

“十万字段,没有一个注释,交接时你崩溃过吗?”
相信我,你不是一个人在战斗。写数据字典,这活儿又累又不讨好,但偏偏重要到不行。
上个月我们团队接手一个“祖传”数据库,15 张核心表,上千个字段,注释?几乎为零!光是理清字段含义就耗费了数周,项目进度直接告急。这不仅仅是时间成本,更是潜在的错误风险和合规噩梦。
用大语言模型 (LLM) 只要 5 步就能搞定数据字典
一、为什么“手写数据字典”不可能长久
手动维护数据字典,简直是数据团队的噩梦,主要痛点有三:
833 个工时

没有及时更新的数据字典,就是数据驱动路上的绊脚石。
二、核心原理:把元数据变成 Prompt
“把数据库的元数据 (information_schema) 提取出来,喂给大语言模型 (如 GPT-4),让它帮你输出字段注释、业务含义,甚至打上敏感数据标签。”
整个过程就像一个智能流水线:
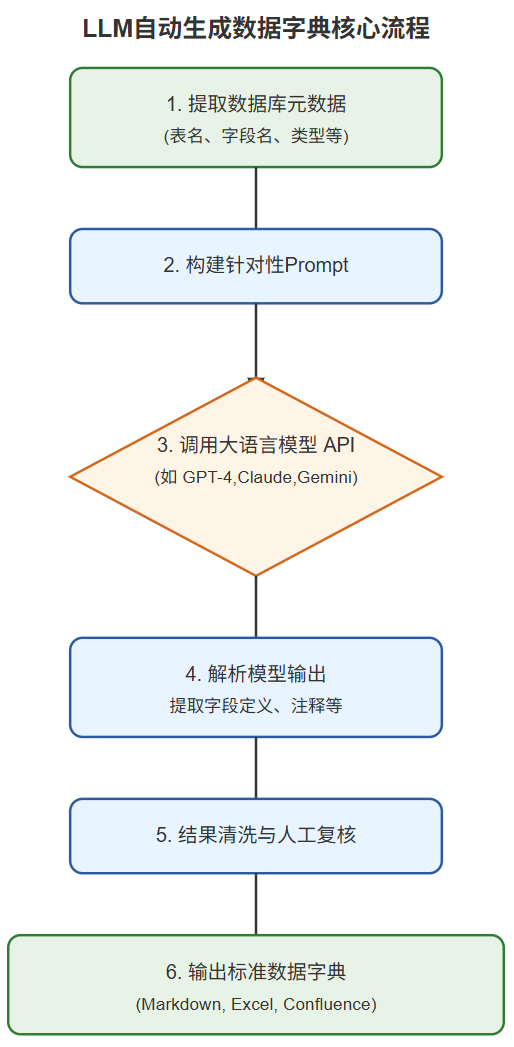
这个流程的核心在于高质量的元数据输入和精心设计的 Prompt。喂给模型的信息越准,产出的字典初稿就越靠谱。记住,我们不是要 AI 完全替代人,而是让它成为我们高效的“文档助理”。
三、实操 5 步:代码 + 讲解
Talk is cheap, show me the code! 接下来,我们将用 Python 和 SQLAlchemy 演示如何一步步实现。
第 1 步:提取 Schema 元数据
我们需要从数据库中拿到表结构信息。SQLAlchemy 是一个强大的 Python SQL 工具包,可以帮我们轻松搞定。
注:左滑可以看代码未显示部分
关键点
没有完备的元数据,巧妇也难为无米之炊。
第 2 步:构建 Prompt 模版
Prompt 的好坏直接影响 LLM 的输出质量。我们需要为生成表描述和列描述设计不同的模版。
表描述 Prompt 模版示例:
列描述 Prompt 模版示例:
核心要素
好的 Prompt,是与 LLM 高效对话的开始。
第 3 步:调用 GPT-4 (或其他 LLM)
这里以 OpenAI 的 Python SDK 为例。你需要先安装 openai 库并设置你的 API Key。
注意
选择合适的模型和参数,是平衡成本与效果的关键。
第 4 步:结果清洗 & 人工复核 Checklist
LLM 生成的是初稿,人工审核和校准是必不可少的环节,确保准确性和业务贴合度。
Checklist 供参考:
工具辅助
AI 不是银弹,人的智慧是最后一道质量防线。
第 5 步:输出 Markdown / Excel,接入 Confluence
审核完毕的数据字典,需要以便于查阅和维护的格式输出。
Python 输出 Markdown 示例 (简化版):
持续更新
让文档“活”起来,才能发挥最大价值。
四、完整案例:电商库 Customers & Orders
以一个简化的电商数据库为例,包含 Customers (客户表) 和 Orders (订单表)。

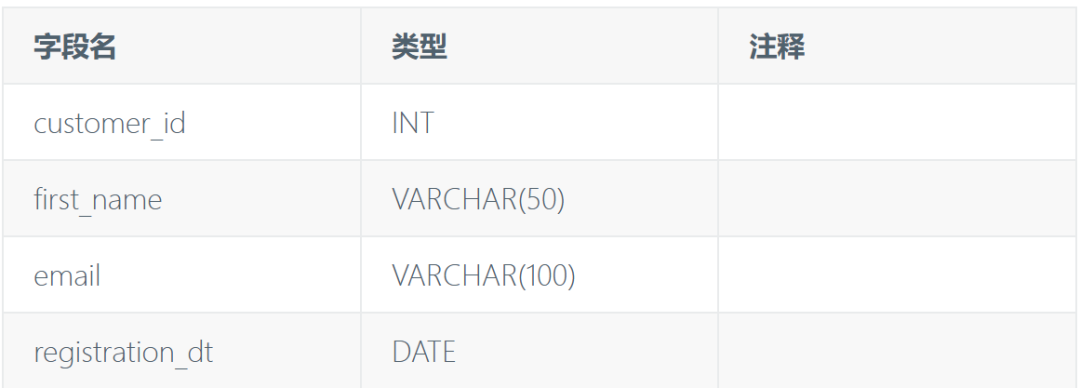
❌ 手写低效 (假设原始状态):
Customers 表 (部分字段)
✅ GPT 生成后 (经人工微调):
Customers 表 (部分字段)
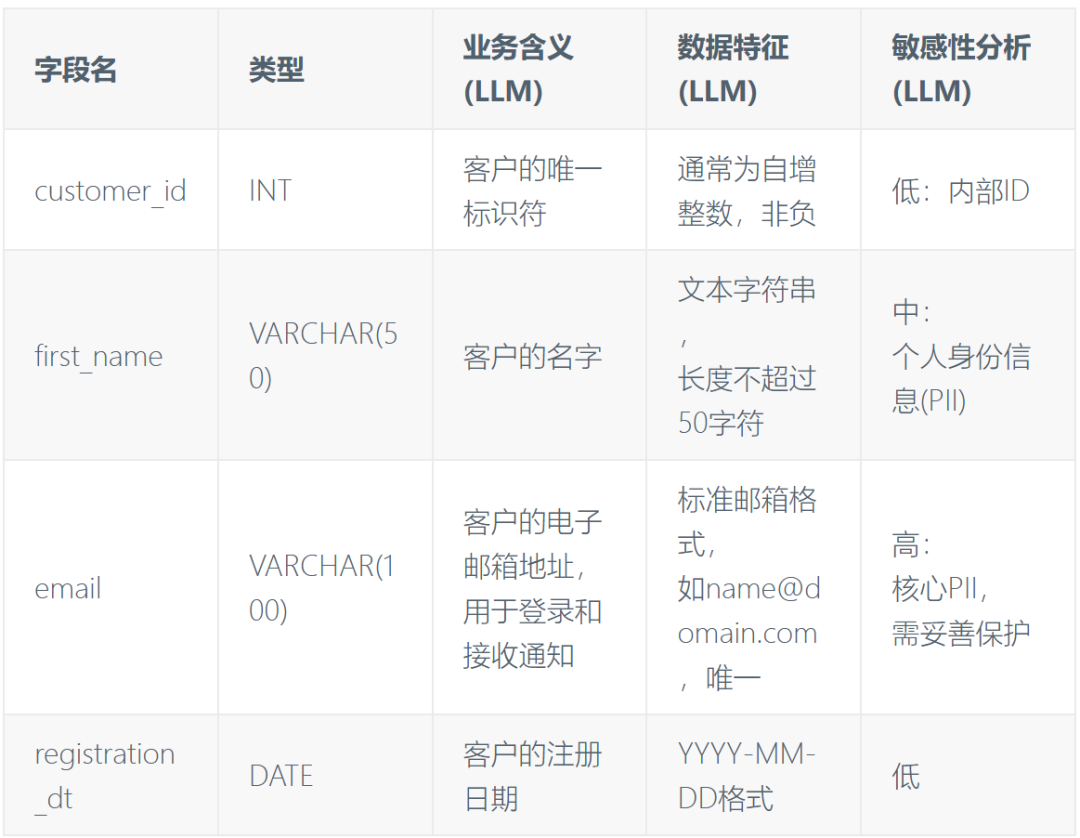
通过对比,可以明显看到 LLM 补齐了大量信息,并且进行了初步的敏感性分析,大大减轻了人工工作量。
五、注意事项 & 常踩坑
在享受 LLM 带来的便利时,也要注意以下几点:
没有银弹,只有不断优化的工程实践。
六、总结 & 下一步
利用大语言模型自动生成数据字典,无疑为数据团队带来了革命性的效率提升。它将我们从繁琐的体力劳动中解放出来,让我们更专注于理解数据背后的业务价值。
虽然 LLM 目前还不能完全替代人工,但它生成的初稿质量已经相当可观,尤其在处理大量字段的场景下,能够节省 90% 以上的时间和精力。
下一步,你可以:
“数据工程师写文档是浪费时间?——不,把时间花在写脚本让机器写文档,才叫工程师。”
希望这篇实战指南能为你打开一扇新的大门。如果你有任何疑问、经验分享,或者对文中提到的脚本感兴趣,欢迎在评论区留言讨论!觉得有用?别忘了点赞和转发给更多需要的小伙伴!






暂无评论内容