
技术学习 第2页
技术学习,技术分析,问题讨论
排序
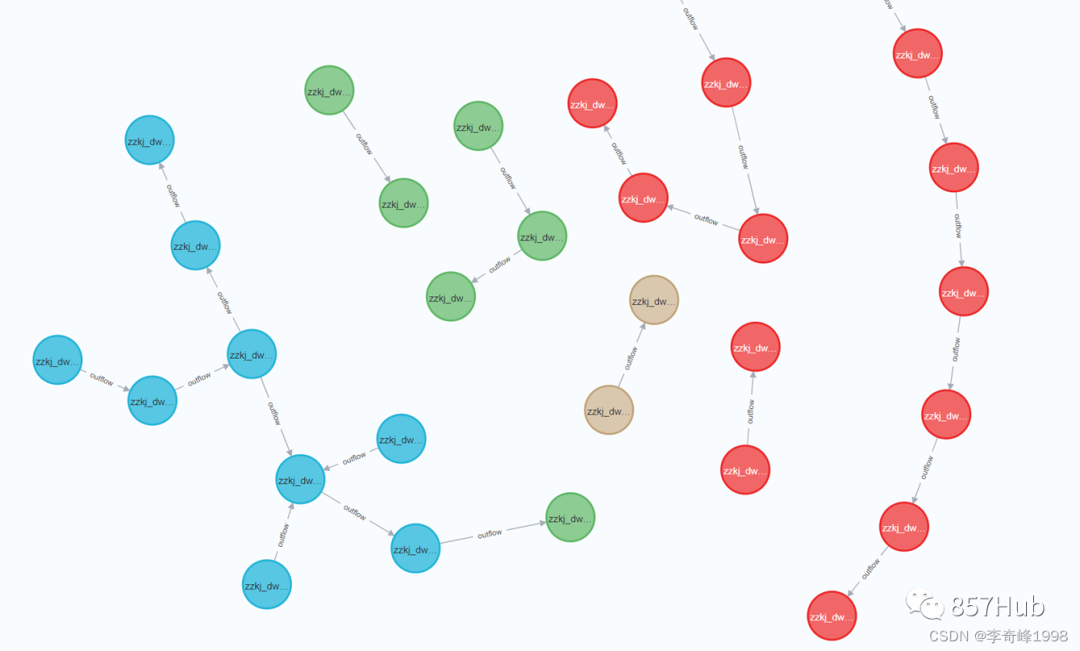
【实战讲解】数据血缘落地实施
在复杂的社会分工协作体系中,我们需要明确个人定位,才能更好的发挥价值,数据也是一样,于是,数据血缘应运而生。 今天这篇文章会全方位的讲解数据血缘,并且给出具体的落地实施方案。 蔡博士...
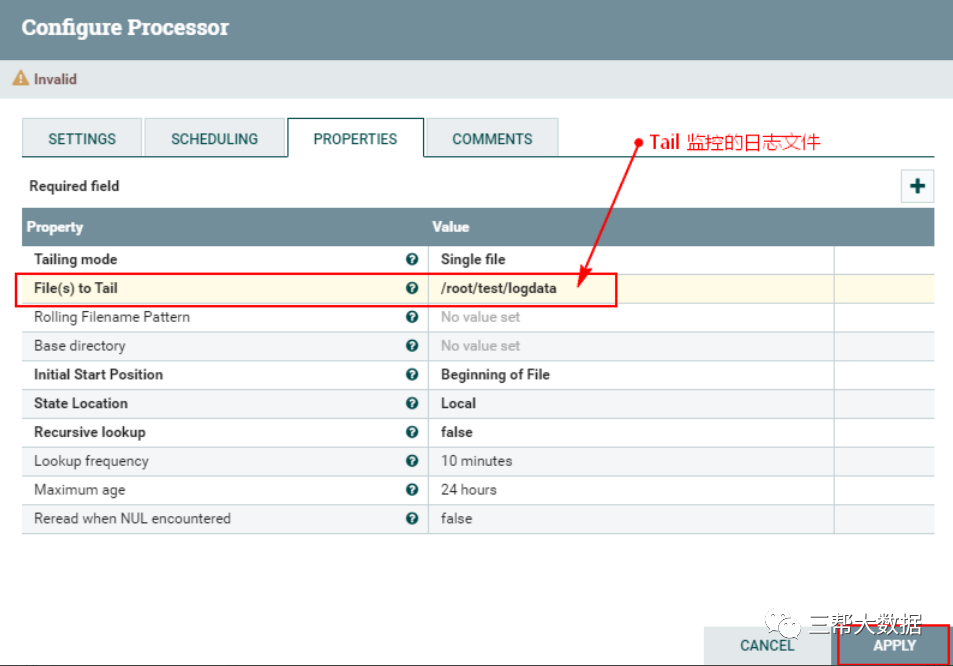
大数据NiFi(二十一):监控日志文件生产到Kafka
监控日志文件生产到Kafka 案例:监控某个目录下的文件内容,将消息生产到Kafka中。 此案例使用到“TailFile”和“PublishKafka_1_0”处理器。 一、配置“TailFile”处理器 创建“TailFile”处理...

数据仓库之数据指标体系建设:概述篇、建设篇、应用篇(全)
在当今数字化时代,数据已成为企业的核心资产之一。随着信息技术的飞速发展,企业能够收集和存储的数据量呈指数级增长。然而,数据本身并不等同于信息,更不等同于智慧。如何从海量的数据中提取...

业务部门的“不作为”杀死了数据治理?
'我们业务太忙!' 当你想把数据治理的失败归咎于这句话时,就要想想:业务为什么不配合? 这就像一个项目经理抱怨开发不写文档——你也得先问问自己,写这文档到底有什么用。 业务其实一直在做...

2024中国软件150强出炉
近日,中国科学院旗下权威媒体《互联网周刊》联合德本咨询等共同布“2024中国软件150强”榜单。榜单根据一套严格的评估体系评定出的结果,评定因素会涉及技术实力、市场地位、服务质量、发展前...
Hive十亿级以上数据全局排序的一种实现方式
背景 大数据时代,日常工作中经常会处理数以亿计的数据。笔者近期就遇到了一个十亿级以上的数据排序需求,并输出序号。如果是小规模数据我们直接使用row_number全局排序就可以了,但是当数据规模...
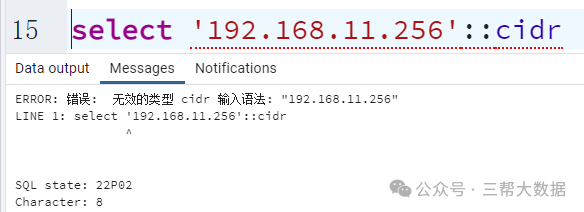
PostgreSQL基础(六):PostgreSQL基本操作(二)
PostgreSQL基本操作(二) 一、字符串类型 字符串类型用的是最多的一种,在PGSQL里,主要支持三种: character(就是MySQL的char类型),定长字符串。(最大可以存储1G) character varying(va...
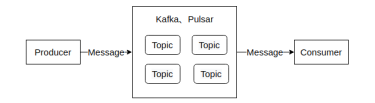
两个优秀的分布式消息流平台:Kafka与Pulsar剖析
本文向读者介绍两个优秀的分布式消息流平台:Kafka与Pulsar。Kafka与Pulsar。 Apache Kafka(简称Kafka) Apache Pulsar(简称Pulsar) 基础功能: (1)消息系统: 优点: 系统解耦:生产者与...
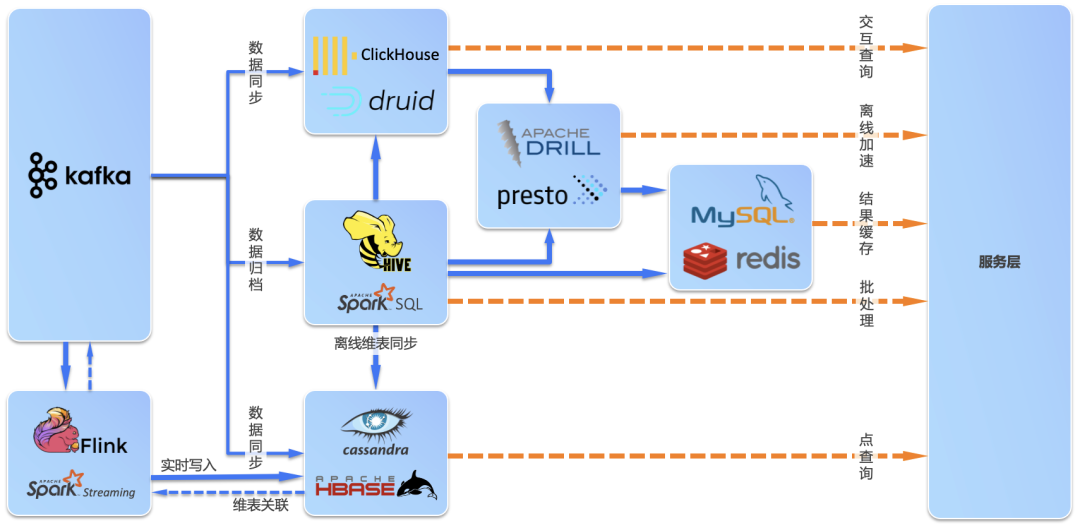
实时数仓分层架构超全解决方案
ODS:Operation Data Store,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,是后续数据仓库加工数据的来源。 DW数据分层,由下到上一般分为DWD,DWB,DWS。 D...

普通人如何抓住DeepSeek红利?(65页PPT)
下面这份PPT探讨了普通人如何利用 DeepSeek 这款通用人工智能工具来提升工作效率、学习效率和生活质量。介绍了 DeepSeek 的功能和能力,包括文本生成、语义分析、代码生成等,并展示了其深度思...
