

1粉丝:我们团队习惯了做业务数据的质量监控,有成熟的完整性、一致性、准确性校验方法。但现在接触音频、图像数据,以前的经验好像都用不上。这种非结构化数据,质量到底该怎么评估和提升?
说实话,这个问题也让我思考了很久。
我在结构化和半结构化数据质量方面也算是经验比较丰富,但一脚踏入大模型和非结构化数据的地盘,突然就变成了“新兵”
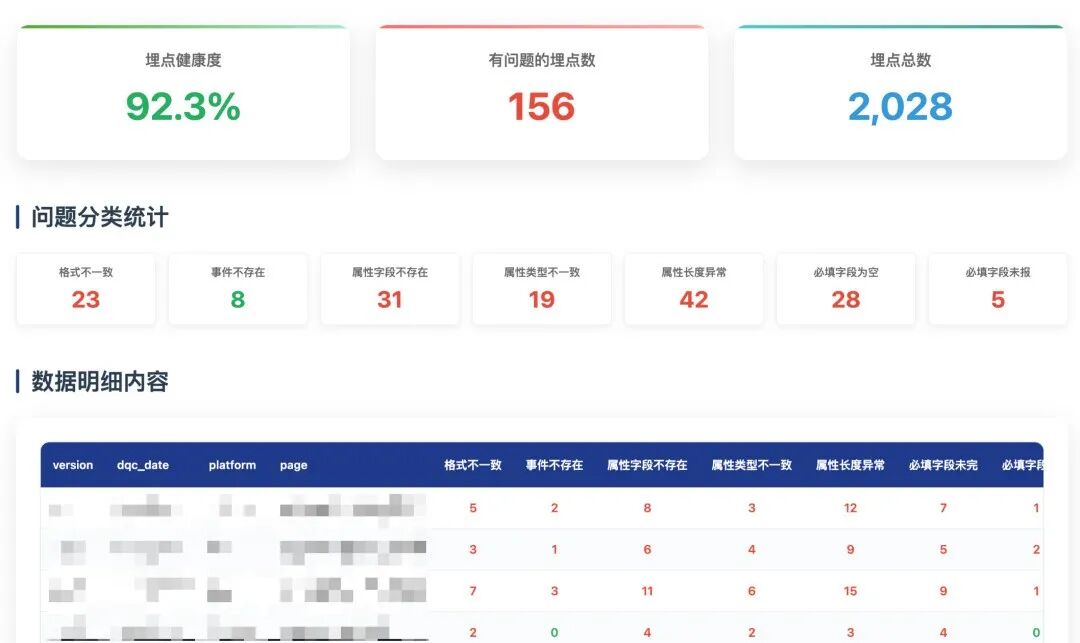
过去那套围绕着表、字段、枚举值的质量体系,面对一段音频、一张图片时,显得无从下手。虽然我有一些思路,但总觉得不够体系化。
但缺少经过来自一线的、压箱底的认证,心里始终不确定,我特意约了两位分别在Top的游戏公司做音频的算法老友,搓了一顿饭。
目的很明确,就是要把他们内部真正的实践经验给“套”出来。他们也很坦诚,也是一路踩坑过来,筛选了N个标准,留下最好用的几种标准。
评估音频数据质量,绝对不能只看波形图,而是要从“机器听得怎么样”和“人听得怎么样”两个维度,大厂内部用三个核心指标来量化
2.Word Error Rate – 内容准确性
它的逻辑很简单:拿机器转录的文本,和我们人工精标的“标准答案”去比,看看到底错在哪,错了多少。计算公式为:
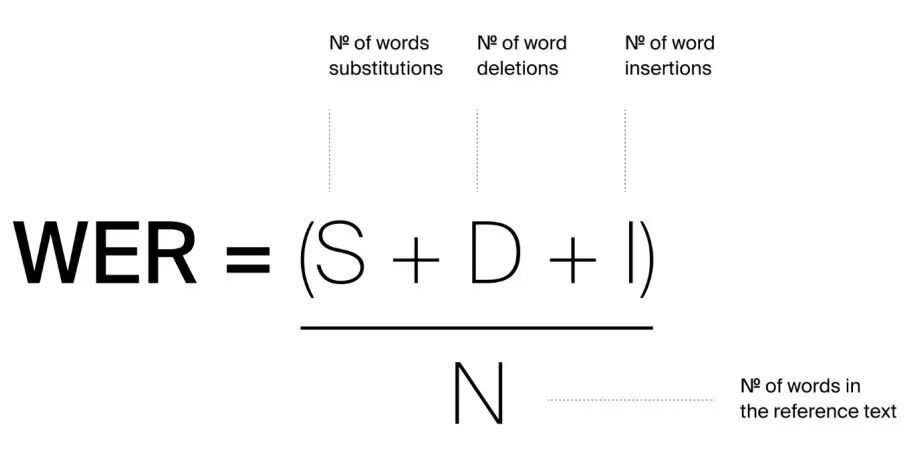
替换的字数 S
删除的字数 D
插入的字数 I
标准答案的总字数 N
WER值越低,说明数据的内容越清晰,越容易被机器准确识别。如果一批数据的平均WER居高不下,那就证明这批数据本身“信噪比”太差或者“口音”太重,属于需要被清洗的“劣质”
3.Signal-to-Noise Ratio – 音频纯净度
搞定WER,只是保证了‘能听懂
老友:但要让模型‘学得好’,还得看SNR”
SNR,即信噪比,是衡量有效信号与背景噪声相对强度的物理量。

简单说,SNR越高,音频就越“干净”,人声越突出。反之,SNR低,就意味着各种环境噪音、电流声混杂其中。
老友打了个比方:“你不能指望模型在一片嘈杂的菜市场里,学会辨认耳语。给模型的数据,信噪比必须过关。”
在他们的实践中,通常会设定一个明确的SNR阈值(比如15dB),批量过滤掉低于这个阈值的数据,这是保证模型训练稳定性的关键一步。
4.最后,也是最容易被忽略的一点,就是MOS
老友道:“技术指标终究是为人的体验服务的”
MOS,即平均主观意见分,是一个完全基于“人”的指标。
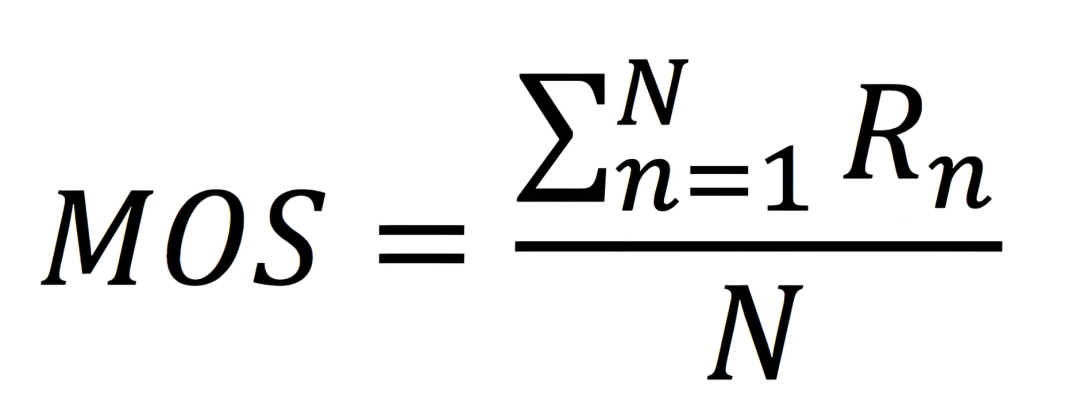
操作上,就是找一批专业的标注员,对音频的自然度、清晰度、流畅度等进行1-5分的打分,然后取平均值。

一个MOS分很低的数据,即便WER和SNR都达标,也可能因为包含了不自然的停顿、奇怪的电音等问题,从而“带偏”模型。
因此,MOS是数据质量评估的最后一道,也是最重要的一道防线。
5.回来后我立刻整理了下,把WER的评估用Python快速实现了一下。
这里我跳过音频转文字的过程,也是通过调用API服务,但不影响我实现评估数据质量目的。
首先,安装jiwer库:
然后,代码实现非常简单:

输出结果

这顿饭局最大的收获,不是知道了几个新名词,而是完成对非结构化数据质量的“祛魅”
在此之前,我们这些做惯了结构化数据的人,可能会觉得音频、图像的质量评估是一个很“玄”的东西,似乎全凭主观感觉。
但当WER、SNR、MOS这三个可量化、可执行的指标摆在面前时,你会发现,它并非什么高深莫测的理论,而是一套同样严谨、有章可循的工程方法
知道这些指标,只是第一步,关键在于,你是否动手去实践,把它们融入到你的工作流中
真正的成长,始于祛魅之后







暂无评论内容