





PostgreSQL基础(十二):PostgreSQL备份和恢复介绍
PostgreSQL备份和恢复介绍 防止数据丢失的第一道防线就是备份。数据丢失有的是硬件损坏,还有人为的误删之类的,也有BUG的原因导致误删数据。 正常备份和恢复,如果公司有DBA,一般咱们不用参与...
PostgreSQL基础(十四):PostgreSQL的数据迁移
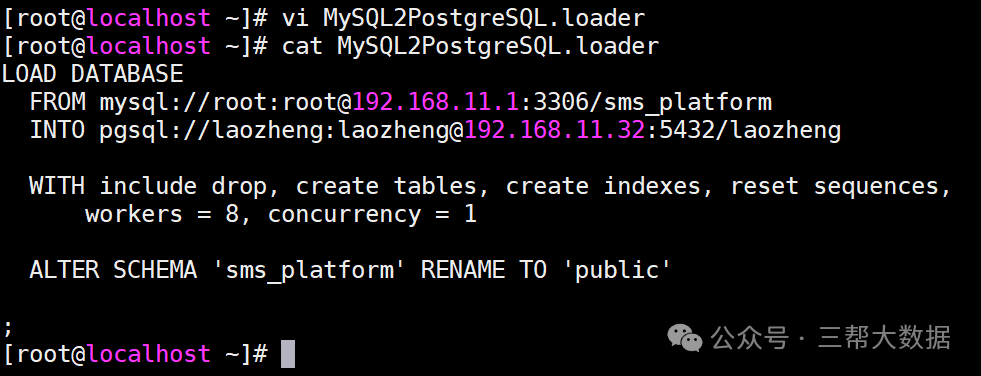
PostgreSQL的数据迁移 PostgreSQL做数据迁移的插件非常多,可以从MySQL迁移到PostgreSQL也可以基于其他数据源迁移到PostgreSQL。 这种迁移的插件很多,这里只说一个,pgloader(非常方便) 以My...
PostgreSQL基础(十五):PostgreSQL的主从操作
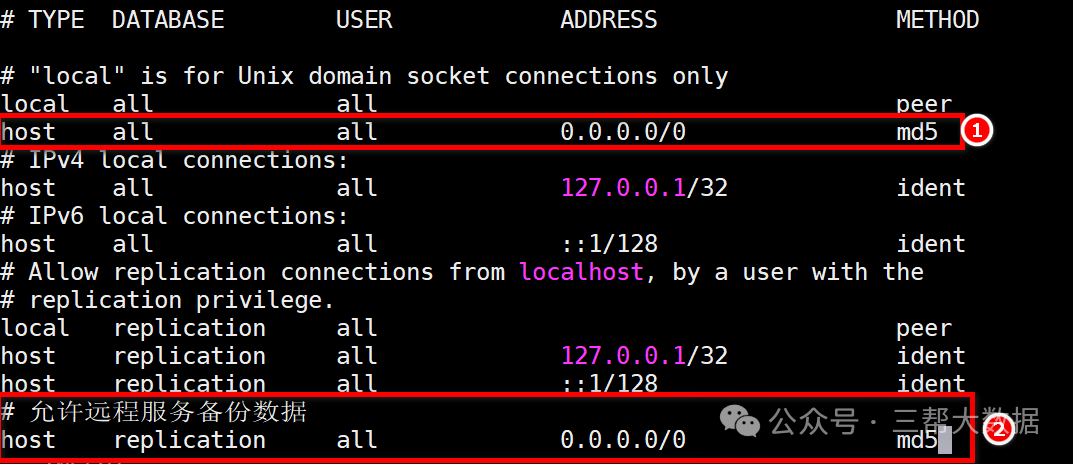
PostgreSQL的主从操作 PostgreSQL自身只支持简单的主从,没有主从自动切换,仿照类似Nginx的效果一样,采用keepalived的形式,在主节点宕机后,通过脚本的执行完成主从切换。 一、主从实现(异...

Spark SQL 复杂类型高阶函数详解
spark sql 2.4 新增了高阶函数功能,允许在数组类型中像 scala/python 一样使用高阶函数 背景 复杂类型的数据和真实数据模型相像,但是使用sql操作较为困难,一般需要借助于 explod/collect_lis...
Shuffle慢?数据倾斜?Spark 1.0~4.0调优秘籍
一、背景 Spark SQL 通过缓存优化、分区管理、统计信息利用和动态执行计划调整等技术,显著提升 DataFrame 或 SQL 任务的性能。合理配置以下策略可解决数据倾斜、内存溢出、执行效率低下等常见...
SeaTunnel 与 DataX 、Sqoop、Flume、Flink CDC 对比
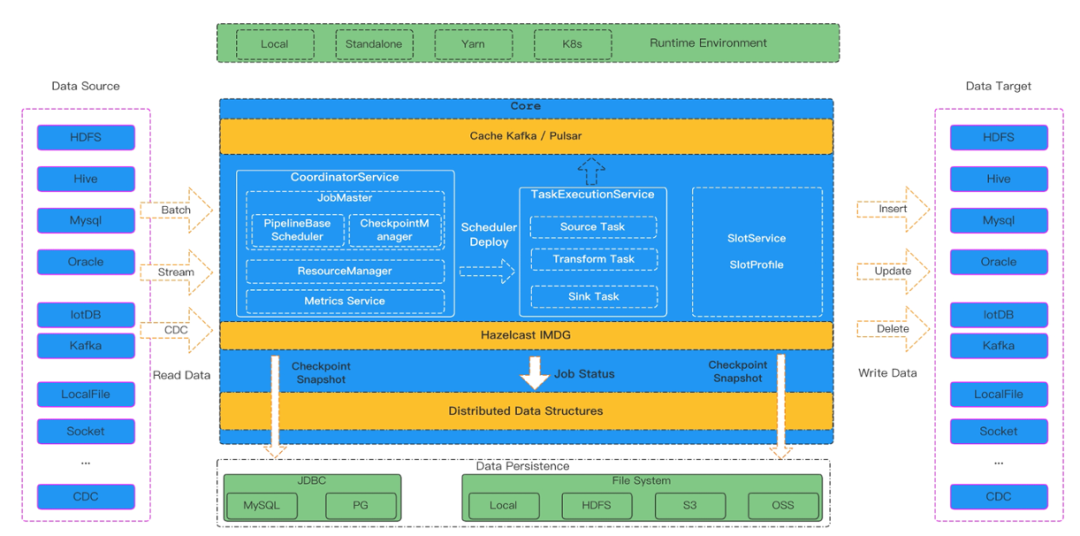
产品概述 Apache SeaTunnel 是一个非常易用的超高性能分布式数据集成产品,支持海量数据的离线及实时同步。每天可稳定高效同步万亿级数据,已应用于数百家企业生产,也是首个由国人主导贡献到 A...
Spark底层执行原理详细解析
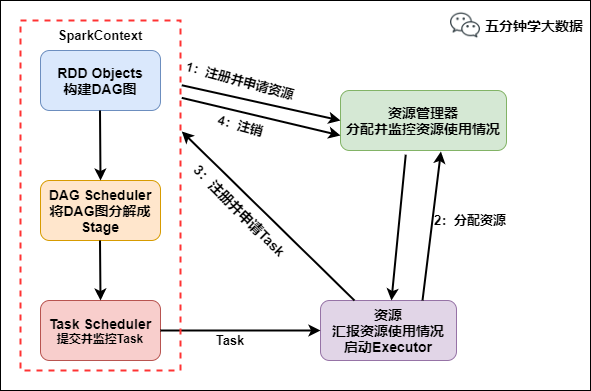
Spark简介 大规模数据处理高容错性高可伸缩性 Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执...

Spark数据倾斜解决
一、数据倾斜表现 数据倾斜就是数据分到各个区的数量不太均匀,可以自定义分区器,想怎么分就怎么分。 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据...
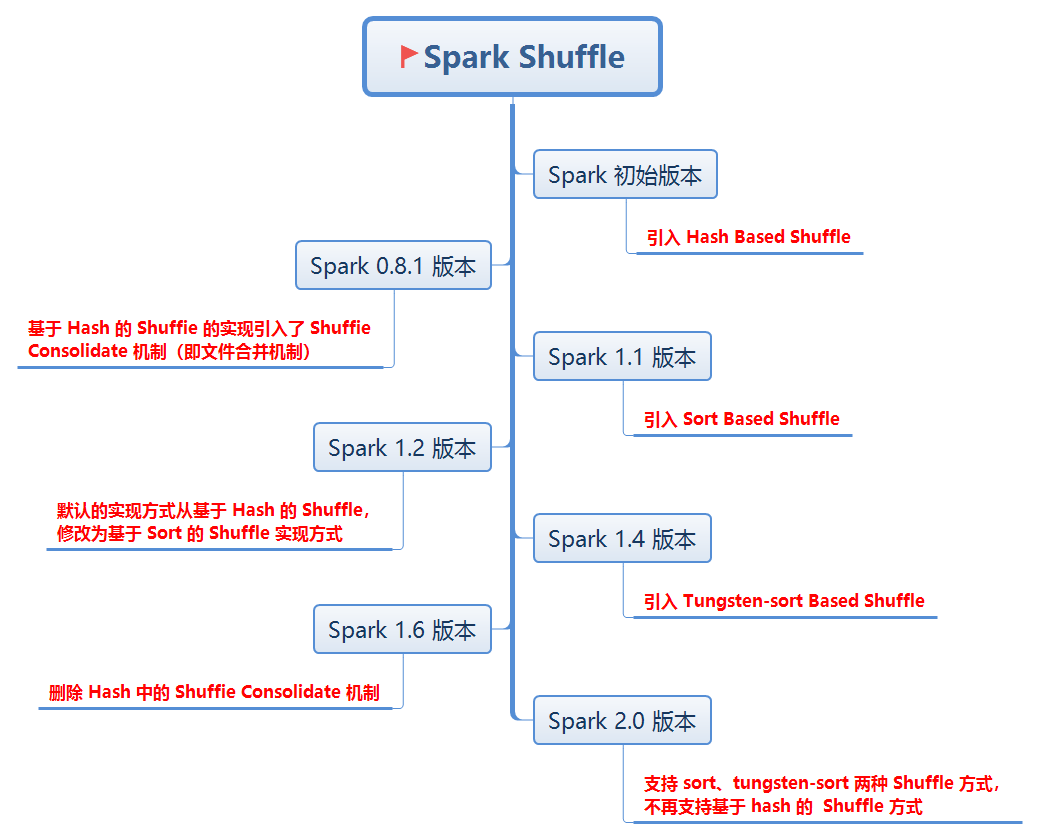
Spark的两种核心Shuffle详解
由于 Shuffle 涉及磁盘的读写和网络 I/O,因此 Shuffle 性能的高低直接影响整个程序的性能 Spark Shuffle Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle...
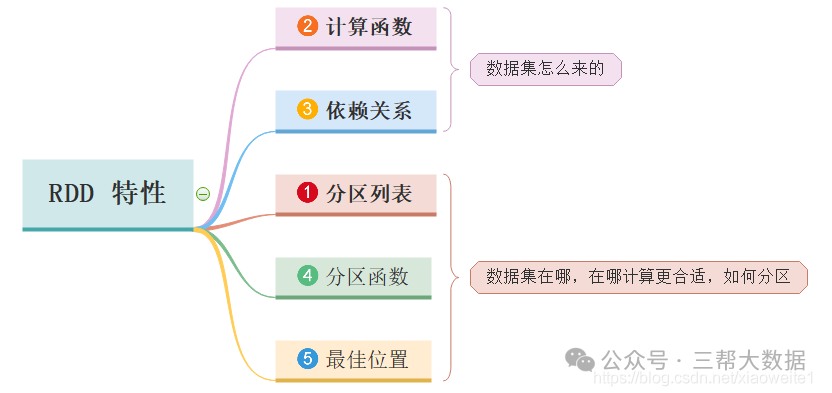
Spark重要知识汇总
一、Spark 是什么 大规模数据处理的统一分析引擎,也可说是分布式内存迭代计算框架。 二、Spark 四大特点 三、Spark框架模块介绍 3.1、Spark Core的RDD详解 3.1.1、什么是RDD 不可变、可分区、...
