




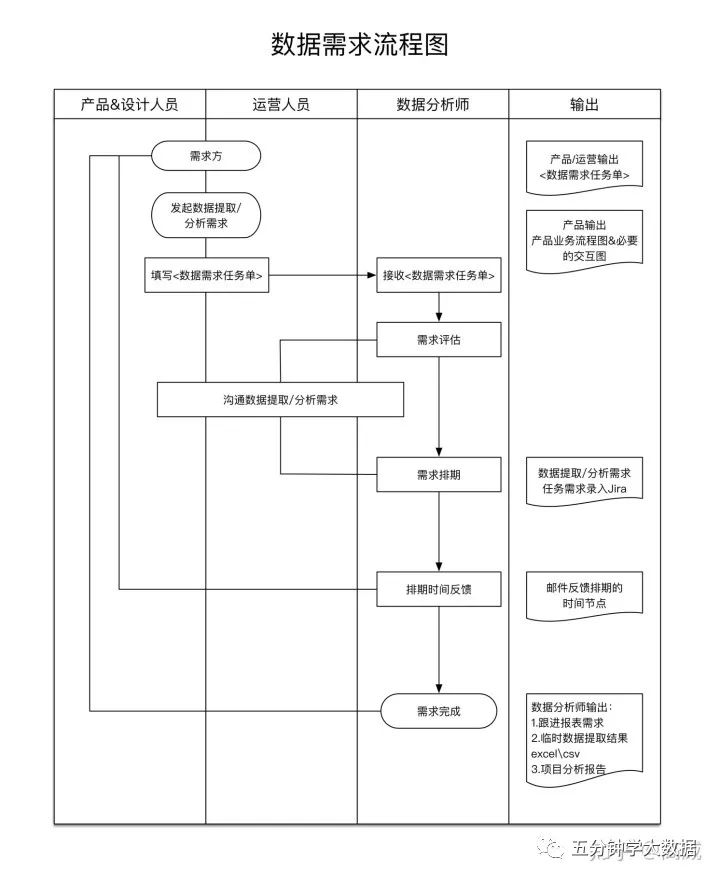
数据开发流程规范及数据监控
一、背景 在大数据时代,规范地进行数据资产管理已成为推动互联网、大数据、人工智能和实体经济深度融合的必要条件。贴近业务属性、兼顾研发各阶段要点的研发规范,可以切实提高研发效率,保障...
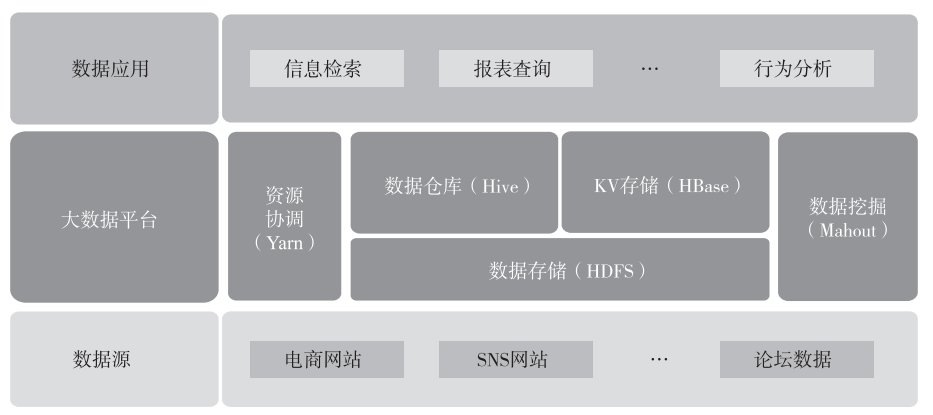
一篇讲明白 Hadoop 生态的三大部件
一篇讲明白 Hadoop 生态的三大部件 ================================================== 大数据技术的发展并不是偶然的,它的背后是对于成本的考量。集中式数据库或者基于MPP架构的分布数据库...
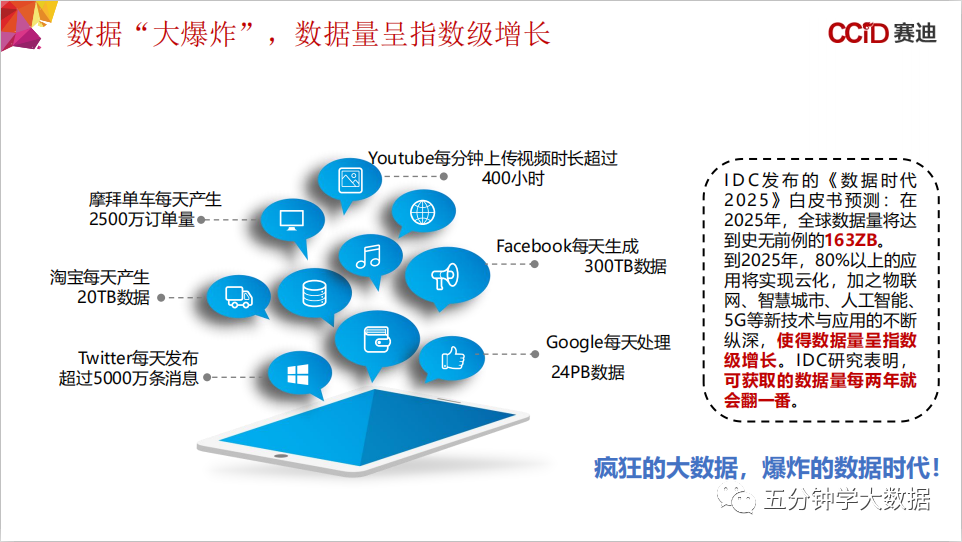
9000字详解数据治理和数据分类分级
01 数据分类分级提出的背景 数据的价值 1.数据爆炸时代,数据量呈指数级增长 我们要如何看待数据这个话题。数据大爆炸已经成为了一个趋势,随着数字化转型的步伐逐步加快,数据的诞生不断加快。...
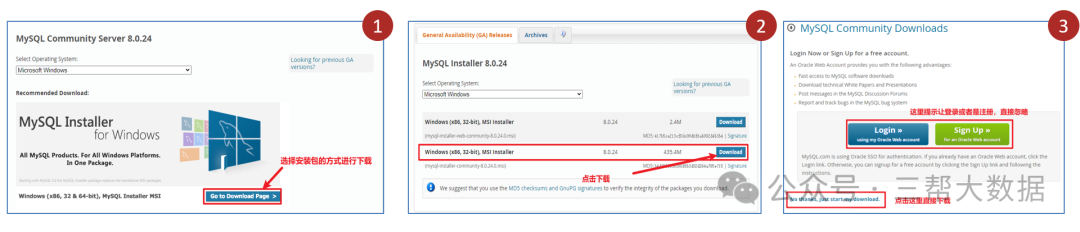
MySQL数据库基础(二):MySQL数据库介绍
MySQL数据库介绍 一、MySQL介绍 MySQL是一个关系型数据库管理系统,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件,它是由瑞典...

Shuffle慢?数据倾斜?Spark 1.0~4.0调优秘籍
一、背景 Spark SQL 通过缓存优化、分区管理、统计信息利用和动态执行计划调整等技术,显著提升 DataFrame 或 SQL 任务的性能。合理配置以下策略可解决数据倾斜、内存溢出、执行效率低下等常见...
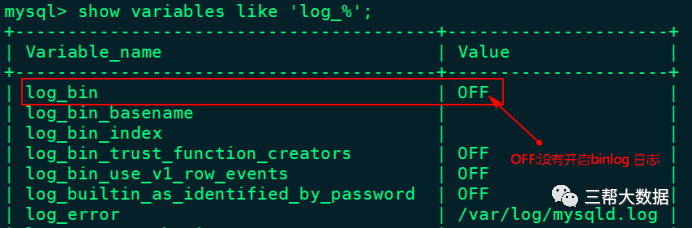
大数据NiFi(二十):实时同步MySQL数据到Hive
实时同步MySQL数据到Hive 案例:将mysql中新增的数据实时同步到Hive中。 以上案例需要用到的处理器有:“CaptureChangeMySQL”、“RouteOnAttribute”、“EvaluateJsonPath”、“ReplaceText”...

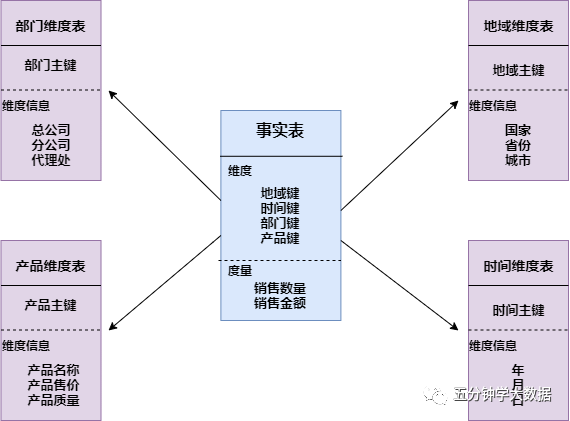
抖音集团数据血缘深度应用:架构、指标与优化实践
正文开始 导读 本次分享将聚焦于资产体系中的全链路血缘,文章将围绕下面四点展开:本次分享将聚焦于资产体系中的全链路血缘,文章将围绕下面四点展开: 1. 抖音集团血缘整体介绍 2. 抖音集团...
2023版最新最强大数据面试宝典
此套面试题来自于各大厂的真实面试题及常问的知识点,如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待! 目前已经更新到第4版,广受好评! 复习大数据面试题,看这一套...
DeepSeek在数据领域的100个应用场景
DeepSeek作为一款前沿的人工智能技术,以其卓越的适应性和多功能性,在众多领域展现出非凡的应用价值。 以下是100个DeepSeek在数据领域的应用场景,展示了DeepSeek如何为数据行业注入智能化动力...
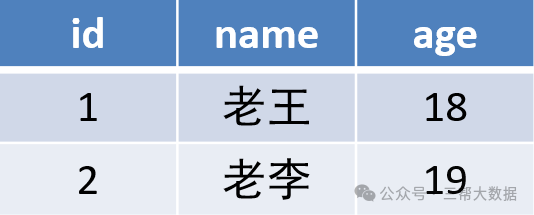
MySQL数据库基础(十三):关系型数据库三范式介绍
关系型数据库三范式介绍 一、什么是三范式 设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余...
