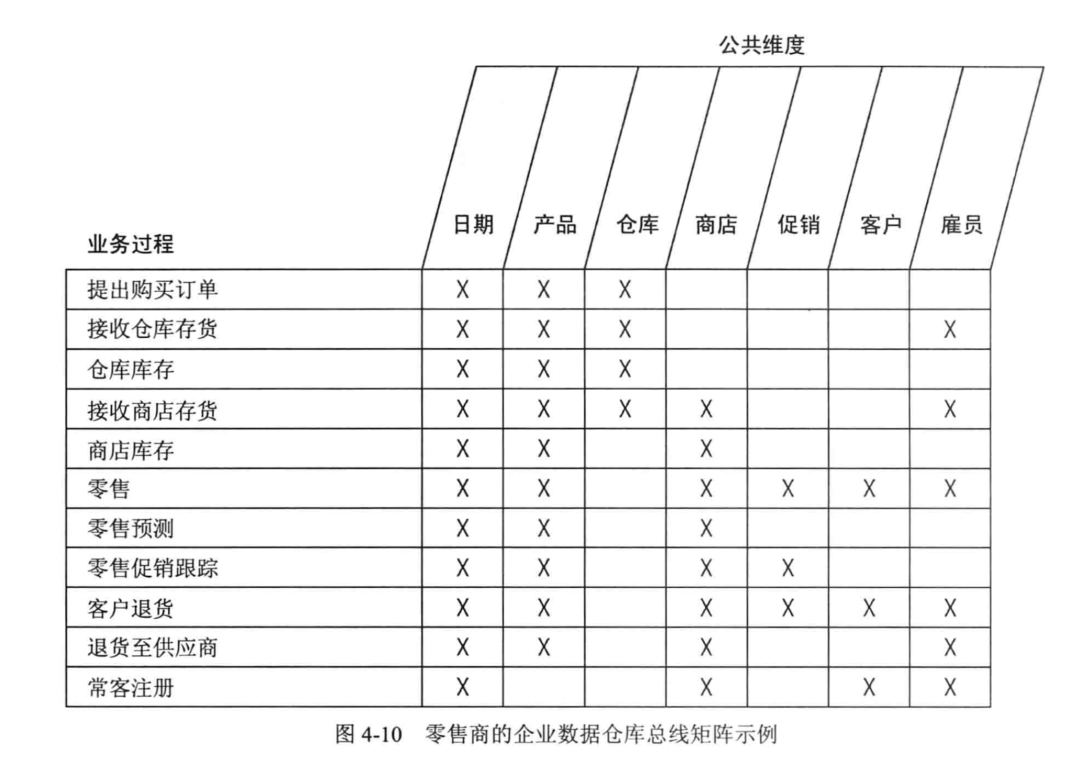
「数仓建设篇」数仓总线矩阵架构设计
如何设计一套切实可行的数据仓库呢? 帮助数据架构师清晰地梳理整个数据体系 帮助决策者(Boss)从宏观的角度了解数据仓库的整体情况 让所有的数据仓库参与者了解数据仓库的设计 如何编写总线矩...

「数仓建设篇」从0到1搭建无忧搬家数仓
一、前言 1.1 背景 从而有以下问题: 1.直接从ods贴源层取数据,业务研发侧一改造则下游链路级联影响改动很大 2.各数据分析下游从源头贴源层就直接各自依赖计算,数据链路十分零散不好管理 3.贴...

「Hive进阶篇」大表join大表优化
来源:CSDN技术博客 36678 一、问题场景 问题场景如下:A表为一个汇总表,汇总的是卖家买家最近N天交易汇总信息,即对于每个卖家最近N天,其每个买家共成交了多少单,总金额是多少,假设N取90天...

「Hive进阶篇」万字长文超详述Hive企业级优化
文章字数:13271字 预计阅读需:18分钟 有需要可 点赞+在看 关注公众号《大数据阶梯之路》找小编获取文档保存本地吧,学习和复习都是绝佳,公众号不断分享技术相关文章 一、问题背景 主要从...
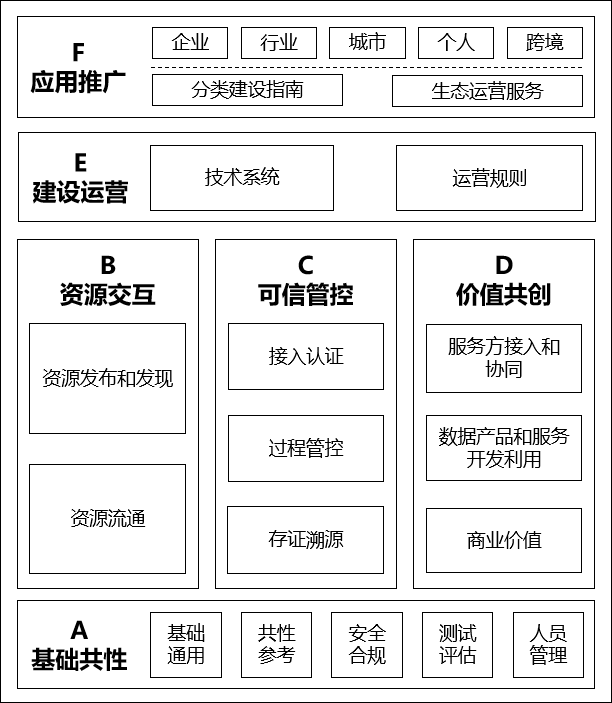
《可信数据空间标准体系建设指南(2025年版)》正式发布
2025年6月29日,《可信数据空间标准体系建设指南(2025年版)》(以下简称《指南》)正式发布。 该指南由可信数据空间发展联盟组织120家成员单位共同完成,旨在构建一套体系完备、层次清晰、协...
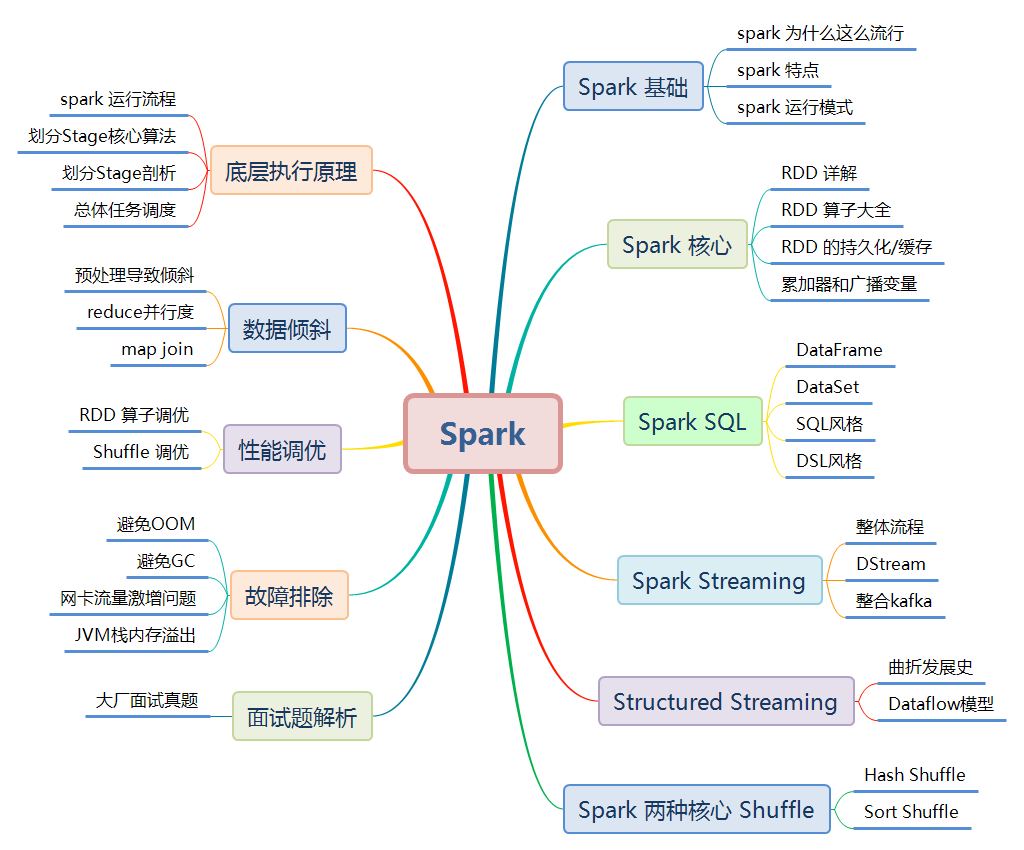
Spark知识体系五万字讲解,学习与面试收藏这篇就够了!
一、Spark 基础二、Spark Core三、Spark SQL四、Spark Streaming五、Structured Streaming六、Spark 两种核心 Shuffle七、Spark 底层执行原理八、Spark 数据倾斜九、Spark 性能调优十、Spark 故...
Spark重要知识汇总
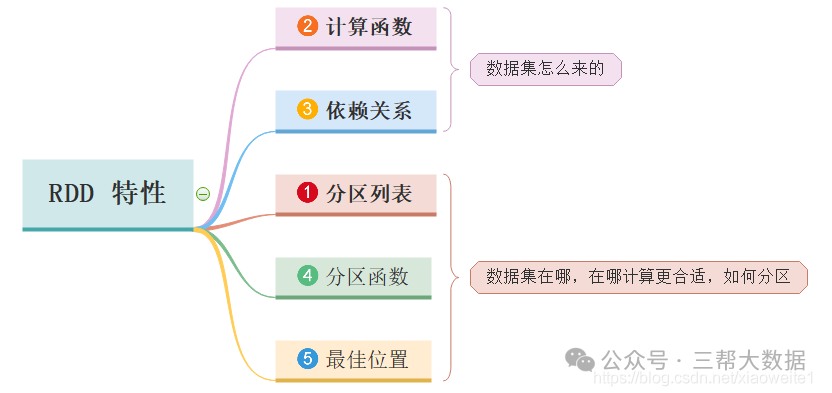
一、Spark 是什么 大规模数据处理的统一分析引擎,也可说是分布式内存迭代计算框架。 二、Spark 四大特点 三、Spark框架模块介绍 3.1、Spark Core的RDD详解 3.1.1、什么是RDD 不可变、可分区、...
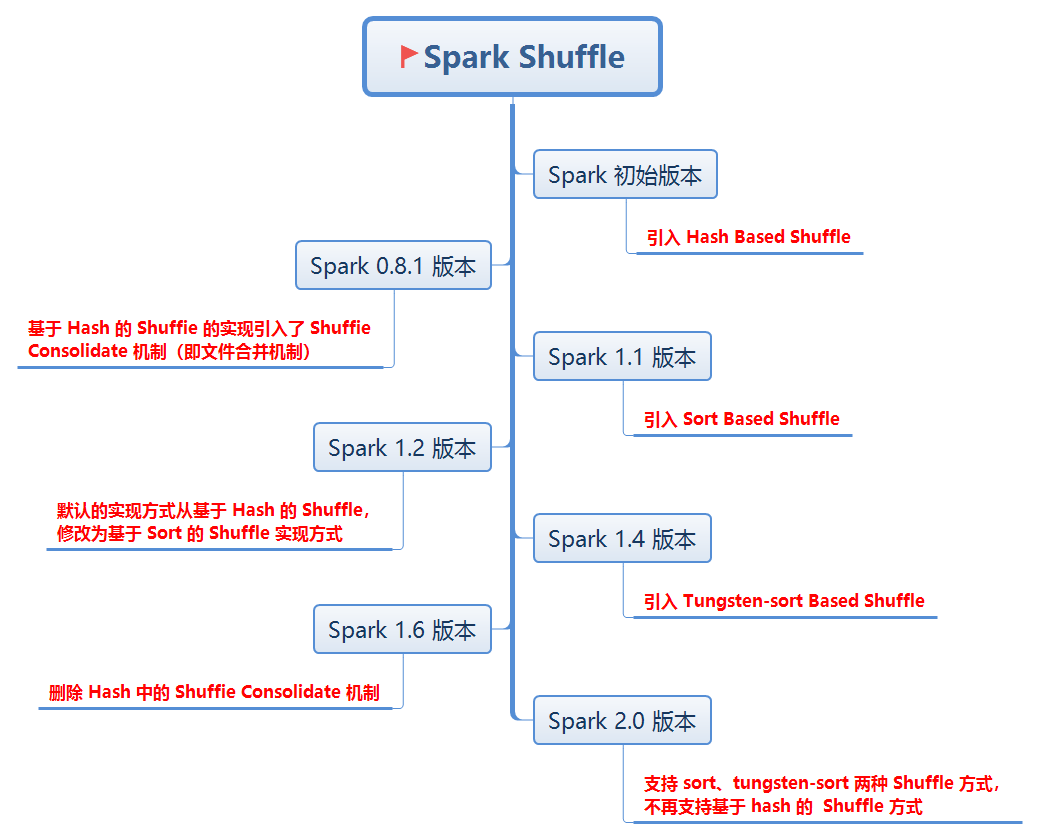
Spark的两种核心Shuffle详解
由于 Shuffle 涉及磁盘的读写和网络 I/O,因此 Shuffle 性能的高低直接影响整个程序的性能 Spark Shuffle Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle...

Spark数据倾斜解决
一、数据倾斜表现 数据倾斜就是数据分到各个区的数量不太均匀,可以自定义分区器,想怎么分就怎么分。 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据...
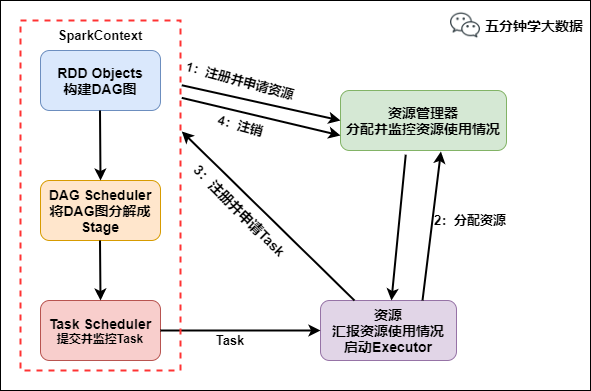
Spark底层执行原理详细解析
Spark简介 大规模数据处理高容错性高可伸缩性 Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执...
