




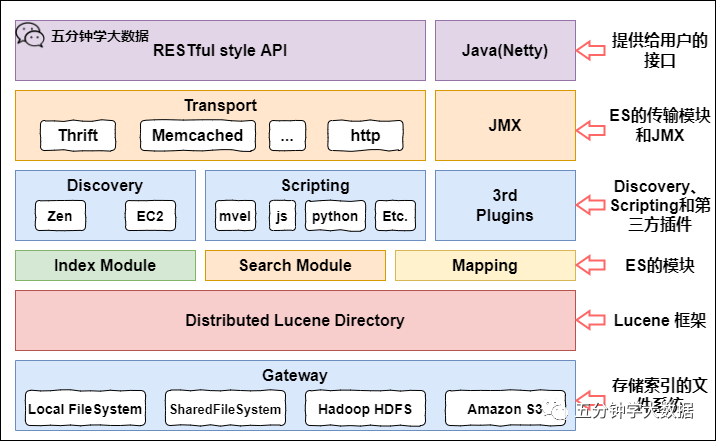
Elasticsearch 保姆级教程(文末送书)
Elasticsearch 介绍 1. Elasticsearch Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎...

Flink+Kafka存在诸多限制,下一代实时存储组件来解决!
5. Fluss 开源 当前业界呈现出一个显著的趋势,即大数据的处理正在从离线模式转向实时化。我们可以观察到,多个行业和应用场景都在进行实时化的演进。例如,互联网、车联网和金融等领域都正通过...
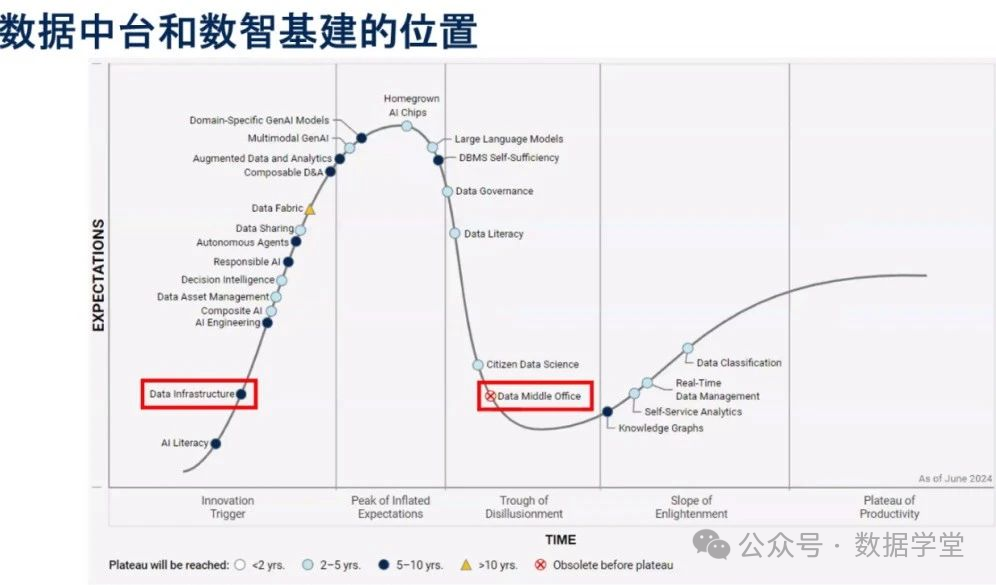
Gartner:数据中台即将消亡,取而代之的是数智基建
在上图中,数据中台处于幻灭的深渊(Trough of Disillusionment);而数智基建则处于技术萌芽期(Innovation Trigger)。 数据中台最早于 2015 年年底被阿里巴巴首次提出,数据中台的核心任务就...
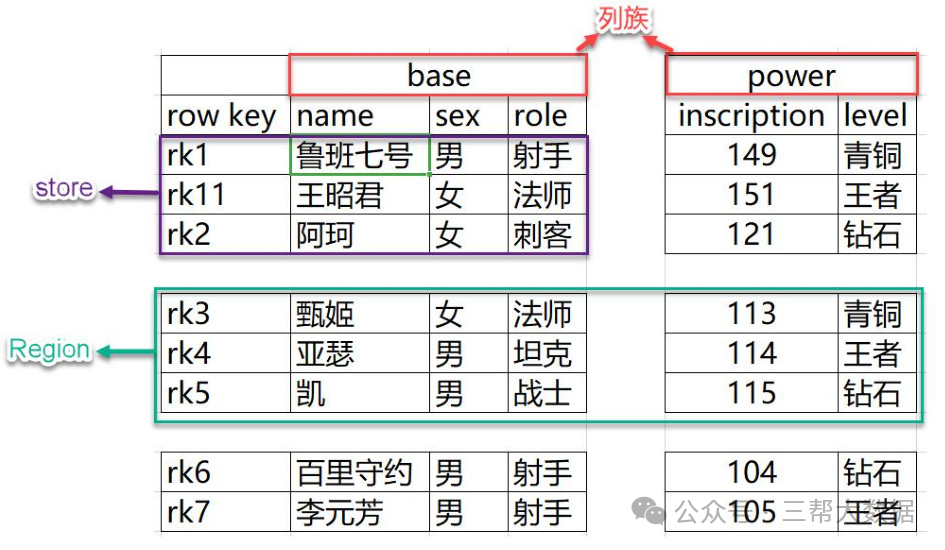
HBase分布式数据库入门介绍
一、简单介绍 HBase是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式 NOSQL 数据库。 当你需要随机、实时读/写访问大数据时,请使用 Apache HBase。 作用 名称解释: NameSpace Regio...

Hadoop_Spark 太重,esProc SPL 很轻
Hadoop/Spark 之重 轻量级的选择 SPL 集群计算的代码也非常简单,比如前面提到的订单分析计算,具体要求是:大订单表分段存储在 4 个节点上,小产品表则加载到每个节点的内存中,两表关联之后要...
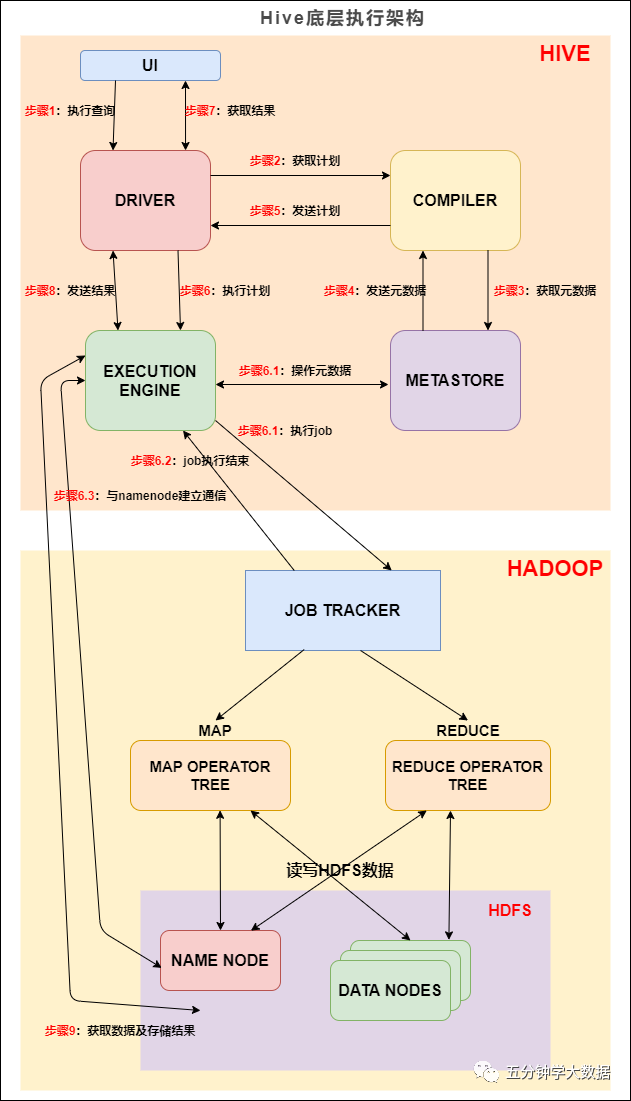
Hive SQL底层执行过程详细剖析
Hive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。 Hive直接访问存储在 HDFS 中或者 HBase 中的文件...

Hive、SparkSQL是如何决定写文件的数量的?
1. Hive 1.1 without shuffle Hive在通过SQL写文件是通过MapReduce任务完成的,如下面这个例子: 在表中插入数据后,可以hdfs对应路径下找到存储的文件 可以看到插入生成了1个文件,这是因为每...
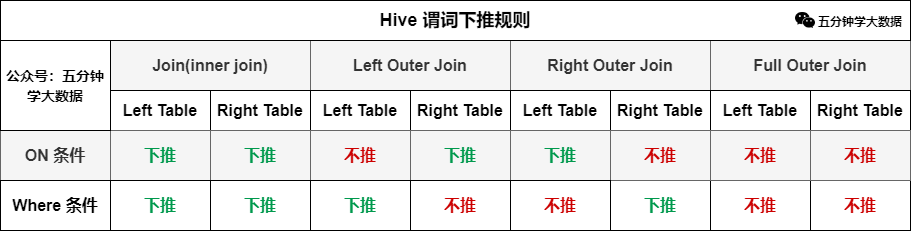
Hive参数与性能企业级调优(建议收藏)
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数...
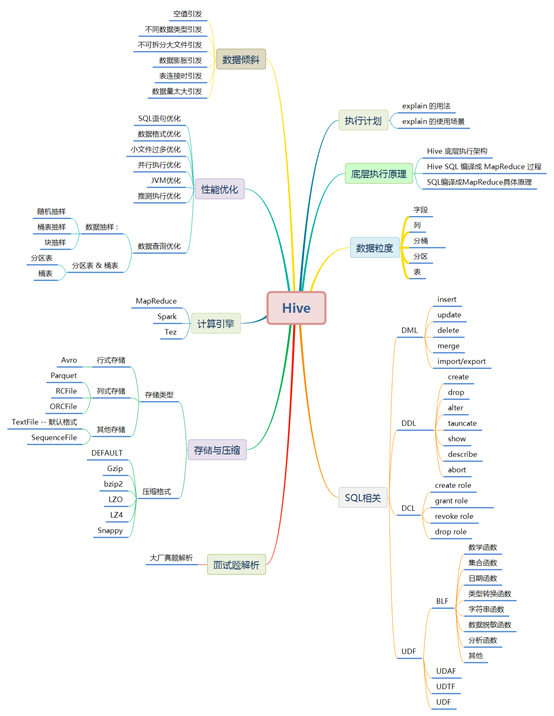
Hive知识体系保姆级教程
Hive涉及的知识点如下图所示,本文将逐一讲解: 正文开始: 一. Hive概览 1.1 hive的简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功...
Hive十亿级以上数据全局排序的一种实现方式
背景 大数据时代,日常工作中经常会处理数以亿计的数据。笔者近期就遇到了一个十亿级以上的数据排序需求,并输出序号。如果是小规模数据我们直接使用row_number全局排序就可以了,但是当数据规模...
