

性能也能得到数量级的提升
Hive 数据存储常用的格式如下:
行式存储
文本格式(TextFile)
二进制序列化文件 (SequenceFile)
列式存储
行列式文件(RCFile)
优化的行列式文件(ORCFile)
Apache Parquet
注:RCFile 和 ORCFile 并不是纯粹的列式存储,它是先基于行对数据表进行分组(行组),然后对行组进行列式存储
我们看下这几种存储结构的优缺点:
行存储模式就是把一整行存在一起,包含所有的列,这是最常见的模式。这种结构能很好的适应动态的查询。
比如:select a from tableA 和 select a, b, c, d, e, f, g from tableA这样两个查询其实查询的开销差不多,都需要把所有的行读进来过一遍,拿出需要的列。
而且这种情况下,属于同一行的数据都在同一个 HDFS块上,重建一行数据的成本比较低。
但是这样做有两个主要的弱点:
当一行中有很多列,而我们只需要其中很少的几列时,我们也不得不把一行中所有的列读进来,然后从中取出一些列。这样大大降低了查询执行的效率。
基于多个列做压缩时,由于不同的列数据类型和取值范围不同,压缩比不会太高。
列存储是将每列单独存储或者将某几个列作为列组存在一起。列存储在执行查询时可以避免读取不必要的列。而且一般同列的数据类型一致,取值范围相对多列混合更小,在这种情况下压缩数据能达到比较高的压缩比。
但是这种结构在重建行时比较费劲,尤其当一行的多个列不在一个 HDFS 块上的时候。比如我们从第一个 DataNode 上拿到 column A,从第二个 DataNode 上拿到了 column B,又从第三个DataNode 上拿到了 column C,当要把 A,B,C 拼成一行时,就需要把这三个列放到一起重建出行,需要比较大的网络开销和运算开销。
PAX 结构是将行存储和列存储混合使用的一种结构,主要是传统数据库中提高 CPU 缓存利用率的一种方法,并不能直接用到 HDFS 中。但是 RCFile 和 ORC 是继承自它的思想,先按行存再按列存。
接下来我们看下在 Hive 中常用的几种存储格式:
本文重点讲解最后两种:Apache ORC 和 Apache Parquet
一、TextFile
TextFile 为 Hive 默认格式
创建一个 TextFile 格式的 Hive 表:
向 TextFile 表中加载数据:
TextFile 优缺点
直接使用 load 方式加载数据
TextFile 格式虽然可以使用 Gzip 压缩算法,但压缩后的文件不支持 split。在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比 SequenceFile 高几十倍。
二、SequenceFile
二进制文件
SequenceFIle 的内部格式取决于是否启用压缩,如果是压缩,则又可以分为记录压缩和块压缩。
无压缩(NONE)
记录压缩(RECORD)
块压缩(BLOCK)Record 压缩率低,一般建议使用 BLOCK 压缩。
创建一个 SequenceFile 格式的 Hive 表:
设置压缩格式为块压缩:
向 SequenceFile 表中加载数据:
SequenceFile 优点
支持基于记录(Record)或块(Block)的数据压缩。
支持 splitable,能够作为 MapReduce 的输入分片。
修改简单:主要负责修改相应的业务逻辑,而不用考虑具体的存储格式。
SequenceFile 的缺点
三、RCFile
RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先水平划分,再垂直划分的理念。
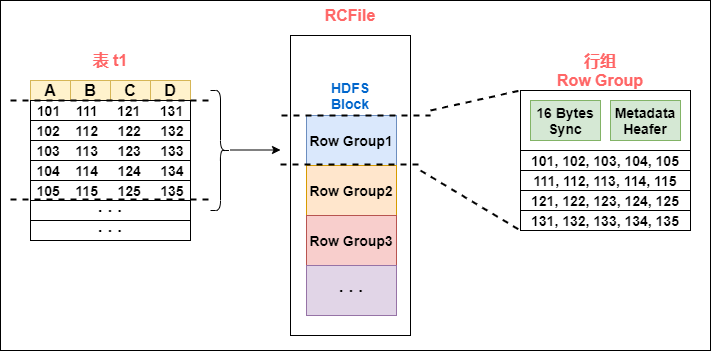
首先对表进行行划分,分成多个行组。一个行组主要包括:
16 字节的 HDFS 同步块信息,主要是为了区分一个 HDFS 块上的相邻行组;
元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;
数据部分我们可以看出 RCFile 将每一行,存储为一列,将一列存储为一行,因为当表很大,我们的字段很多的时候,我们往往只需要取出固定的一列就可以。
在一般的行存储中 select a from table,虽然只是取出一个字段的值,但是还是会遍历整个表,所以效果和 select * from table 一样,在 RCFile 中,像前面说的情况,只会读取该行组的一行。
创建一个 RCFile 的表:
在存储空间上
行划分,列存储游程编码
懒加载
数据存储到表中都是压缩的数据,Hive 读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
如:
针对行组来说,会对一个行组的 a 列进行解压缩,如果当前列中有 a>1 的值,然后才去解压缩 c。若当前行组中不存在 a>1 的列,那就不用解压缩 c,从而跳过整个行组。
四、ORCFile
1. ORC相比较 RCFile 的优点
ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化
ORC 扩展了 RCFile 的压缩,除了 Run-length(游程编码),引入了字典编码和 Bit 编码。
每个 task 只输出单个文件,这样可以减少 NameNode 的负载;
支持各种复杂的数据类型,比如:datetime,decimal,以及一些复杂类型(struct, list, map,等);
文件是可切分(Split)的。在 Hive 中使用 ORC 作为表的文件存储格式,不仅节省 HDFS 存储资源,查询任务的输入数据量减少,使用的 MapTask 也就减少了。
采用字典编码,最后存储的数据便是字典中的值,及每个字典值的长度以及字段在字典中的位置;采用 Bit 编码,对所有字段都可采用 Bit 编码来判断该列是否为 null,如果为 null 则 Bit 值存为 0,否则存为 1,对于为 null 的字段在实际编码的时候不需要存储,也就是说字段若为 null,是不占用存储空间的。
2. ORC的基本结构
ORCFile 在 RCFile 基础上引申出来 Stripe 和 Footer 等。每个 ORC 文件首先会被横向切分成多个 Stripe,而每个 Stripe 内部以列存储,所有的列存储在一个文件中,而且每个 stripe 默认的大小是 250MB,相对于 RCFile 默认的行组大小是 4MB,所以比 RCFile 更高效。
下图是 ORC 的文件结构示意图:
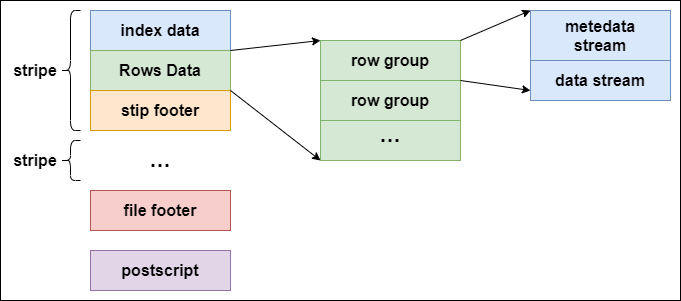
ORC 文件结构由三部分组成:
条带(stripe)
文件脚注(file footer)
postscript
stripe 结构同样可以分为三部分:index data、rows data 和 stripe footer:
index data
rows data
stripe footer
rows data 存储两部分的数据,即 metadata stream 和 data stream:
metadata stream
data stream
ORC 在每个文件中提供了 3 个级别的索引:
文件级
条带级别
行组级别
程序可以借助 ORC 提供的索引加快数据查找和读取效率。程序在查询 ORC 文件类型的表时,会先读取每一列的索引信息,将查找数据的条件和索引信息进行对比,找到满足查找条件的文件。
接着根据文件中的索引信息,找到存储对应的查询条件数据 stripe,再借助 stripe 的索引信息读文件中满足查询条件的所有 stripe 块。
之后再根据 stripe 中每个行组的索引信息和查询条件比对的结果,找到满足要求的行组。
通过 ORC 这些索引,可以快速定位满足查询的数据块,规避大部分不满足查询条件的文件和数据块,相比于读取传统的数据文件,进行查找时需要遍历全部的数据,使用 ORC 可以避免磁盘和网络 I/O 的浪费,提升程序的查找效率,提升整个集群的工作负载。
3. ORC 的数据类型
Hive 在使用 ORC 文件进行存储数据时,描述这些数据的字段信息、字段 类型信息及编码等相关信息都是和 ORC 中存储的数据放在一起的。
ORC 中每个块中的数据都是自描述的,不依赖外部的数据,也不存储在 Hive 的元数据库中。
ORC 提供的数据数据类型包含如下内容:
整型
浮点型
字符串类型
二进制类型
日期和时间类型
复杂类型
目前 ORC 基本已经兼容了日常所能用到的绝大部分的字段类型。另外,ORC 中所有的类型都可以接受 NULL 值。
4. ORC 的 ACID 事务的支持
在 Hive 0.14 版本以前,Hive 表的数据只能新增或者整块删除分区或表,而不能对表的单个记录进行修改。
ORC 文件能够确保 Hive 在工作时的原子性、一致性、隔离性和持久性的 ACID 事务能够被正确地得到使用,使得对数据更新操作成为可能
Hive 是面向 OLAP 的,所以它的事务也和 RDMBS 的事务有一定的区别。Hive 的事务被设计成每个事务适用于更新大批量的数据,而不建议用事务频繁地更新小批量的数据。
创建 Hive 事务表的方法
5. ORC 相关的 Hive 配置
表的属性配置项有如下几个:
表示 ORC 文件的压缩类型,可选的类型有 NONE、ZLIB 和 SNAPPY,默认值是 ZLIB
orc.compress.size:表示压缩块(chunk)的大小,默认值是 262144(256KB)。
orc.stripe.size:写 stripe,可以使用的内存缓冲池大小,默认值是 67108864(64MB)。
orc.row.index.stride:行组级别索引的数据量大小,默认是 10000,必须要设置成大于等于 10000 的数。
orc.create.index:是否创建行组级别索引,默认是 true。
orc.bloom.filter.columns:需要创建布隆过滤的组。
orc.bloom.filter.fpp:使用布隆过滤器的假正(False Positive)概率,默认值是 0.05。
注:在 Hive 中使用布隆(bloom)过滤器,可以用较少的文件空间快速判定数据是否存在于表中,但是也存在将不属于这个表的数据判定为属于这个这表的情况,这个情况称之为假正概率,可以手动调整该概率,但概率越低,布隆过滤器所需要的空间越多。
五、Parquet
Parquet 是另外的一种高性能行列式的存储结构,可以适用多种计算框架,被多种查询引擎所支持,包括 Hive、Impala、Drill 等。
1. Parquet 基本结构:
在一个 Parquet 类型的 Hive 表文件中,数据被分成多个行组,每个列块又被拆分成若干的页(Page),如下图所示:
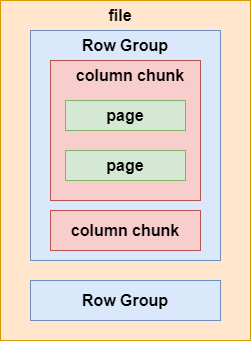
Parquet 在存储数据时,也同 ORC 一样记录这些数据的元数据,这些元数据也同 Parquet 的文件结构一样,被分成多层文件级别的元数据、列块级别的元数据及页级别的元数据。
文件级别的元数据(fileMetadata)记录主要如下:
表结构信息(Schema);
该文件的记录数;
该文件拥有的行组,以及每个行组的数据总量,记录数;
每个行组下,列块的文件偏移量。
列块的元数据信息如下:
记录该列块的未压缩和压缩后的数据大小和压缩编码;
数据页的偏移量;
索引页的偏移量;
列块的数据记录数。
页头的元数据信息如下:
该页的编码信息;
该页的数据记录数。
程序可以借助 Parquet 的这些元数据,在读取数据时过滤掉不需要读取的大部分文件数据,加快程序的运行速度。
同 ORC 的元数据一样,Parquet 的这些元数据信息能够帮助提升程序的运行速度,但是 ORC 在读取数据时又做了一定的优化,增强了数据的读取效率。在查询时所消耗的集群资源比 Parquet 类型少。
Parquet 在嵌套式结构支持比较完美,而 ORC 多层级嵌套表达起来比较复杂,性能损失较大。
2. Parquet 的相关配置:
可以根据不同场景需求进行适当的参数调整,实现程序优化。
parquet.block.size:默认值为 134217728byte,即 128MB,表示 RowGroup 在内存中的块大小。该值设置得大,可以提升 Parquet 文件的读取效率,但是相应在写的时候需要耗费更多的内存。
parquet.page.size:默认值为 1048576byte,即 1MB,表示每个页 (page)的大小。这个特指压缩后的页大小,在读取时会先将页的数据进行解压。页是 Parquet 操作数据的最小单位,每次读取时必须读完一整页的数据才能访问数据。这个值如果设置得过小,会导致压缩时出现性能问题。
parquet.compression:默认值为 UNCOMPRESSED(不压缩),表示页的压缩式。可以使用的压缩方式有 UNCOMPRESSED、SNAPPY、GZIP 和 LZO。
parquet.enable.dictionary:默认为 true,表示是否启用字典编码。
parquet.dictionary.page.size:默认值为 1048576byte,即 1MB。在使用字典编码时,会在 Parquet 的每行每列中创建一个字典页。使用字典编码,如果存储的数据页中重复的数据较多,能够起到一个很好的压缩效果,也能减少每个页在内存的占用。
3. 使用Spark引擎时 Parquet 表的压缩格式配置:
Spark 天然支持 Parquet,并为其推荐的存储格式(默认存储为parquet)。
对于 Parquet 表的压缩格式分以下两种情况进行配置:
对于分区表
需要通过 Parquet 本身的配置项 parquet.compression 设置 Parquet 表的数据压缩格式。如在建表语句中设置:”parquet.compression”=”snappy”。
对于非分区表
需要通过 spark.sql.parquet.compression.code 配置项来设置 Parquet 类型的数据压缩格式。直接设置parquet.compression 配置项是无效的,因为它会读取 spark.sql.parquet.compression.codec 配置项的值。
当 spark.sql.parquet.compression.codec 未做设置时默认值为 snappy,parquet.compression 会读取该默认值。
因此,spark.sql.parquet.compression.codec 配置项只适用于设置非分区表的 Parquet 压缩格式。
4. Parquet 和 ORC 压缩格式对比:
ORC
Parquet






暂无评论内容