

导读:Akin

业务场景
在正式介绍 Apache Doris 在 360 商业化的应用之前,我们先对广告业务中的典型使用场景进行简要介绍:
实时大盘:
广告账户的实时消费数据场景:
实时数仓演进
第一代架构
该阶段的实时数仓是基于 Storm + Druid + MySQL 来构建的,Storm 为实时处理引擎,数据经 Storm 处理后,将数据写入 Druid ,利用 Druid 的预聚合能力对写入数据进行聚合。
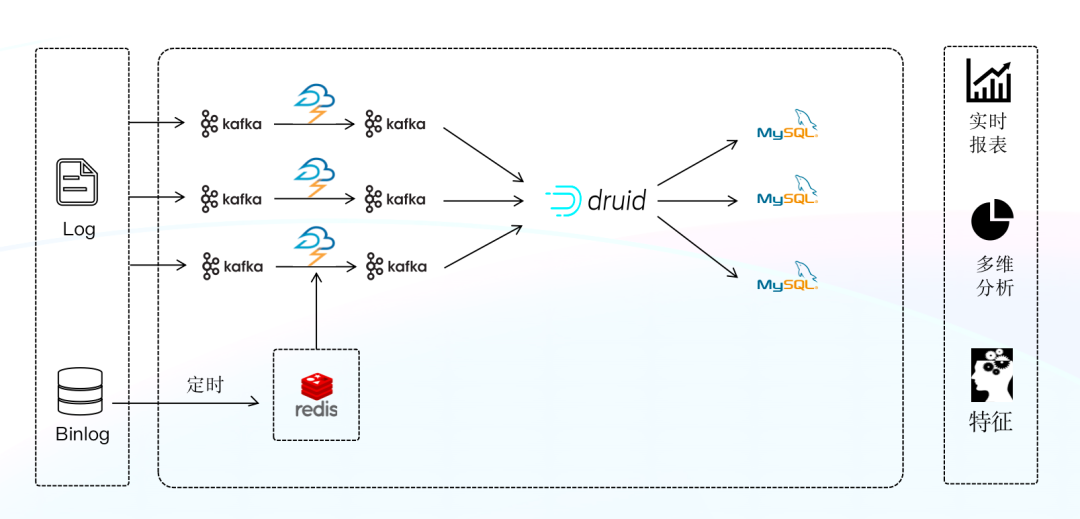
MySQL 的分库分表维护难度高、投入成本大,且 MySQL 表之间的数据一致性无法保障。
第二代架构
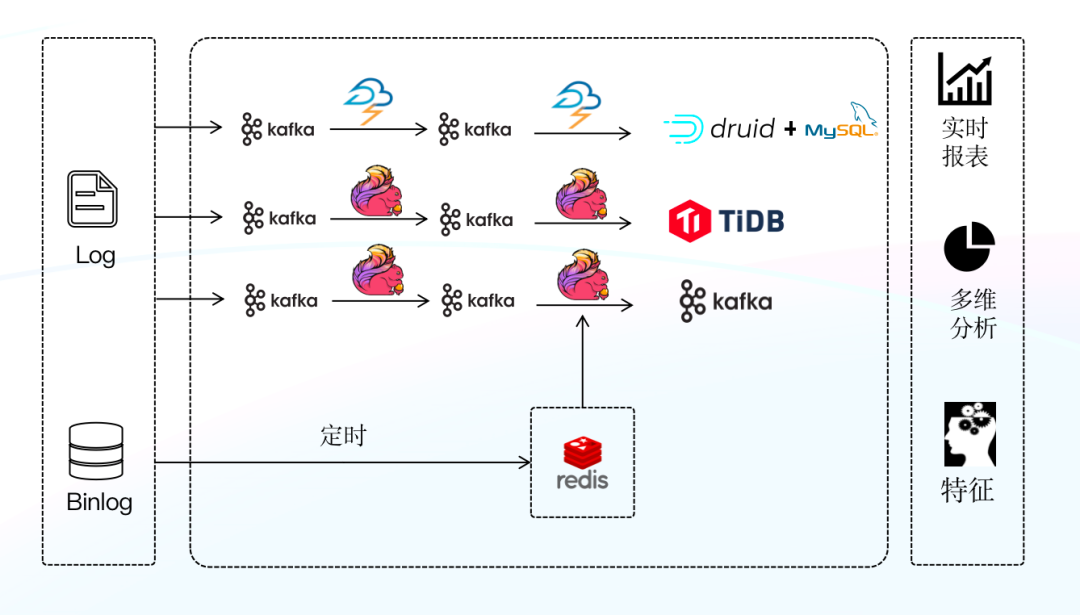
架构痛点:
维护成本较高,需要维护两套引擎和两套查询逻辑,极大增加了维护和开发成本的投入。
新一代实时数仓架构
第二次升级我们引入 Apache Doris 结合 Flink 构建了新一代实时数仓架构,借鉴离线数仓分层理念对实时数仓进行分层构建,并统一 Apache Doris 作为数仓 OLAP 引擎,由 Doris 统一对外提供服务。
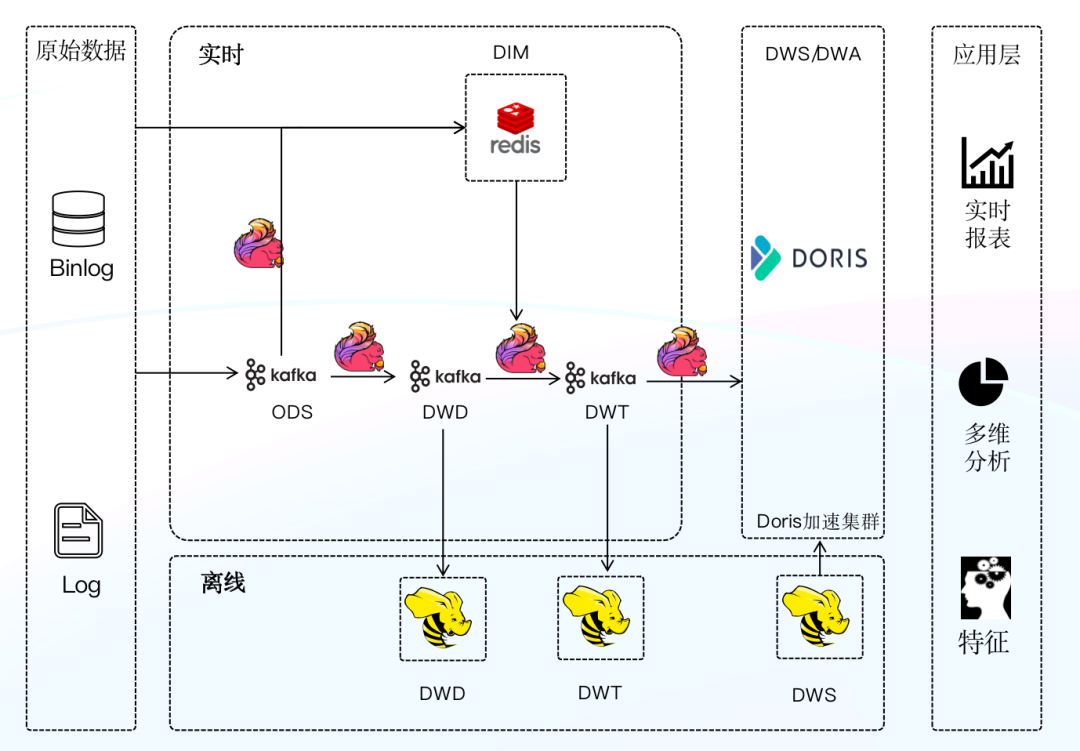
选择 Doris 的原因
基于 Apache Doris 高性能、极简易用、实时统一等诸多特性,助力 360商业化成功构建了新一代实时数仓架构,本次升级不仅提升了实时数据的复用性、实现了 OLAP 引擎的统一,而且满足了各大业务场景严苛的数据查询分析需求,使得整体实时数据流程架构变得简单,大大降低了其维护和使用的成本。我们选择 Doris 作为统一 OLAP 引擎的重要原因大致可归结为以下几点:
物化视图:
数据一致性:
SQL 协议兼容:
优秀的查询性能:
具体应用
Apache Doris 目前广泛应用于 360商业化内部的多个业务场景。比如在实时大盘场景中,我们利用 Doris 的 Aggregate 模型对请求、曝光、点击、转化等多个实时流进行事实表的 Join ;依靠 Doris 事务特性保证数据的一致性;通过多个物化视图,提前根据报表维度聚合数据、提升查询速度,由于物化视图和 Base 表的一致关系由 Doris 来维护保证,这也极大的降低了使用复杂度。比如在账户实时消费场景中,我们主要借助 Doris 优秀的查询优化器,通过 Join 来计算同环比……
数据落地
当面对一条流量可能包含几十个实验标签 ID 的情况时,从分析角度出发,只需要选中一个实验标签和一个对照实验标签进行分析;而如果通过like的方式在几十个实验标签中去匹配选中的实验标签,实现效率就会非常低。
最初我们期望从数据入口处将实验标签打散,将一条包含 20 个实验标签的流量拆分为 20 条只包含一个实验标签的流量,再导入 Doris 的聚合模型中进行数据分析。而在这个过程中我们遇到一个明显的问题,当数据被打散之后会膨胀数十倍,百亿级数据将膨胀为千亿级数据,即便 Doris 聚合模型会对数据再次压缩,但这个过程会对集群造成极大的压力。因此我们放弃该实现方式,开始尝试将压力分摊一部分到计算引擎,这里需要注意的是,如果将数据直接在 Flink 中打散,当 Job 全局 Hash 的窗口来 Merge 数据时,膨胀数十倍的数据也会带来几十倍的网络和 CPU 消耗。
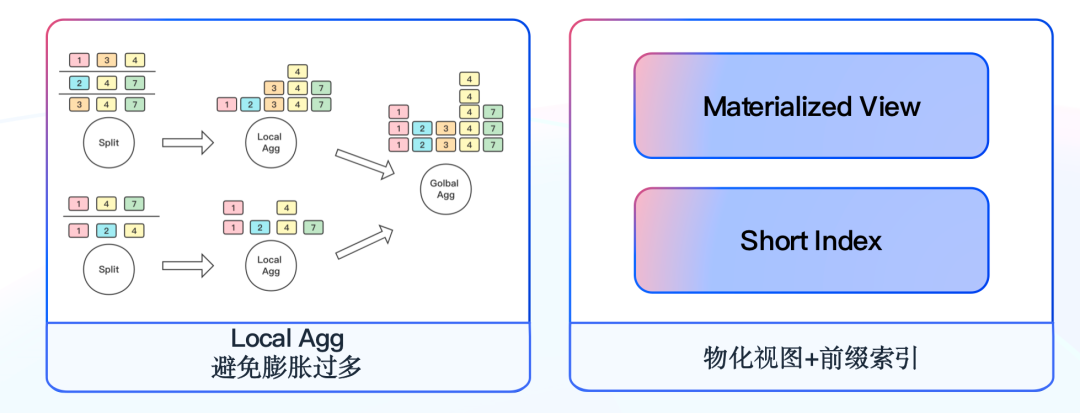
数据一致性保障
数据的准确性是 AB实验平台的基础,当算法团队呕心沥血优化的模型使广告效果提升了几个百分点,却因数据丢失看不出实验效果,这样的结果确实无法令人接受,同时这也是我们内部不允许出现的问题。那么我们该如何避免数据丢失、保障数据的一致性呢?
自研 Flink Sink Doris 组件
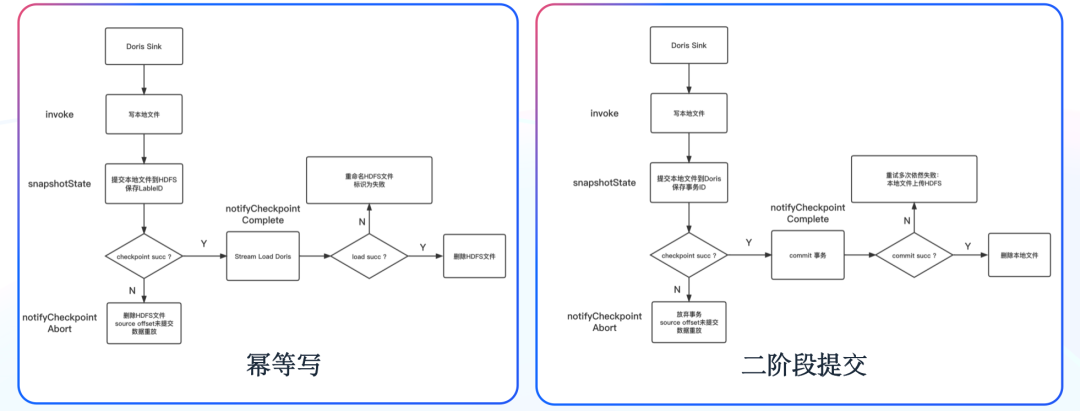
在 Flink 中做到数据端到端的一致性有两种方式,一种为通过至少一次结合幂等写,一种为通过恰好一次的二阶段事务。
应用展示
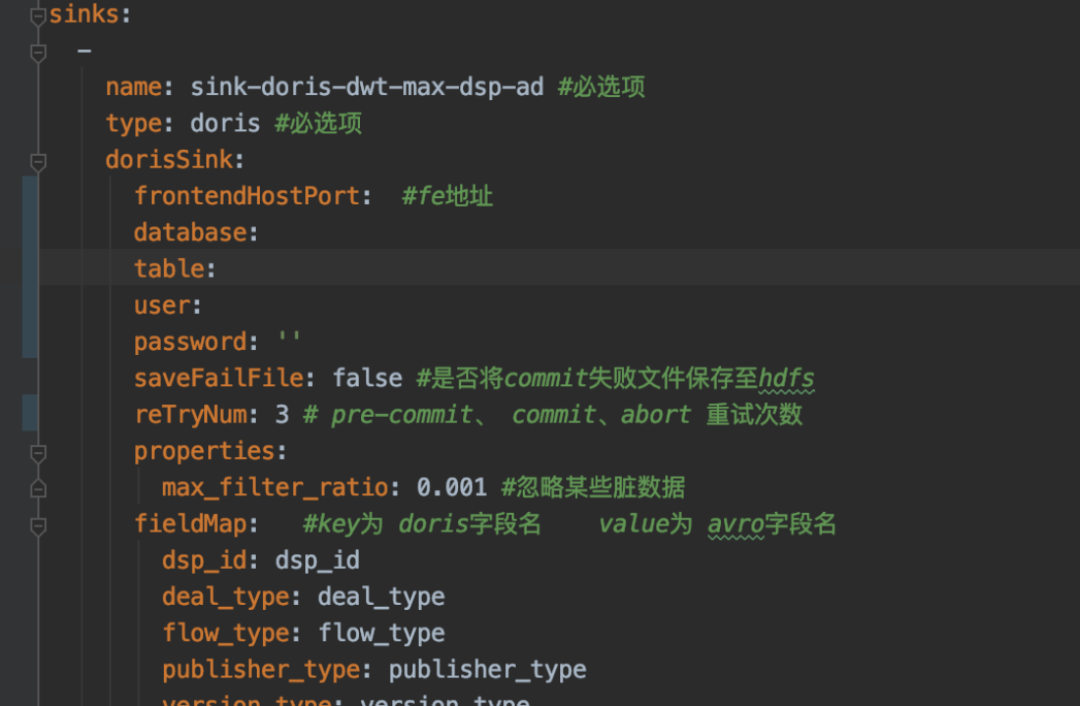
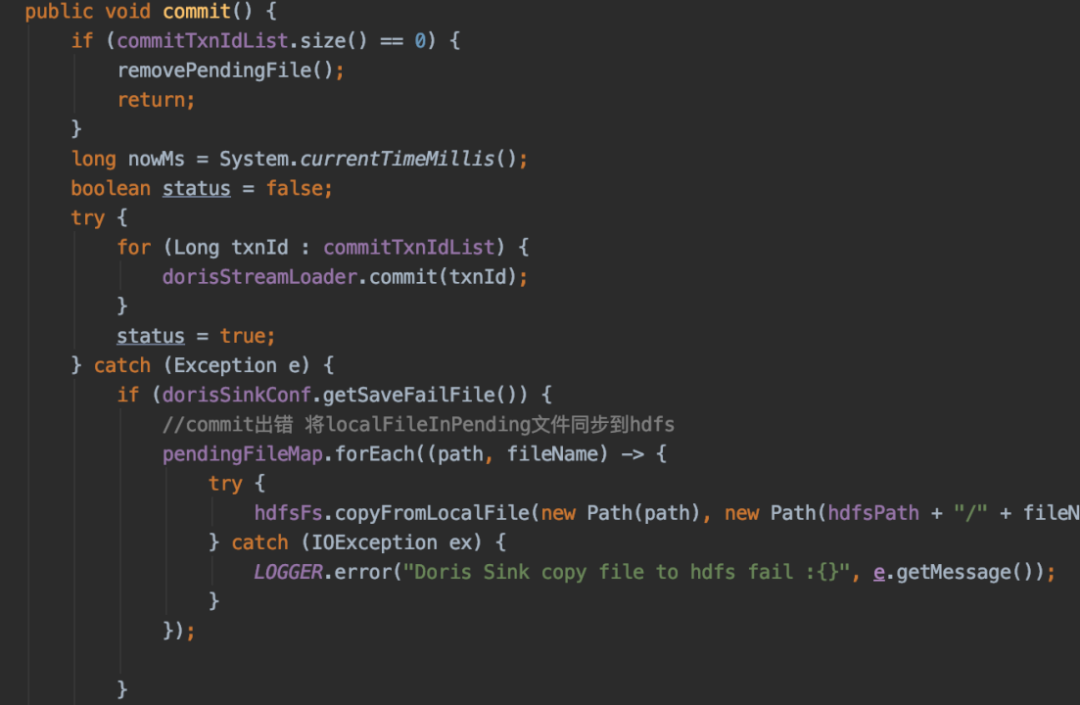
集群监控
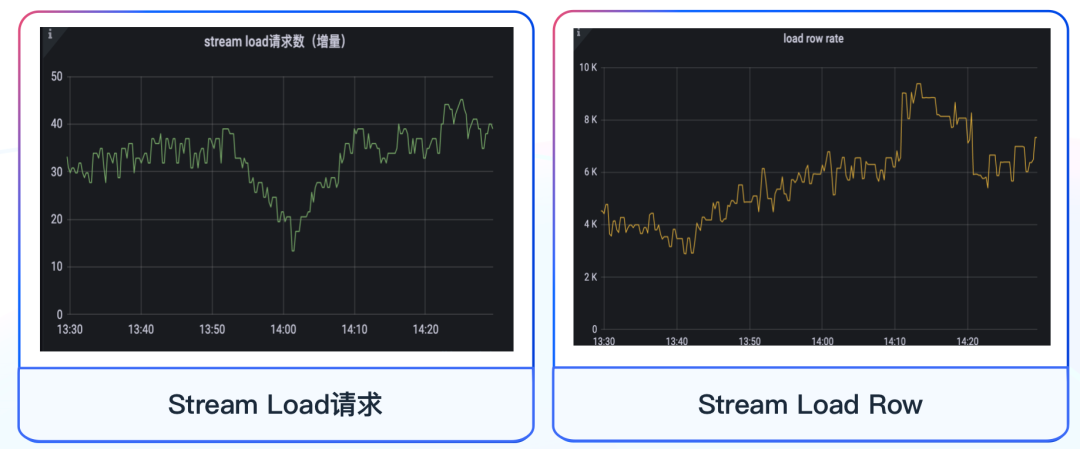
在集群监控层面,我们采用了社区提供的监控模板,从集群指标监控、主机指标监控、数据处理监控三个方面出发来搭建 Doris 监控体系。其中集群指标监控和主机指标监控主要根据社区监控说明文档进行监控,以便我们查看集群整体运行的情况。除社区提供的模板之外,我们还新增了有关 Stream Load 的监控指标,比如对当前 Stream Load 数量以及写入数据量的监控,如下图所示:
总结与规划
已有数十台集群机器,覆盖近 70% 的实时数据分析场景,实现了全量离线实验平台以及部分离线 DWS 层数据查询加速。当前日均新增数据规模可以达到百亿级别,在大部分实时场景中,其查询延迟在 1s 内
以上就是本次文章分享的内容,谢谢大家。










暂无评论内容